 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Planning Feedback for Open-Ended Programming Exercises with LLMs
Apr 11, 2025

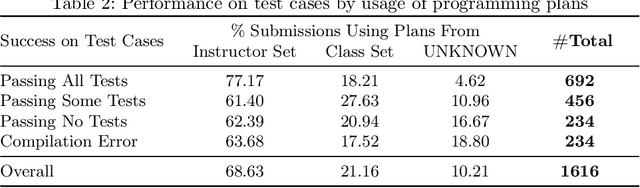
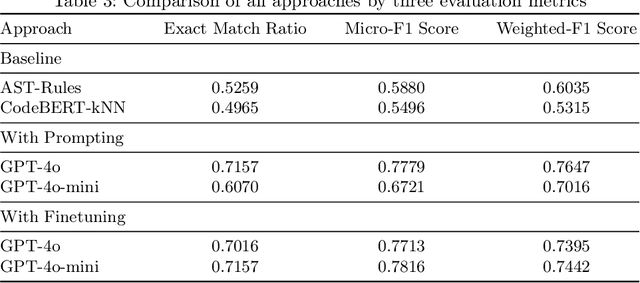
To complete an open-ended programming exercise, students need to both plan a high-level solution and implement it using the appropriate syntax. However, these problems are often autograded on the correctness of the final submission through test cases, and students cannot get feedback on their planning process. Large language models (LLM) may be able to generate this feedback by detecting the overall code structure even for submissions with syntax errors. To this end, we propose an approach that detects which high-level goals and patterns (i.e. programming plans) exist in a student program with LLMs. We show that both the full GPT-4o model and a small variant (GPT-4o-mini) can detect these plans with remarkable accuracy, outperforming baselines inspired by conventional approaches to code analysis. We further show that the smaller, cost-effective variant (GPT-4o-mini) achieves results on par with state-of-the-art (GPT-4o) after fine-tuning, creating promising implications for smaller models for real-time grading. These smaller models can be incorporated into autograders for open-ended code-writing exercises to provide feedback for students' implicit planning skills, even when their program is syntactically incorrect. Furthermore, LLMs may be useful in providing feedback for problems in other domains where students start with a set of high-level solution steps and iteratively compute the output, such as math and physics problems.