 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWord Embeddings for the Construction Domain
Paper and Code
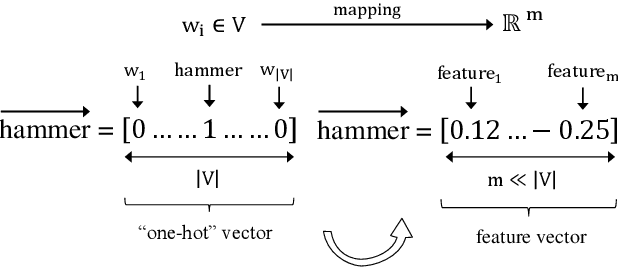


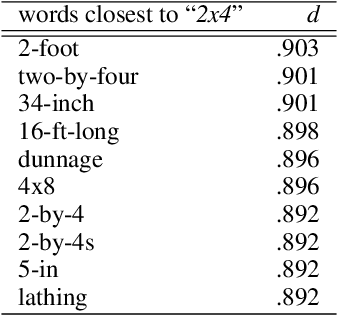
We introduce word vectors for the construction domain. Our vectors were obtained by running word2vec on an 11M-word corpus that we created from scratch by leveraging freely-accessible online sources of construction-related text. We first explore the embedding space and show that our vectors capture meaningful construction-specific concepts. We then evaluate the performance of our vectors against that of ones trained on a 100B-word corpus (Google News) within the framework of an injury report classification task. Without any parameter tuning, our embeddings give competitive results, and outperform the Google News vectors in many cases. Using a keyword-based compression of the reports also leads to a significant speed-up with only a limited loss in performance. We release our corpus and the data set we created for the classification task as publicly available, in the hope that they will be used by future studies for benchmarking and building on our work.