 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistance preservation in state-space methods for detecting causal interactions in dynamical systems
Aug 13, 2023We analyze the popular ``state-space'' class of algorithms for detecting casual interaction in coupled dynamical systems. These algorithms are often justified by Takens' embedding theorem, which provides conditions under which relationships involving attractors and their delay embeddings are continuous. In practice, however, state-space methods often do not directly test continuity, but rather the stronger property of how these relationships preserve inter-point distances. This paper theoretically and empirically explores state-space algorithms explicitly from the perspective of distance preservation. We first derive basic theoretical guarantees applicable to simple coupled systems, providing conditions under which the distance preservation of a certain map reveals underlying causal structure. Second, we demonstrate empirically that typical coupled systems do not satisfy distance preservation assumptions. Taken together, our results underline the dependence of state-space algorithms on intrinsic system properties and the relationship between the system and the function used to measure it -- properties that are not directly associated with causal interaction.
PrefGen: Preference Guided Image Generation with Relative Attributes
Apr 01, 2023



Deep generative models have the capacity to render high fidelity images of content like human faces. Recently, there has been substantial progress in conditionally generating images with specific quantitative attributes, like the emotion conveyed by one's face. These methods typically require a user to explicitly quantify the desired intensity of a visual attribute. A limitation of this method is that many attributes, like how "angry" a human face looks, are difficult for a user to precisely quantify. However, a user would be able to reliably say which of two faces seems "angrier". Following this premise, we develop the $\textit{PrefGen}$ system, which allows users to control the relative attributes of generated images by presenting them with simple paired comparison queries of the form "do you prefer image $a$ or image $b$?" Using information from a sequence of query responses, we can estimate user preferences over a set of image attributes and perform preference-guided image editing and generation. Furthermore, to make preference localization feasible and efficient, we apply an active query selection strategy. We demonstrate the success of this approach using a StyleGAN2 generator on the task of human face editing. Additionally, we demonstrate how our approach can be combined with CLIP, allowing a user to edit the relative intensity of attributes specified by text prompts. Code at https://github.com/helblazer811/PrefGen.
Five policy uses of algorithmic explainability
Feb 06, 2023The notion that algorithmic systems should be "explainable" is common in the many statements of consensus principles developed by governments, companies, and advocacy organizations. But what exactly do these policy and legal actors want from explainability, and how do their desiderata compare with the explainability techniques developed in the machine learning literature? We explore this question in hopes of better connecting the policy and technical communities. We outline five settings in which policymakers seek to use explainability: complying with specific requirements for explanation; helping to obtain regulatory approval in highly regulated settings; enabling or interfacing with liability; flexibly managing risk as part of a self-regulatory process; and providing model and data transparency. We illustrate each setting with an in-depth case study contextualizing the purpose and role of explanation. Drawing on these case studies, we discuss common factors limiting policymakers' use of explanation and promising ways in which explanation can be used in policy. We conclude with recommendations for researchers and policymakers.
Oracle Guided Image Synthesis with Relative Queries
Apr 28, 2022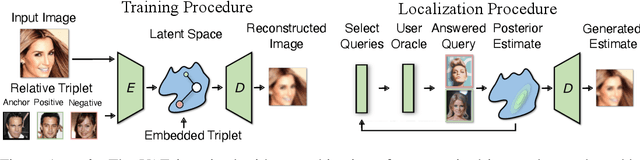
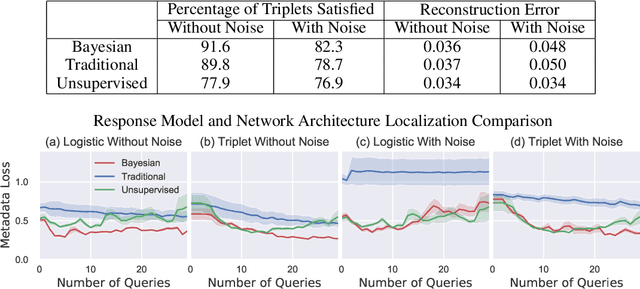

Isolating and controlling specific features in the outputs of generative models in a user-friendly way is a difficult and open-ended problem. We develop techniques that allow an oracle user to generate an image they are envisioning in their head by answering a sequence of relative queries of the form \textit{"do you prefer image $a$ or image $b$?"} Our framework consists of a Conditional VAE that uses the collected relative queries to partition the latent space into preference-relevant features and non-preference-relevant features. We then use the user's responses to relative queries to determine the preference-relevant features that correspond to their envisioned output image. Additionally, we develop techniques for modeling the uncertainty in images' predicted preference-relevant features, allowing our framework to generalize to scenarios in which the relative query training set contains noise.
Generative causal explanations of black-box classifiers
Jun 24, 2020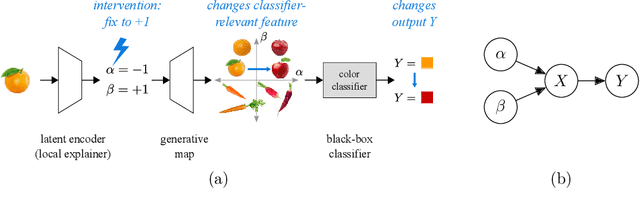

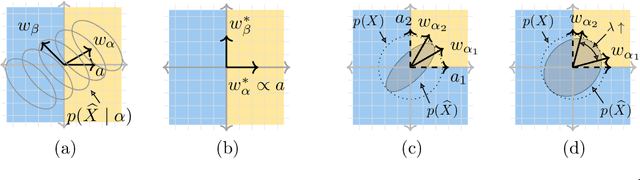

We develop a method for generating causal post-hoc explanations of black-box classifiers based on a learned low-dimensional representation of the data. The explanation is causal in the sense that changing learned latent factors produces a change in the classifier output statistics. To construct these explanations, we design a learning framework that leverages a generative model and information-theoretic measures of causal influence. Our objective function encourages both the generative model to faithfully represent the data distribution and the latent factors to have a large causal influence on the classifier output. Our method learns both global and local explanations, is compatible with any classifier that admits class probabilities and a gradient, and does not require labeled attributes or knowledge of causal structure. Using carefully controlled test cases, we provide intuition that illuminates the function of our causal objective. We then demonstrate the practical utility of our method on image recognition tasks.