 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSWE-rebench: An Automated Pipeline for Task Collection and Decontaminated Evaluation of Software Engineering Agents
May 26, 2025LLM-based agents have shown promising capabilities in a growing range of software engineering (SWE) tasks. However, advancing this field faces two critical challenges. First, high-quality training data is scarce, especially data that reflects real-world SWE scenarios, where agents must interact with development environments, execute code and adapt behavior based on the outcomes of their actions. Existing datasets are either limited to one-shot code generation or comprise small, manually curated collections of interactive tasks, lacking both scale and diversity. Second, the lack of fresh interactive SWE tasks affects evaluation of rapidly improving models, as static benchmarks quickly become outdated due to contamination issues. To address these limitations, we introduce a novel, automated, and scalable pipeline to continuously extract real-world interactive SWE tasks from diverse GitHub repositories. Using this pipeline, we construct SWE-rebench, a public dataset comprising over 21,000 interactive Python-based SWE tasks, suitable for reinforcement learning of SWE agents at scale. Additionally, we use continuous supply of fresh tasks collected using SWE-rebench methodology to build a contamination-free benchmark for agentic software engineering. We compare results of various LLMs on this benchmark to results on SWE-bench Verified and show that performance of some language models might be inflated due to contamination issues.
Guided Search Strategies in Non-Serializable Environments with Applications to Software Engineering Agents
May 19, 2025Large language models (LLMs) have recently achieved remarkable results in complex multi-step tasks, such as mathematical reasoning and agentic software engineering. However, they often struggle to maintain consistent performance across multiple solution attempts. One effective approach to narrow the gap between average-case and best-case performance is guided test-time search, which explores multiple solution paths to identify the most promising one. Unfortunately, effective search techniques (e.g. MCTS) are often unsuitable for non-serializable RL environments, such as Docker containers, where intermediate environment states cannot be easily saved and restored. We investigate two complementary search strategies applicable to such environments: 1-step lookahead and trajectory selection, both guided by a learned action-value function estimator. On the SWE-bench Verified benchmark, a key testbed for agentic software engineering, we find these methods to double the average success rate of a fine-tuned Qwen-72B model, achieving 40.8%, the new state-of-the-art for open-weights models. Additionally, we show that these techniques are transferable to more advanced closed models, yielding similar improvements with GPT-4o.
Variance Reduction for Policy-Gradient Methods via Empirical Variance Minimization
Jun 15, 2022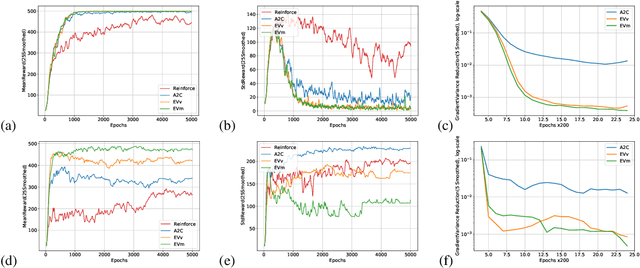

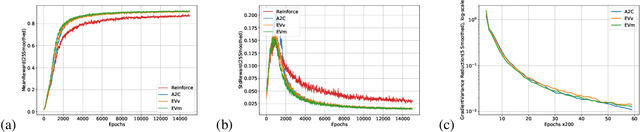
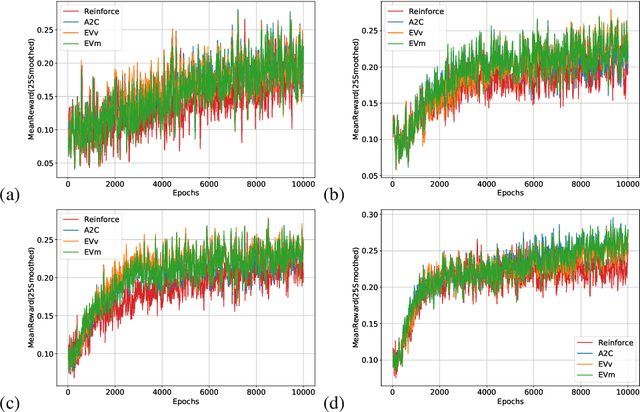
Policy-gradient methods in Reinforcement Learning(RL) are very universal and widely applied in practice but their performance suffers from the high variance of the gradient estimate. Several procedures were proposed to reduce it including actor-critic(AC) and advantage actor-critic(A2C) methods. Recently the approaches have got new perspective due to the introduction of Deep RL: both new control variates(CV) and new sub-sampling procedures became available in the setting of complex models like neural networks. The vital part of CV-based methods is the goal functional for the training of the CV, the most popular one is the least-squares criterion of A2C. Despite its practical success, the criterion is not the only one possible. In this paper we for the first time investigate the performance of the one called Empirical Variance(EV). We observe in the experiments that not only EV-criterion performs not worse than A2C but sometimes can be considerably better. Apart from that, we also prove some theoretical guarantees of the actual variance reduction under very general assumptions and show that A2C least-squares goal functional is an upper bound for EV goal. Our experiments indicate that in terms of variance reduction EV-based methods are much better than A2C and allow stronger variance reduction.