 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConstruction Safety Risk Modeling and Simulation
Paper and Code
Sep 26, 2016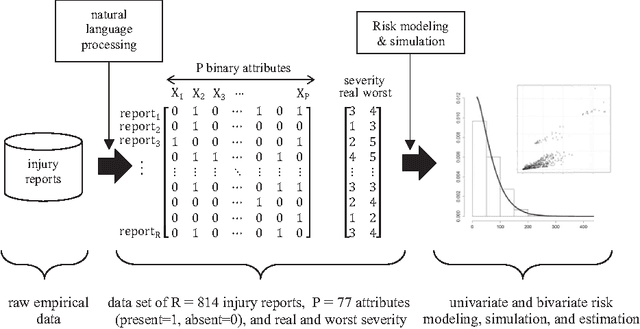
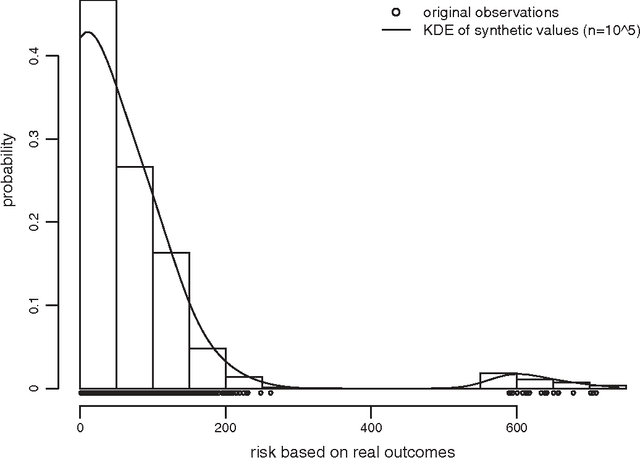
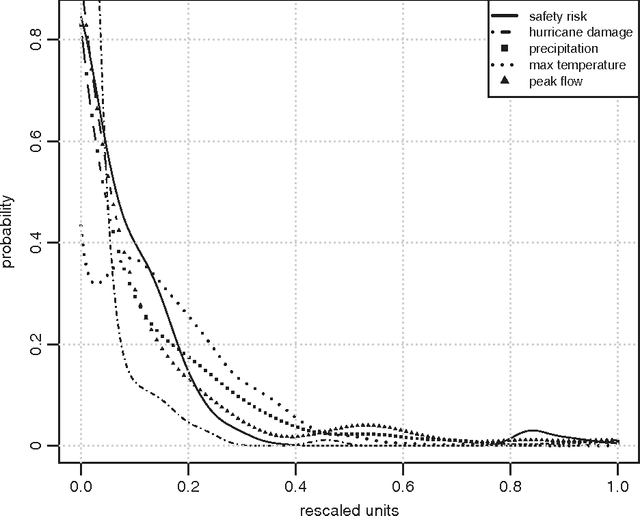
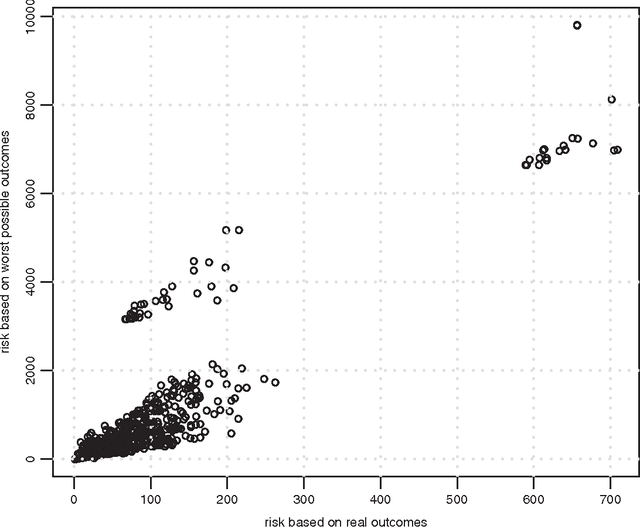
By building on a recently introduced genetic-inspired attribute-based conceptual framework for safety risk analysis, we propose a novel methodology to compute construction univariate and bivariate construction safety risk at a situational level. Our fully data-driven approach provides construction practitioners and academicians with an easy and automated way of extracting valuable empirical insights from databases of unstructured textual injury reports. By applying our methodology on an attribute and outcome dataset directly obtained from 814 injury reports, we show that the frequency-magnitude distribution of construction safety risk is very similar to that of natural phenomena such as precipitation or earthquakes. Motivated by this observation, and drawing on state-of-the-art techniques in hydroclimatology and insurance, we introduce univariate and bivariate nonparametric stochastic safety risk generators, based on Kernel Density Estimators and Copulas. These generators enable the user to produce large numbers of synthetic safety risk values faithfully to the original data, allowing safetyrelated decision-making under uncertainty to be grounded on extensive empirical evidence. Just like the accurate modeling and simulation of natural phenomena such as wind or streamflow is indispensable to successful structure dimensioning or water reservoir management, we posit that improving construction safety calls for the accurate modeling, simulation, and assessment of safety risk. The underlying assumption is that like natural phenomena, construction safety may benefit from being studied in an empirical and quantitative way rather than qualitatively which is the current industry standard. Finally, a side but interesting finding is that attributes related to high energy levels and to human error emerge as strong risk shapers on the dataset we used to illustrate our methodology.