 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafer Together: Machine Learning Models Trained on Shared Accident Datasets Predict Construction Injuries Better than Company-Specific Models
Jan 09, 2023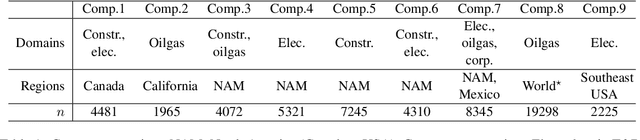
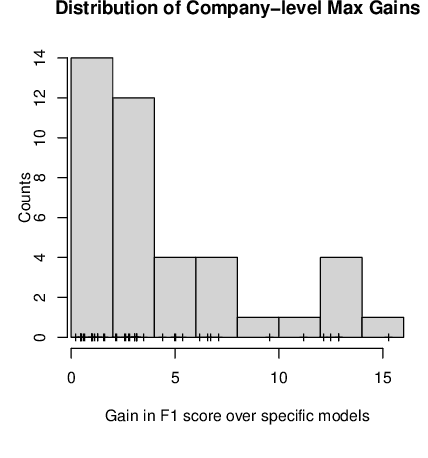
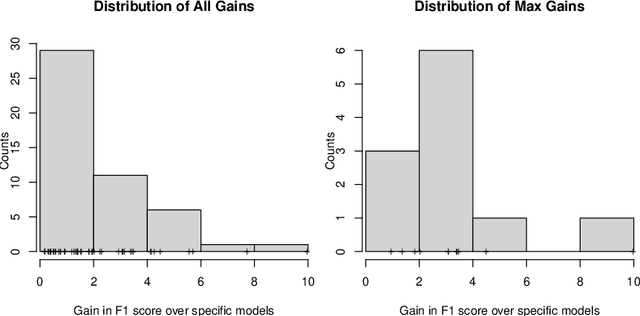
In this study, we capitalized on a collective dataset repository of 57k accidents from 9 companies belonging to 3 domains and tested whether models trained on multiple datasets (generic models) predicted safety outcomes better than the company-specific models. We experimented with full generic models (trained on all data), per-domain generic models (construction, electric T&D, oil & gas), and with ensembles of generic and specific models. Results are very positive, with generic models outperforming the company-specific models in most cases while also generating finer-grained, hence more useful, forecasts. Successful generic models remove the needs for training company-specific models, saving a lot of time and resources, and give small companies, whose accident datasets are too limited to train their own models, access to safety outcome predictions. It may still however be advantageous to train specific models to get an extra boost in performance through ensembling with the generic models. Overall, by learning lessons from a pool of datasets whose accumulated experience far exceeds that of any single company, and making these lessons easily accessible in the form of simple forecasts, generic models tackle the holy grail of safety cross-organizational learning and dissemination in the construction industry.
AI Predicts Independent Construction Safety Outcomes from Universal Attributes
Aug 16, 2019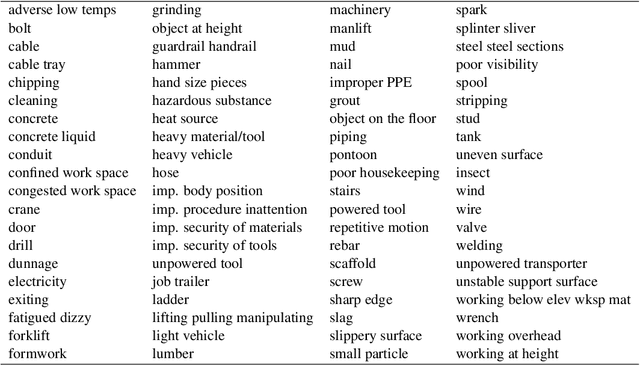
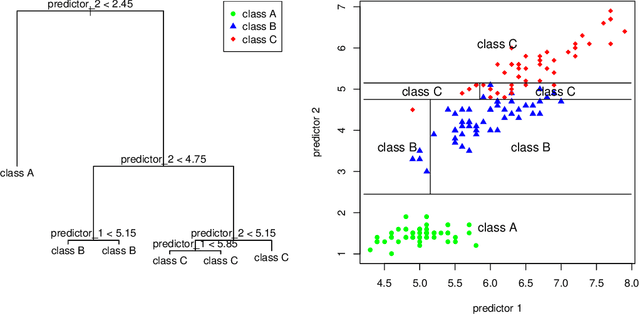
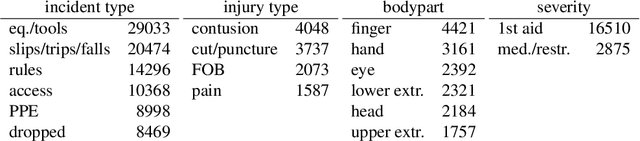
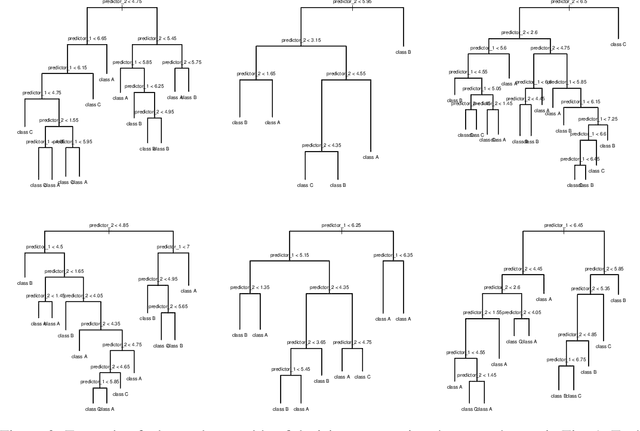
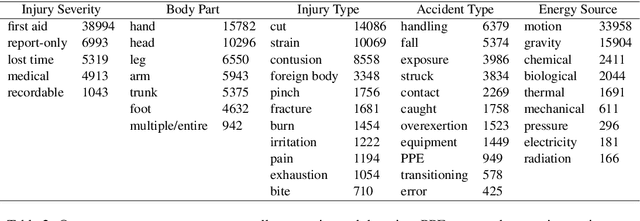
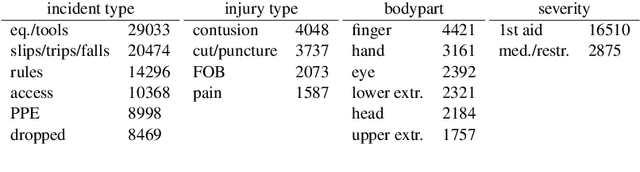
This paper significantly improves on, and finishes to validate, the approach proposed in "Application of Machine Learning to Construction Injury Prediction" (Tixier et al. 2016 [1]). Like in the original study, we use NLP to extract fundamental attributes from raw incident reports and machine learning models are trained to predict safety outcomes (here, these outcomes are injury severity, injury type, bodypart impacted, and incident type). However, in this study, safety outcomes were not extracted via NLP but are independent (human annotations), eliminating any potential source of artificial correlation between predictors and predictands. Results show that attributes are still highly predictive, confirming the validity of the original study. Other improvements brought by the current study include the use of (1) a much larger dataset, (2) two new models (XGBoost andlinear SVM), (3) model stacking, (4) a more straight forward experimental setup with more appropriate performance metrics, and (5) an analysis of per-category attribute importance scores. Finally, the injury severity outcome is well predicted, which was not the case in the original study. This is a significant advancement.
Automatically Learning Construction Injury Precursors from Text
Jul 26, 2019
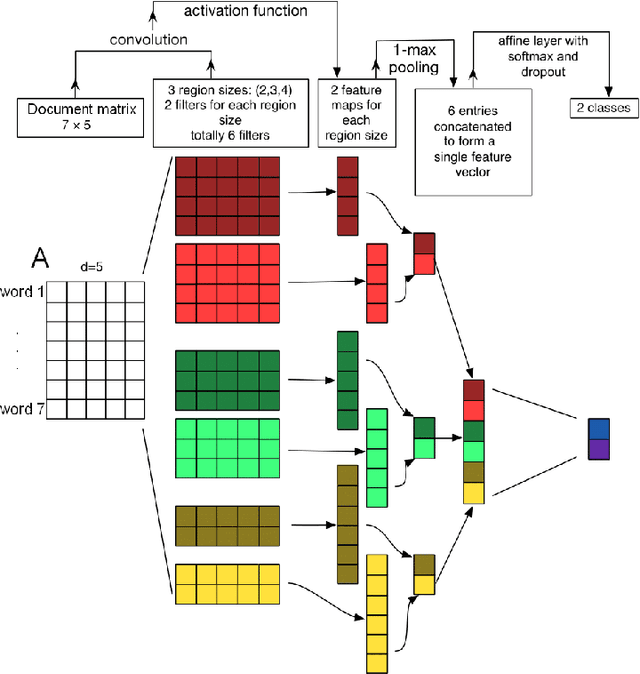
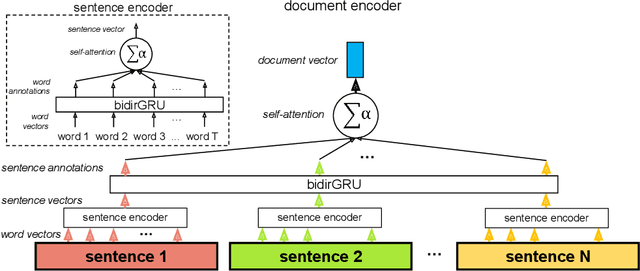
In light of the increasing availability of digitally recorded safety reports in the construction industry, it is important to develop methods to exploit these data to improve our understanding of safety incidents and ability to learn from them. In this study, we compare several approaches to automatically learn injury precursors from raw construction accident reports. More precisely, we experiment with two state-of-the-art deep learning architectures for Natural Language Processing (NLP), Convolutional Neural Networks (CNN) and Hierarchical Attention Networks (HAN), and with the established Term Frequency - Inverse Document Frequency representation (TF-IDF) + Support Vector Machine (SVM) approach. For each model, we provide a method to identify (after training) the textual patterns that are, on average, the most predictive of each safety outcome. We show that among those pieces of text, valid injury precursors can be found. The proposed methods can also be used by the user to visualize and understand the models' predictions.
Word Embeddings for the Construction Domain
Oct 28, 2016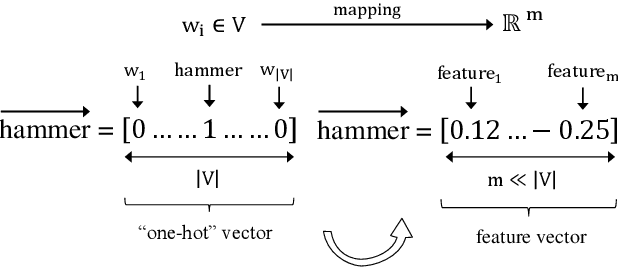


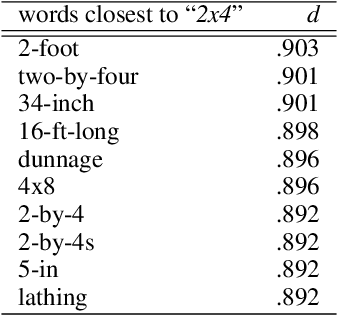
We introduce word vectors for the construction domain. Our vectors were obtained by running word2vec on an 11M-word corpus that we created from scratch by leveraging freely-accessible online sources of construction-related text. We first explore the embedding space and show that our vectors capture meaningful construction-specific concepts. We then evaluate the performance of our vectors against that of ones trained on a 100B-word corpus (Google News) within the framework of an injury report classification task. Without any parameter tuning, our embeddings give competitive results, and outperform the Google News vectors in many cases. Using a keyword-based compression of the reports also leads to a significant speed-up with only a limited loss in performance. We release our corpus and the data set we created for the classification task as publicly available, in the hope that they will be used by future studies for benchmarking and building on our work.
Construction Safety Risk Modeling and Simulation
Sep 26, 2016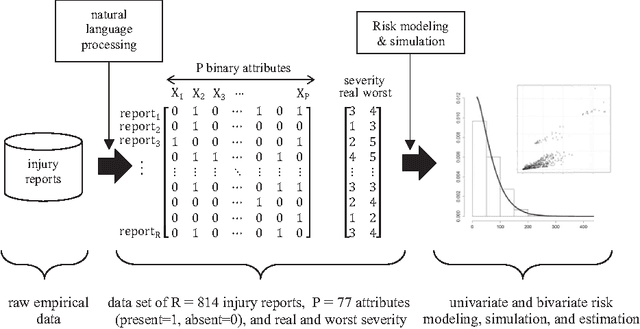
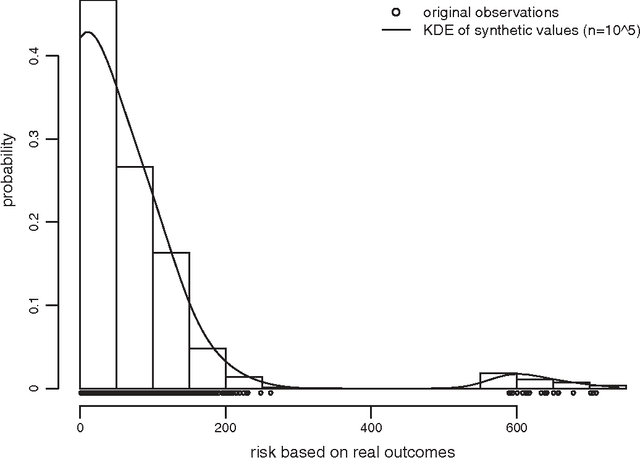
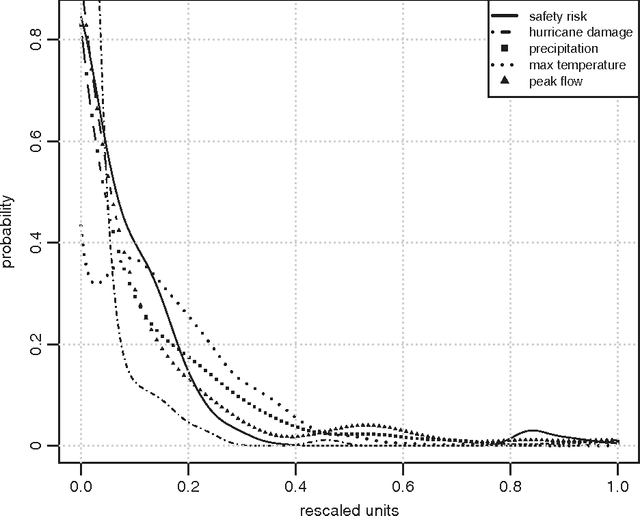
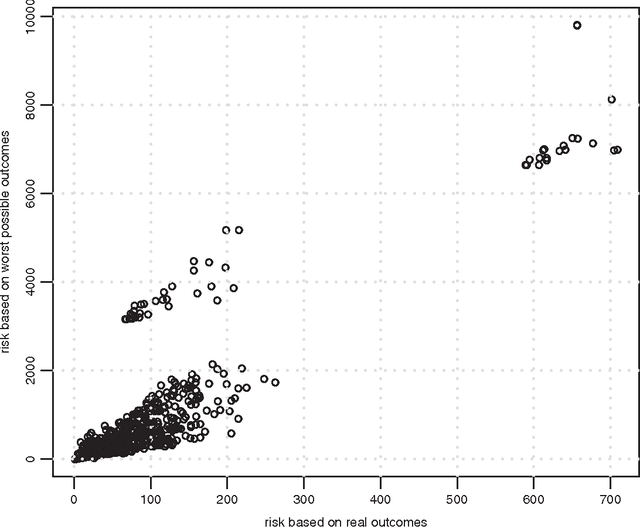
By building on a recently introduced genetic-inspired attribute-based conceptual framework for safety risk analysis, we propose a novel methodology to compute construction univariate and bivariate construction safety risk at a situational level. Our fully data-driven approach provides construction practitioners and academicians with an easy and automated way of extracting valuable empirical insights from databases of unstructured textual injury reports. By applying our methodology on an attribute and outcome dataset directly obtained from 814 injury reports, we show that the frequency-magnitude distribution of construction safety risk is very similar to that of natural phenomena such as precipitation or earthquakes. Motivated by this observation, and drawing on state-of-the-art techniques in hydroclimatology and insurance, we introduce univariate and bivariate nonparametric stochastic safety risk generators, based on Kernel Density Estimators and Copulas. These generators enable the user to produce large numbers of synthetic safety risk values faithfully to the original data, allowing safetyrelated decision-making under uncertainty to be grounded on extensive empirical evidence. Just like the accurate modeling and simulation of natural phenomena such as wind or streamflow is indispensable to successful structure dimensioning or water reservoir management, we posit that improving construction safety calls for the accurate modeling, simulation, and assessment of safety risk. The underlying assumption is that like natural phenomena, construction safety may benefit from being studied in an empirical and quantitative way rather than qualitatively which is the current industry standard. Finally, a side but interesting finding is that attributes related to high energy levels and to human error emerge as strong risk shapers on the dataset we used to illustrate our methodology.