 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReply With: Proactive Recommendation of Email Attachments
Nov 16, 2017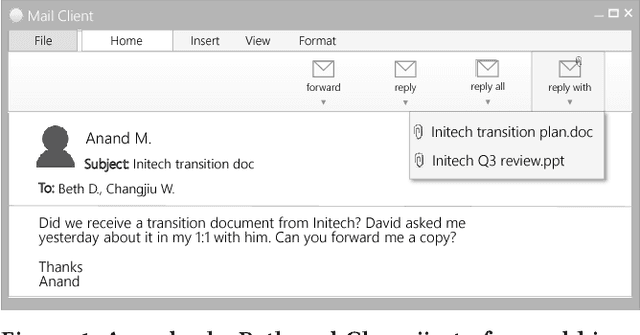
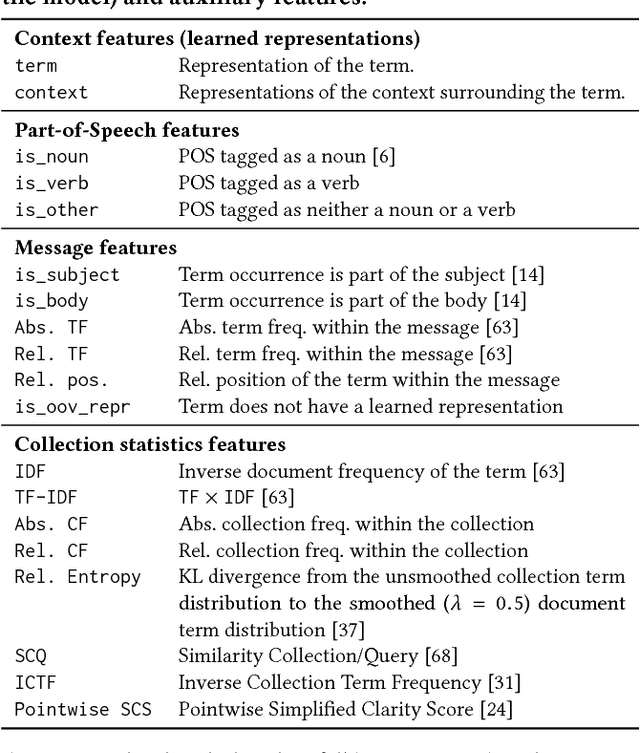
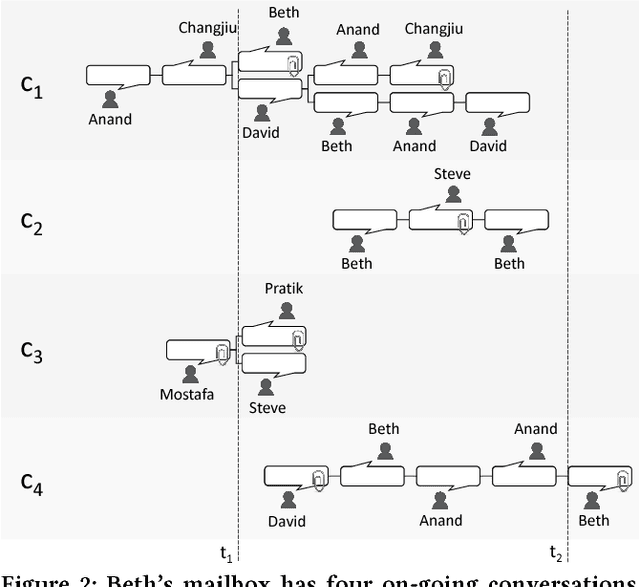
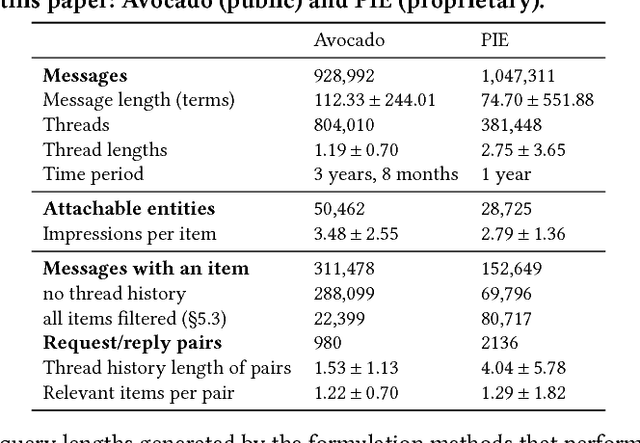
Email responses often contain items-such as a file or a hyperlink to an external document-that are attached to or included inline in the body of the message. Analysis of an enterprise email corpus reveals that 35% of the time when users include these items as part of their response, the attachable item is already present in their inbox or sent folder. A modern email client can proactively retrieve relevant attachable items from the user's past emails based on the context of the current conversation, and recommend them for inclusion, to reduce the time and effort involved in composing the response. In this paper, we propose a weakly supervised learning framework for recommending attachable items to the user. As email search systems are commonly available, we constrain the recommendation task to formulating effective search queries from the context of the conversations. The query is submitted to an existing IR system to retrieve relevant items for attachment. We also present a novel strategy for generating labels from an email corpus---without the need for manual annotations---that can be used to train and evaluate the query formulation model. In addition, we describe a deep convolutional neural network that demonstrates satisfactory performance on this query formulation task when evaluated on the publicly available Avocado dataset and a proprietary dataset of internal emails obtained through an employee participation program.
Time-Sensitive Bayesian Information Aggregation for Crowdsourcing Systems
Apr 18, 2016
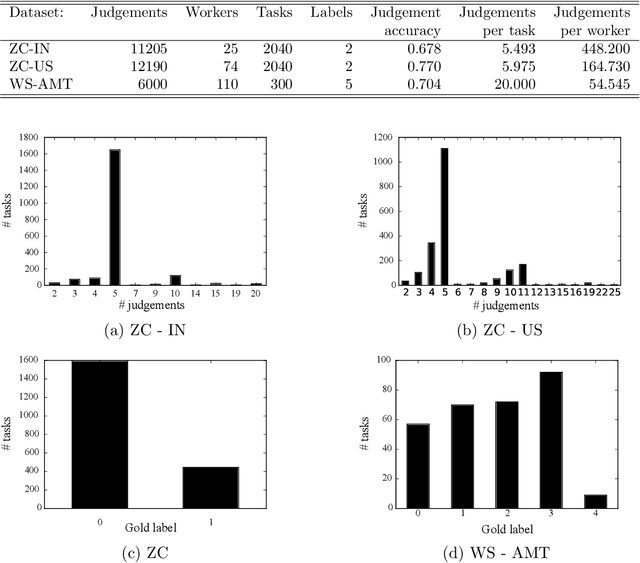

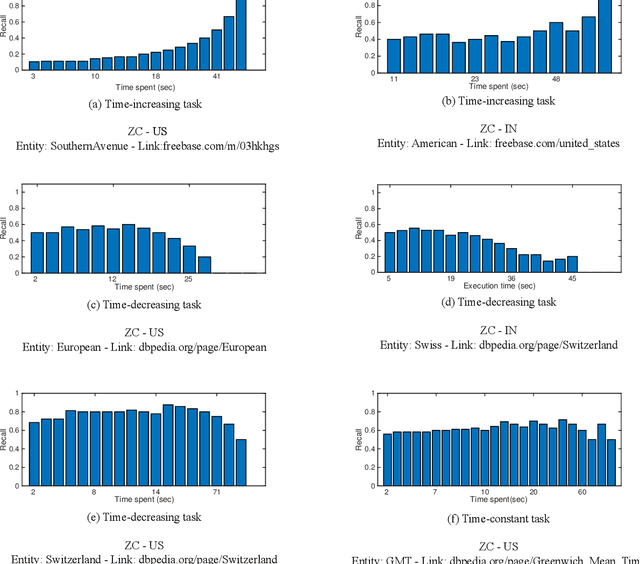
Crowdsourcing systems commonly face the problem of aggregating multiple judgments provided by potentially unreliable workers. In addition, several aspects of the design of efficient crowdsourcing processes, such as defining worker's bonuses, fair prices and time limits of the tasks, involve knowledge of the likely duration of the task at hand. Bringing this together, in this work we introduce a new time--sensitive Bayesian aggregation method that simultaneously estimates a task's duration and obtains reliable aggregations of crowdsourced judgments. Our method, called BCCTime, builds on the key insight that the time taken by a worker to perform a task is an important indicator of the likely quality of the produced judgment. To capture this, BCCTime uses latent variables to represent the uncertainty about the workers' completion time, the tasks' duration and the workers' accuracy. To relate the quality of a judgment to the time a worker spends on a task, our model assumes that each task is completed within a latent time window within which all workers with a propensity to genuinely attempt the labelling task (i.e., no spammers) are expected to submit their judgments. In contrast, workers with a lower propensity to valid labeling, such as spammers, bots or lazy labelers, are assumed to perform tasks considerably faster or slower than the time required by normal workers. Specifically, we use efficient message-passing Bayesian inference to learn approximate posterior probabilities of (i) the confusion matrix of each worker, (ii) the propensity to valid labeling of each worker, (iii) the unbiased duration of each task and (iv) the true label of each task. Using two real-world public datasets for entity linking tasks, we show that BCCTime produces up to 11% more accurate classifications and up to 100% more informative estimates of a task's duration compared to state-of-the-art methods.