 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Review of Large Language Models and Autonomous Agents in Chemistry
Jun 26, 2024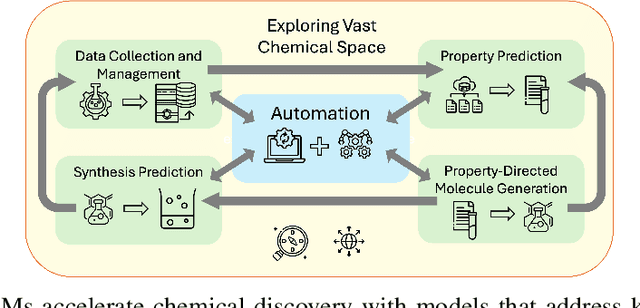

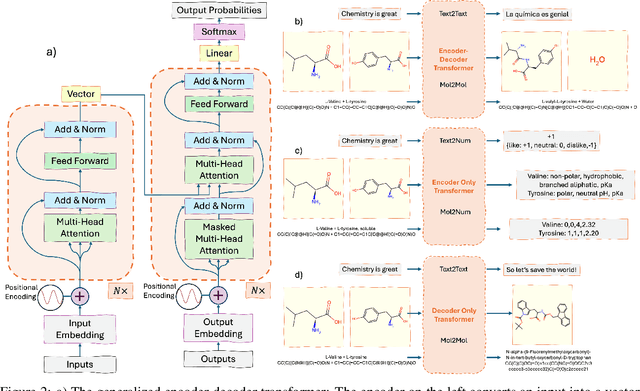
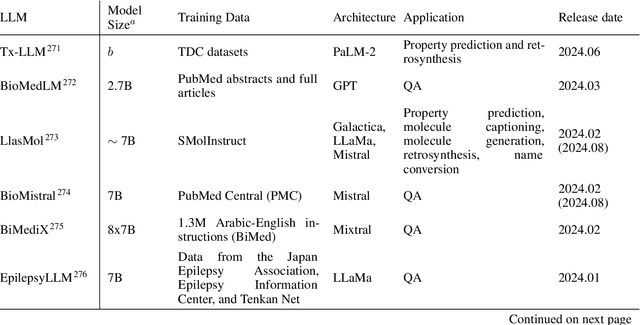
Large language models (LLMs) are emerging as a powerful tool in chemistry across multiple domains. In chemistry, LLMs are able to accurately predict properties, design new molecules, optimize synthesis pathways, and accelerate drug and material discovery. A core emerging idea is combining LLMs with chemistry-specific tools like synthesis planners and databases, leading to so-called "agents." This review covers LLMs' recent history, current capabilities, design, challenges specific to chemistry, and future directions. Particular attention is given to agents and their emergence as a cross-chemistry paradigm. Agents have proven effective in diverse domains of chemistry, but challenges remain. It is unclear if creating domain-specific versus generalist agents and developing autonomous pipelines versus "co-pilot" systems will accelerate chemistry. An emerging direction is the development of multi-agent systems using a human-in-the-loop approach. Due to the incredibly fast development of this field, a repository has been built to keep track of the latest studies: https://github.com/ur-whitelab/LLMs-in-science.
Predicting small molecules solubilities on endpoint devices using deep ensemble neural networks
Jul 11, 2023

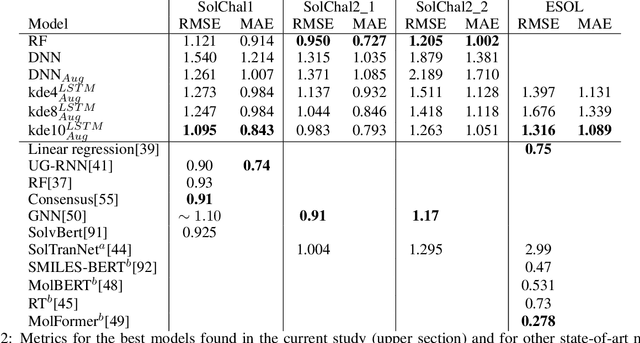

Aqueous solubility is a valuable yet challenging property to predict. Computing solubility using first-principles methods requires accounting for the competing effects of entropy and enthalpy, resulting in long computations for relatively poor accuracy. Data-driven approaches, such as deep learning, offer improved accuracy and computational efficiency but typically lack uncertainty quantification. Additionally, ease of use remains a concern for any computational technique, resulting in the sustained popularity of group-based contribution methods. In this work, we addressed these problems with a deep learning model with predictive uncertainty that runs on a static website (without a server). This approach moves computing needs onto the website visitor without requiring installation, removing the need to pay for and maintain servers. Our model achieves satisfactory results in solubility prediction. Furthermore, we demonstrate how to create molecular property prediction models that balance uncertainty and ease of use. The code is available at \url{https://github.com/ur-whitelab/mol.dev}, and the model is usable at \url{https://mol.dev}.
14 Examples of How LLMs Can Transform Materials Science and Chemistry: A Reflection on a Large Language Model Hackathon
Jun 13, 2023



Chemistry and materials science are complex. Recently, there have been great successes in addressing this complexity using data-driven or computational techniques. Yet, the necessity of input structured in very specific forms and the fact that there is an ever-growing number of tools creates usability and accessibility challenges. Coupled with the reality that much data in these disciplines is unstructured, the effectiveness of these tools is limited. Motivated by recent works that indicated that large language models (LLMs) might help address some of these issues, we organized a hackathon event on the applications of LLMs in chemistry, materials science, and beyond. This article chronicles the projects built as part of this hackathon. Participants employed LLMs for various applications, including predicting properties of molecules and materials, designing novel interfaces for tools, extracting knowledge from unstructured data, and developing new educational applications. The diverse topics and the fact that working prototypes could be generated in less than two days highlight that LLMs will profoundly impact the future of our fields. The rich collection of ideas and projects also indicates that the applications of LLMs are not limited to materials science and chemistry but offer potential benefits to a wide range of scientific disciplines.
Bayesian Optimization of Catalysts With In-context Learning
Apr 11, 2023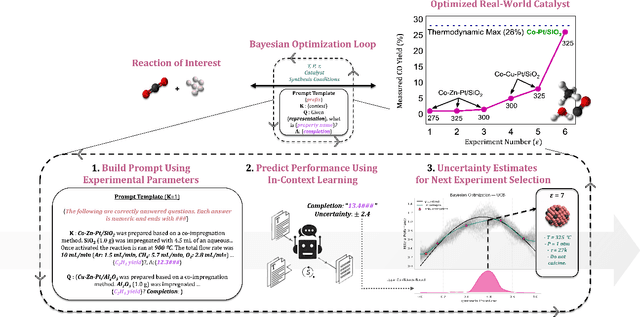
Large language models (LLMs) are able to do accurate classification with zero or only a few examples (in-context learning). We show a prompting system that enables regression with uncertainty for in-context learning with frozen LLM (GPT-3, GPT-3.5, and GPT-4) models, allowing predictions without features or architecture tuning. By incorporating uncertainty, our approach enables Bayesian optimization for catalyst or molecule optimization using natural language, eliminating the need for training or simulation. Here, we performed the optimization using the synthesis procedure of catalysts to predict properties. Working with natural language mitigates difficulty synthesizability since the literal synthesis procedure is the model's input. We showed that in-context learning could improve past a model context window (maximum number of tokens the model can process at once) as data is gathered via example selection, allowing the model to scale better. Although our method does not outperform all baselines, it requires zero training, feature selection, and minimal computing while maintaining satisfactory performance. We also find Gaussian Process Regression on text embeddings is strong at Bayesian optimization. The code is available in our GitHub repository: https://github.com/ur-whitelab/BO-LIFT