 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRare Gems: Finding Lottery Tickets at Initialization
Feb 24, 2022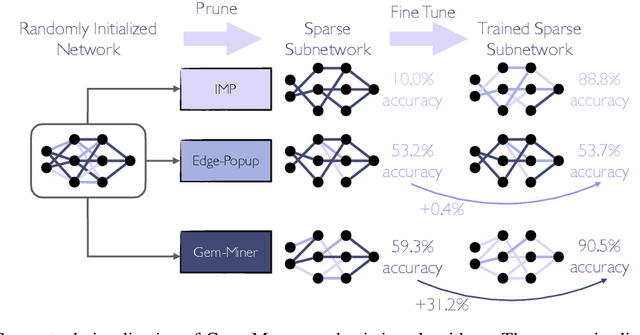

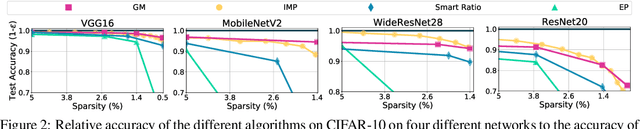

It has been widely observed that large neural networks can be pruned to a small fraction of their original size, with little loss in accuracy, by typically following a time-consuming "train, prune, re-train" approach. Frankle & Carbin (2018) conjecture that we can avoid this by training lottery tickets, i.e., special sparse subnetworks found at initialization, that can be trained to high accuracy. However, a subsequent line of work presents concrete evidence that current algorithms for finding trainable networks at initialization, fail simple baseline comparisons, e.g., against training random sparse subnetworks. Finding lottery tickets that train to better accuracy compared to simple baselines remains an open problem. In this work, we partially resolve this open problem by discovering rare gems: subnetworks at initialization that attain considerable accuracy, even before training. Refining these rare gems - "by means of fine-tuning" - beats current baselines and leads to accuracy competitive or better than magnitude pruning methods.