 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJudgmentBench: Comparing Rubric and Preference Evaluation for Quality Assessment
May 24, 2026Two methodologies dominate current practices of benchmarking: rubric-based scoring evaluates items against predefined criteria, whereas comparative judgment elicits pairwise preferences between outputs. Although both methodologies are widely used, the choice between them is rarely justified. We release JudgmentBench, a benchmark of 30 real-world legal tasks, paired with 1,539 rubric scores and 1,530 pairwise preference judgments collected from practicing attorneys--including at major U.S. law firms--with substantial experience. The annotations constitute the first publicly available dataset in a high-expertise domain in which both supervision signals are elicited from the same experts on the same items. Using LLM-generated outputs at three constructed quality levels, we provide an initial empirical comparison: comparative judgments recover the intended quality ordering substantially better than rubrics (mean Spearman's rank correlation of 0.908 vs. 0.150, estimated difference = 0.758 [0.494, 1.021]) while requiring less than half the annotation time. The patterns hold for human annotators and LLM autograders. Beyond this initial comparison, the paired structure of the dataset supports a broader research agenda on how expert judgment should be elicited, aggregated, and used as supervision in domains without verifiable ground truth.
Towards Robust Legal Reasoning: Harnessing Logical LLMs in Law
Feb 24, 2025Legal services rely heavily on text processing. While large language models (LLMs) show promise, their application in legal contexts demands higher accuracy, repeatability, and transparency. Logic programs, by encoding legal concepts as structured rules and facts, offer reliable automation, but require sophisticated text extraction. We propose a neuro-symbolic approach that integrates LLMs' natural language understanding with logic-based reasoning to address these limitations. As a legal document case study, we applied neuro-symbolic AI to coverage-related queries in insurance contracts using both closed and open-source LLMs. While LLMs have improved in legal reasoning, they still lack the accuracy and consistency required for complex contract analysis. In our analysis, we tested three methodologies to evaluate whether a specific claim is covered under a contract: a vanilla LLM, an unguided approach that leverages LLMs to encode both the contract and the claim, and a guided approach that uses a framework for the LLM to encode the contract. We demonstrated the promising capabilities of LLM + Logic in the guided approach.
Equitable Access to Justice: Logical LLMs Show Promise
Oct 13, 2024

The costs and complexity of the American judicial system limit access to legal solutions for many Americans. Large language models (LLMs) hold great potential to improve access to justice. However, a major challenge in applying AI and LLMs in legal contexts, where consistency and reliability are crucial, is the need for System 2 reasoning. In this paper, we explore the integration of LLMs with logic programming to enhance their ability to reason, bringing their strategic capabilities closer to that of a skilled lawyer. Our objective is to translate laws and contracts into logic programs that can be applied to specific legal cases, with a focus on insurance contracts. We demonstrate that while GPT-4o fails to encode a simple health insurance contract into logical code, the recently released OpenAI o1-preview model succeeds, exemplifying how LLMs with advanced System 2 reasoning capabilities can expand access to justice.
LegalBench: A Collaboratively Built Benchmark for Measuring Legal Reasoning in Large Language Models
Aug 20, 2023
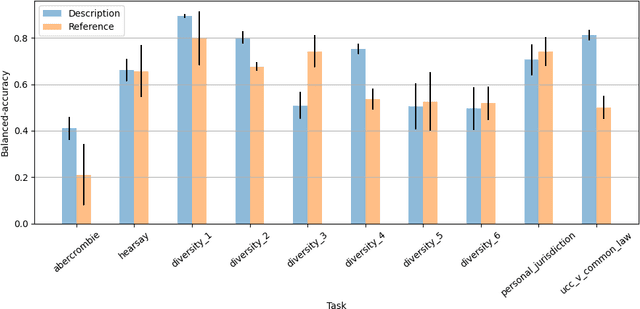
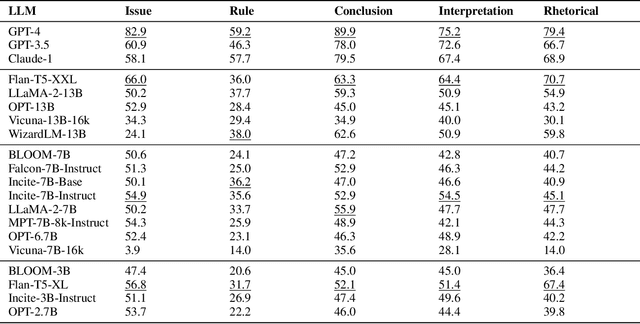
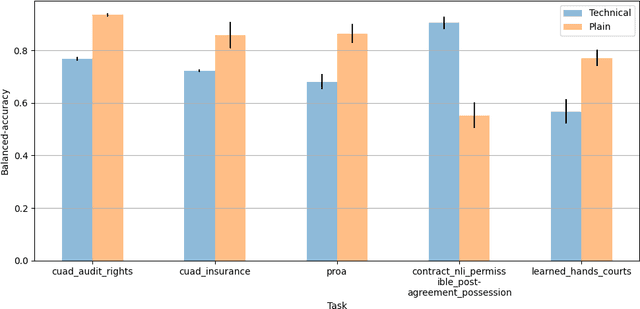
The advent of large language models (LLMs) and their adoption by the legal community has given rise to the question: what types of legal reasoning can LLMs perform? To enable greater study of this question, we present LegalBench: a collaboratively constructed legal reasoning benchmark consisting of 162 tasks covering six different types of legal reasoning. LegalBench was built through an interdisciplinary process, in which we collected tasks designed and hand-crafted by legal professionals. Because these subject matter experts took a leading role in construction, tasks either measure legal reasoning capabilities that are practically useful, or measure reasoning skills that lawyers find interesting. To enable cross-disciplinary conversations about LLMs in the law, we additionally show how popular legal frameworks for describing legal reasoning -- which distinguish between its many forms -- correspond to LegalBench tasks, thus giving lawyers and LLM developers a common vocabulary. This paper describes LegalBench, presents an empirical evaluation of 20 open-source and commercial LLMs, and illustrates the types of research explorations LegalBench enables.
The Legislative Recipe: Syntax for Machine-Readable Legislation
Aug 19, 2021Legal interpretation is a linguistic venture. In judicial opinions, for example, courts are often asked to interpret the text of statutes and legislation. As time has shown, this is not always as easy as it sounds. Matters can hinge on vague or inconsistent language and, under the surface, human biases can impact the decision-making of judges. This raises an important question: what if there was a method of extracting the meaning of statutes consistently? That is, what if it were possible to use machines to encode legislation in a mathematically precise form that would permit clearer responses to legal questions? This article attempts to unpack the notion of machine-readability, providing an overview of both its historical and recent developments. The paper will reflect on logic syntax and symbolic language to assess the capacity and limits of representing legal knowledge. In doing so, the paper seeks to move beyond existing literature to discuss the implications of various approaches to machine-readable legislation. Importantly, this study hopes to highlight the challenges encountered in this burgeoning ecosystem of machine-readable legislation against existing human-readable counterparts.