 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConversational Control with Ontologies for Large Language Models: A Lightweight Framework for Constrained Generation
Apr 06, 2026Conversational agents based on Large Language Models (LLMs) have recently emerged as powerful tools for human-computer interaction. Nevertheless, their black-box nature implies challenges in predictability and a lack of personalization, both of which can be addressed by controlled generation. This work proposes an end-to-end method to obtain modular and explainable control over LLM outputs through ontological definitions of aspects related to the conversation. Key aspects are modeled and used as constraints; we then further fine-tune the LLM to generate content accordingly. To validate our approach, we explore two tasks that tackle two key conversational aspects: the English proficiency level and the polarity profile of the content. Using a hybrid fine-tuning procedure on seven state-of-the-art, open-weight conversational LLMs, we show that our method consistently outperforms pre-trained baselines, even on smaller models. Beyond quantitative gains, the framework remains model-agnostic, lightweight, and interpretable, enabling reusable control strategies that can be extended to new domains and interaction goals. This approach enhances alignment with strategy instructions and demonstrates the effectiveness of ontology-driven control in conversational systems.
Ontological Relations from Word Embeddings
Aug 01, 2024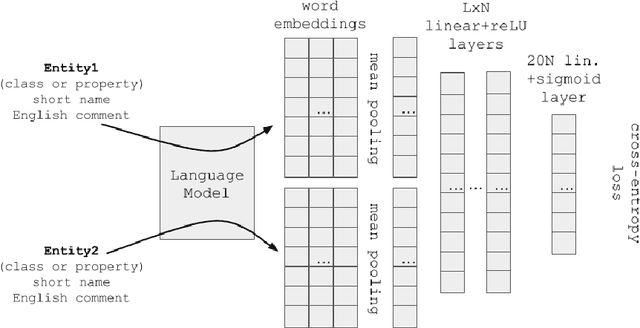
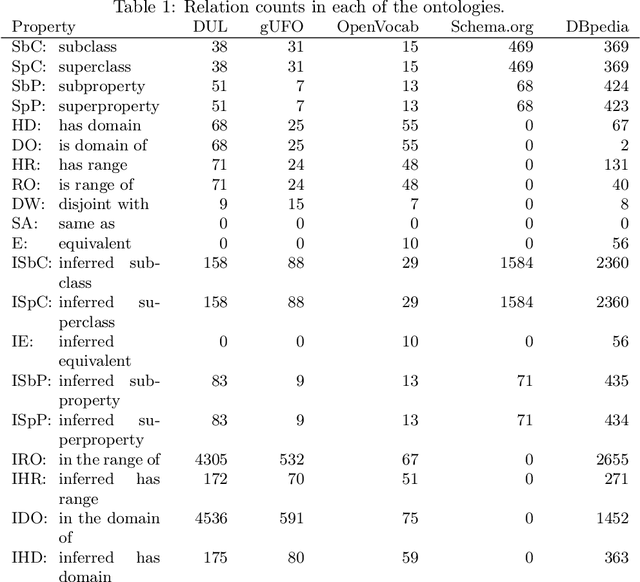
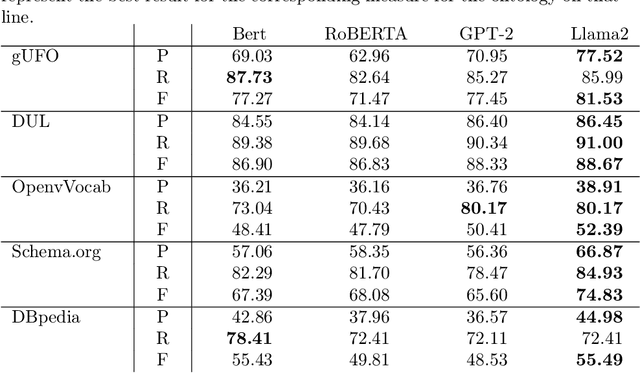
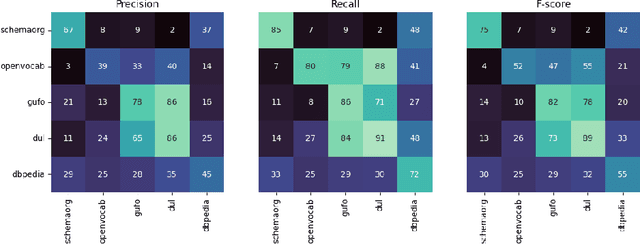
It has been reliably shown that the similarity of word embeddings obtained from popular neural models such as BERT approximates effectively a form of semantic similarity of the meaning of those words. It is therefore natural to wonder if those embeddings contain enough information to be able to connect those meanings through ontological relationships such as the one of subsumption. If so, large knowledge models could be built that are capable of semantically relating terms based on the information encapsulated in word embeddings produced by pre-trained models, with implications not only for ontologies (ontology matching, ontology evolution, etc.) but also on the ability to integrate ontological knowledge in neural models. In this paper, we test how embeddings produced by several pre-trained models can be used to predict relations existing between classes and properties of popular upper-level and general ontologies. We show that even a simple feed-forward architecture on top of those embeddings can achieve promising accuracies, with varying generalisation abilities depending on the input data. To achieve that, we produce a dataset that can be used to further enhance those models, opening new possibilities for applications integrating knowledge from web ontologies.
Finding Concept Representations in Neural Networks with Self-Organizing Maps
Dec 10, 2023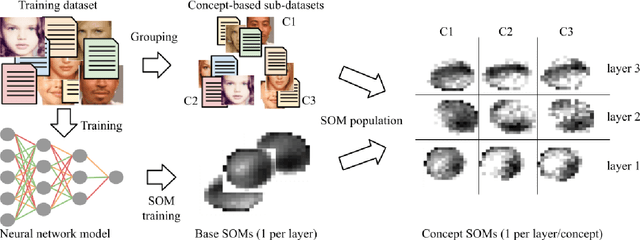

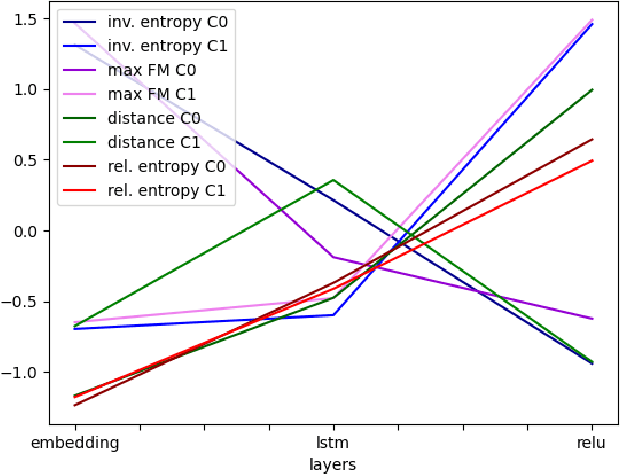
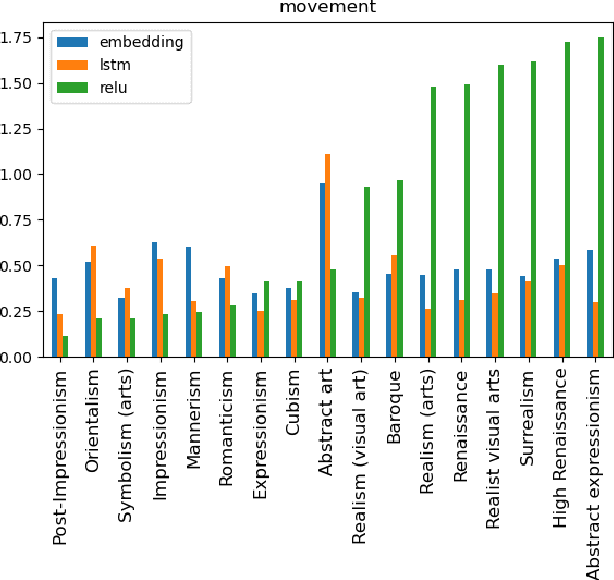
In sufficiently complex tasks, it is expected that as a side effect of learning to solve a problem, a neural network will learn relevant abstractions of the representation of that problem. This has been confirmed in particular in machine vision where a number of works showed that correlations could be found between the activations of specific units (neurons) in a neural network and the visual concepts (textures, colors, objects) present in the image. Here, we explore the use of self-organizing maps as a way to both visually and computationally inspect how activation vectors of whole layers of neural networks correspond to neural representations of abstract concepts such as `female person' or `realist painter'. We experiment with multiple measures applied to those maps to assess the level of representation of a concept in a network's layer. We show that, among the measures tested, the relative entropy of the activation map for a concept compared to the map for the whole data is a suitable candidate and can be used as part of a methodology to identify and locate the neural representation of a concept, visualize it, and understand its importance in solving the prediction task at hand.
TaBIIC: Taxonomy Building through Iterative and Interactive Clustering
Dec 10, 2023

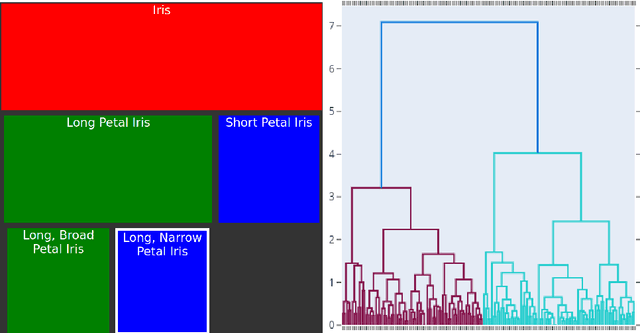
Building taxonomies is often a significant part of building an ontology, and many attempts have been made to automate the creation of such taxonomies from relevant data. The idea in such approaches is either that relevant definitions of the intension of concepts can be extracted as patterns in the data (e.g. in formal concept analysis) or that their extension can be built from grouping data objects based on similarity (clustering). In both cases, the process leads to an automatically constructed structure, which can either be too coarse and lacking in definition, or too fined-grained and detailed, therefore requiring to be refined into the desired taxonomy. In this paper, we explore a method that takes inspiration from both approaches in an iterative and interactive process, so that refinement and definition of the concepts in the taxonomy occur at the time of identifying those concepts in the data. We show that this method is applicable on a variety of data sources and leads to taxonomies that can be more directly integrated into ontologies.
PyGraft: Configurable Generation of Schemas and Knowledge Graphs at Your Fingertips
Sep 07, 2023Knowledge graphs (KGs) have emerged as a prominent data representation and management paradigm. Being usually underpinned by a schema (e.g. an ontology), KGs capture not only factual information but also contextual knowledge. In some tasks, a few KGs established themselves as standard benchmarks. However, recent works outline that relying on a limited collection of datasets is not sufficient to assess the generalization capability of an approach. In some data-sensitive fields such as education or medicine, access to public datasets is even more limited. To remedy the aforementioned issues, we release PyGraft, a Python-based tool that generates highly customized, domain-agnostic schemas and knowledge graphs. The synthesized schemas encompass various RDFS and OWL constructs, while the synthesized KGs emulate the characteristics and scale of real-world KGs. Logical consistency of the generated resources is ultimately ensured by running a description logic (DL) reasoner. By providing a way of generating both a schema and KG in a single pipeline, PyGraft's aim is to empower the generation of a more diverse array of KGs for benchmarking novel approaches in areas such as graph-based machine learning (ML), or more generally KG processing. In graph-based ML in particular, this should foster a more holistic evaluation of model performance and generalization capability, thereby going beyond the limited collection of available benchmarks. PyGraft is available at: https://github.com/nicolas-hbt/pygraft.
Towards Sharing Task Environments to Support Reproducible Evaluations of Interactive Recommender Systems
Sep 16, 2019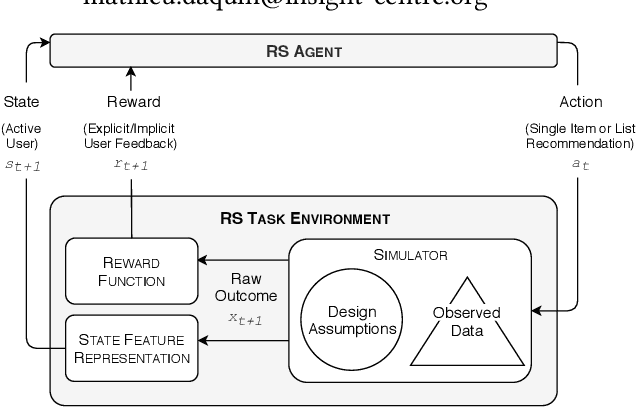
Beyond sharing datasets or simulations, we believe the Recommender Systems (RS) community should share Task Environments. In this work, we propose a high-level logical architecture that will help to reason about the core components of a RS Task Environment, identify the differences between Environments, datasets and simulations; and most importantly, understand what needs to be shared about Environments to achieve reproducible experiments. The work presents itself as valuable initial groundwork, open to discussion and extensions.