 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesian Bellman Operators
Jun 15, 2021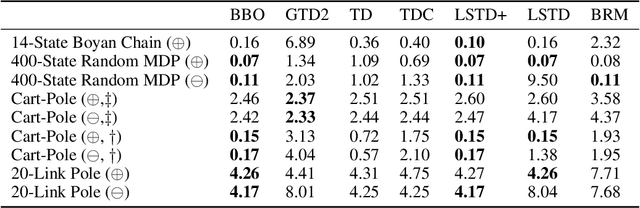
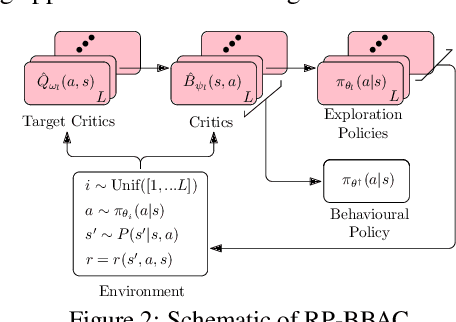
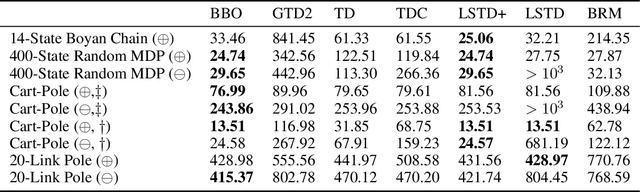

We introduce a novel perspective on Bayesian reinforcement learning (RL); whereas existing approaches infer a posterior over the transition distribution or Q-function, we characterise the uncertainty in the Bellman operator. Our Bayesian Bellman operator (BBO) framework is motivated by the insight that when bootstrapping is introduced, model-free approaches actually infer a posterior over Bellman operators, not value functions. In this paper, we use BBO to provide a rigorous theoretical analysis of model-free Bayesian RL to better understand its relationshipto established frequentist RL methodologies. We prove that Bayesian solutions are consistent with frequentist RL solutions, even when approximate inference isused, and derive conditions for which convergence properties hold. Empirically, we demonstrate that algorithms derived from the BBO framework have sophisticated deep exploration properties that enable them to solve continuous control tasks at which state-of-the-art regularised actor-critic algorithms fail catastrophically
VIREL: A Variational Inference Framework for Reinforcement Learning
Nov 03, 2018



Applying probabilistic models to reinforcement learning (RL) has become an exciting direction of research owing to powerful optimisation tools such as variational inference becoming applicable to RL. However, due to their formulation, existing inference frameworks and their algorithms pose significant challenges for learning optimal policies, for example, the absence of mode capturing behaviour in pseudo-likelihood methods and difficulties in optimisation of learning objective in maximum entropy RL based approaches. We propose VIREL, a novel, theoretically grounded probabilistic inference framework for RL that utilises the action-value function in a parametrised form to capture future dynamics of the underlying Markov decision process. Owing to it's generality, our framework lends itself to current advances in variational inference. Applying the variational expectation-maximisation algorithm to our framework, we show that actor-critic algorithm can be reduced to expectation-maximization. We derive a family of methods from our framework, including state-of-the-art methods based on soft value functions. We evaluate two actor-critic algorithms derived from this family, which perform on par with soft actor critic, demonstrating that our framework offers a promising perspective on RL as inference.
Fourier Policy Gradients
May 30, 2018
We propose a new way of deriving policy gradient updates for reinforcement learning. Our technique, based on Fourier analysis, recasts integrals that arise with expected policy gradients as convolutions and turns them into multiplications. The obtained analytical solutions allow us to capture the low variance benefits of EPG in a broad range of settings. For the critic, we treat trigonometric and radial basis functions, two function families with the universal approximation property. The choice of policy can be almost arbitrary, including mixtures or hybrid continuous-discrete probability distributions. Moreover, we derive a general family of sample-based estimators for stochastic policy gradients, which unifies existing results on sample-based approximation. We believe that this technique has the potential to shape the next generation of policy gradient approaches, powered by analytical results.