 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Robust Legal Reasoning: Harnessing Logical LLMs in Law
Feb 24, 2025Legal services rely heavily on text processing. While large language models (LLMs) show promise, their application in legal contexts demands higher accuracy, repeatability, and transparency. Logic programs, by encoding legal concepts as structured rules and facts, offer reliable automation, but require sophisticated text extraction. We propose a neuro-symbolic approach that integrates LLMs' natural language understanding with logic-based reasoning to address these limitations. As a legal document case study, we applied neuro-symbolic AI to coverage-related queries in insurance contracts using both closed and open-source LLMs. While LLMs have improved in legal reasoning, they still lack the accuracy and consistency required for complex contract analysis. In our analysis, we tested three methodologies to evaluate whether a specific claim is covered under a contract: a vanilla LLM, an unguided approach that leverages LLMs to encode both the contract and the claim, and a guided approach that uses a framework for the LLM to encode the contract. We demonstrated the promising capabilities of LLM + Logic in the guided approach.
Equitable Access to Justice: Logical LLMs Show Promise
Oct 13, 2024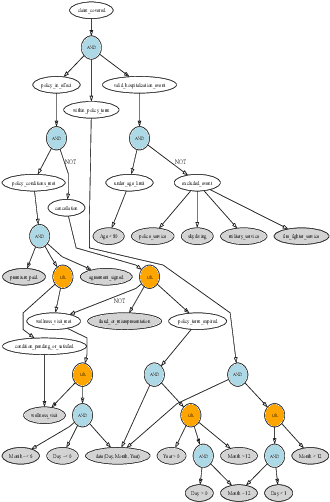

The costs and complexity of the American judicial system limit access to legal solutions for many Americans. Large language models (LLMs) hold great potential to improve access to justice. However, a major challenge in applying AI and LLMs in legal contexts, where consistency and reliability are crucial, is the need for System 2 reasoning. In this paper, we explore the integration of LLMs with logic programming to enhance their ability to reason, bringing their strategic capabilities closer to that of a skilled lawyer. Our objective is to translate laws and contracts into logic programs that can be applied to specific legal cases, with a focus on insurance contracts. We demonstrate that while GPT-4o fails to encode a simple health insurance contract into logical code, the recently released OpenAI o1-preview model succeeds, exemplifying how LLMs with advanced System 2 reasoning capabilities can expand access to justice.
Identifiability of Product of Experts Models
Oct 13, 2023Product of experts (PoE) are layered networks in which the value at each node is an AND (or product) of the values (possibly negated) at its inputs. These were introduced as a neural network architecture that can efficiently learn to generate high-dimensional data which satisfy many low-dimensional constraints -- thereby allowing each individual expert to perform a simple task. PoEs have found a variety of applications in learning. We study the problem of identifiability of a product of experts model having a layer of binary latent variables, and a layer of binary observables that are iid conditional on the latents. The previous best upper bound on the number of observables needed to identify the model was exponential in the number of parameters. We show: (a) When the latents are uniformly distributed, the model is identifiable with a number of observables equal to the number of parameters (and hence best possible). (b) In the more general case of arbitrarily distributed latents, the model is identifiable for a number of observables that is still linear in the number of parameters (and within a factor of two of best-possible). The proofs rely on root interlacing phenomena for some special three-term recurrences.