 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimisation of the Accelerator Control by Reinforcement Learning: A Simulation-Based Approach
Mar 12, 2025Optimizing accelerator control is a critical challenge in experimental particle physics, requiring significant manual effort and resource expenditure. Traditional tuning methods are often time-consuming and reliant on expert input, highlighting the need for more efficient approaches. This study aims to create a simulation-based framework integrated with Reinforcement Learning (RL) to address these challenges. Using \texttt{Elegant} as the simulation backend, we developed a Python wrapper that simplifies the interaction between RL algorithms and accelerator simulations, enabling seamless input management, simulation execution, and output analysis. The proposed RL framework acts as a co-pilot for physicists, offering intelligent suggestions to enhance beamline performance, reduce tuning time, and improve operational efficiency. As a proof of concept, we demonstrate the application of our RL approach to an accelerator control problem and highlight the improvements in efficiency and performance achieved through our methodology. We discuss how the integration of simulation tools with a Python-based RL framework provides a powerful resource for the accelerator physics community, showcasing the potential of machine learning in optimizing complex physical systems.
Variance Reduction for Policy-Gradient Methods via Empirical Variance Minimization
Jun 15, 2022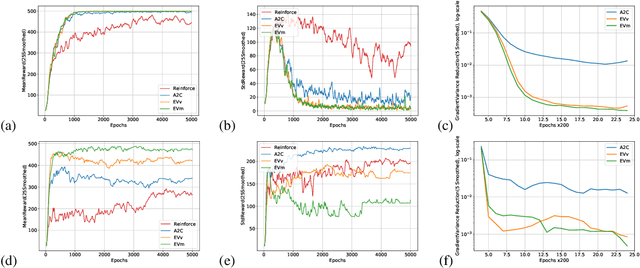

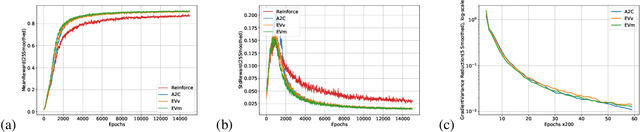
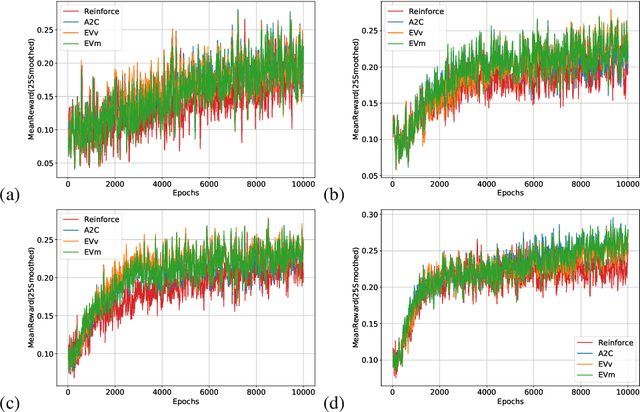
Policy-gradient methods in Reinforcement Learning(RL) are very universal and widely applied in practice but their performance suffers from the high variance of the gradient estimate. Several procedures were proposed to reduce it including actor-critic(AC) and advantage actor-critic(A2C) methods. Recently the approaches have got new perspective due to the introduction of Deep RL: both new control variates(CV) and new sub-sampling procedures became available in the setting of complex models like neural networks. The vital part of CV-based methods is the goal functional for the training of the CV, the most popular one is the least-squares criterion of A2C. Despite its practical success, the criterion is not the only one possible. In this paper we for the first time investigate the performance of the one called Empirical Variance(EV). We observe in the experiments that not only EV-criterion performs not worse than A2C but sometimes can be considerably better. Apart from that, we also prove some theoretical guarantees of the actual variance reduction under very general assumptions and show that A2C least-squares goal functional is an upper bound for EV goal. Our experiments indicate that in terms of variance reduction EV-based methods are much better than A2C and allow stronger variance reduction.
Finite Time Analysis of Linear Two-timescale Stochastic Approximation with Markovian Noise
Feb 04, 2020
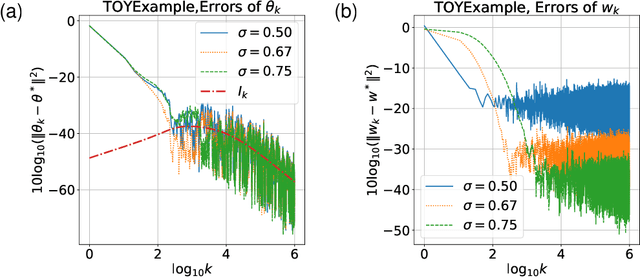
Linear two-timescale stochastic approximation (SA) scheme is an important class of algorithms which has become popular in reinforcement learning (RL), particularly for the policy evaluation problem. Recently, a number of works have been devoted to establishing the finite time analysis of the scheme, especially under the Markovian (non-i.i.d.) noise settings that are ubiquitous in practice. In this paper, we provide a finite-time analysis for linear two timescale SA. Our bounds show that there is no discrepancy in the convergence rate between Markovian and martingale noise, only the constants are affected by the mixing time of the Markov chain. With an appropriate step size schedule, the transient term in the expected error bound is $o(1/k^c)$ and the steady-state term is ${\cal O}(1/k)$, where $c>1$ and $k$ is the iteration number. Furthermore, we present an asymptotic expansion of the expected error with a matching lower bound of $\Omega(1/k)$. A simple numerical experiment is presented to support our theory.