 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOntological Relations from Word Embeddings
Aug 01, 2024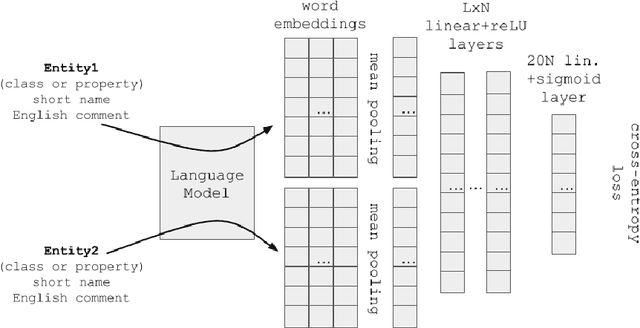
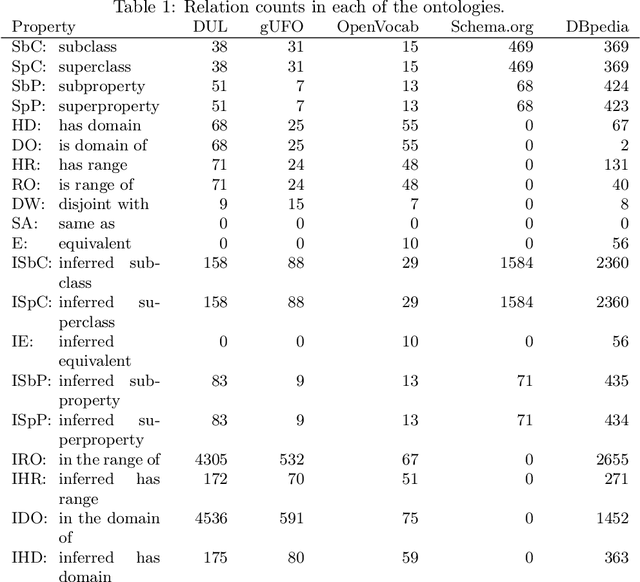
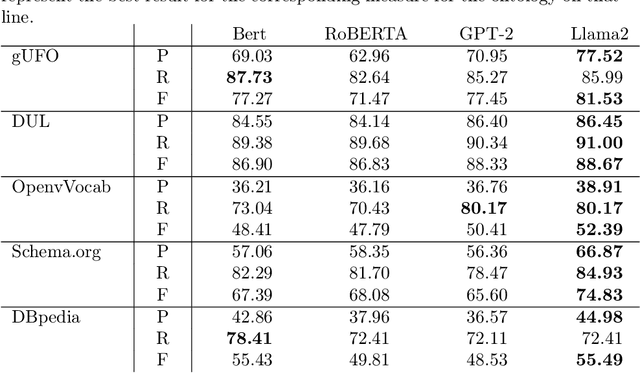
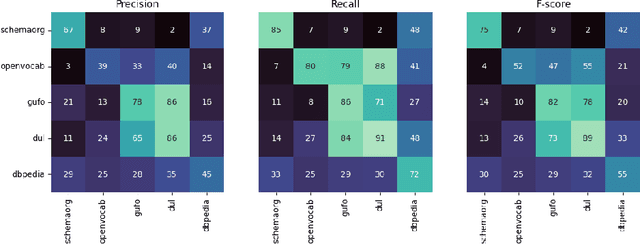
It has been reliably shown that the similarity of word embeddings obtained from popular neural models such as BERT approximates effectively a form of semantic similarity of the meaning of those words. It is therefore natural to wonder if those embeddings contain enough information to be able to connect those meanings through ontological relationships such as the one of subsumption. If so, large knowledge models could be built that are capable of semantically relating terms based on the information encapsulated in word embeddings produced by pre-trained models, with implications not only for ontologies (ontology matching, ontology evolution, etc.) but also on the ability to integrate ontological knowledge in neural models. In this paper, we test how embeddings produced by several pre-trained models can be used to predict relations existing between classes and properties of popular upper-level and general ontologies. We show that even a simple feed-forward architecture on top of those embeddings can achieve promising accuracies, with varying generalisation abilities depending on the input data. To achieve that, we produce a dataset that can be used to further enhance those models, opening new possibilities for applications integrating knowledge from web ontologies.
Automatic case acquisition from texts for process-oriented case-based reasoning
Apr 14, 2013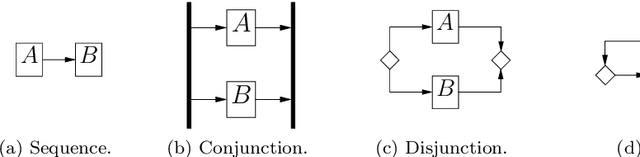



This paper introduces a method for the automatic acquisition of a rich case representation from free text for process-oriented case-based reasoning. Case engineering is among the most complicated and costly tasks in implementing a case-based reasoning system. This is especially so for process-oriented case-based reasoning, where more expressive case representations are generally used and, in our opinion, actually required for satisfactory case adaptation. In this context, the ability to acquire cases automatically from procedural texts is a major step forward in order to reason on processes. We therefore detail a methodology that makes case acquisition from processes described as free text possible, with special attention given to assembly instruction texts. This methodology extends the techniques we used to extract actions from cooking recipes. We argue that techniques taken from natural language processing are required for this task, and that they give satisfactory results. An evaluation based on our implemented prototype extracting workflows from recipe texts is provided.
* Sous presse, publication pr\'evue en 2013
Semi-automatic annotation process for procedural texts: An application on cooking recipes
Sep 25, 2012
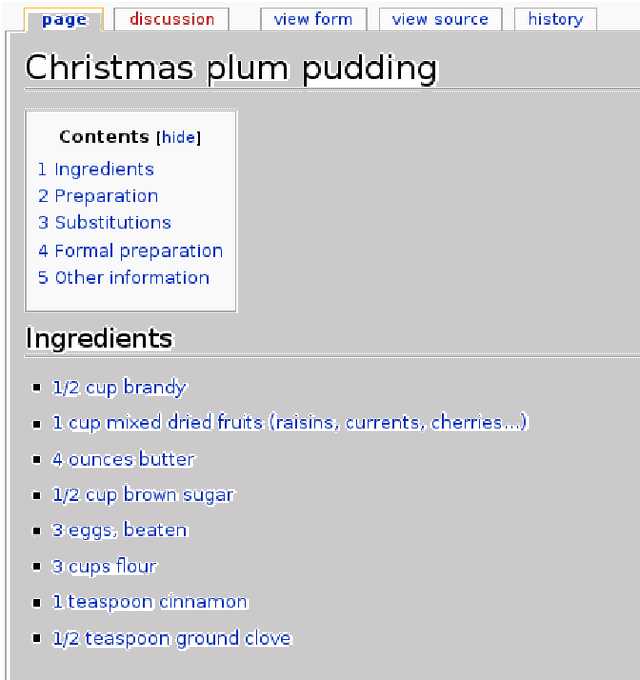
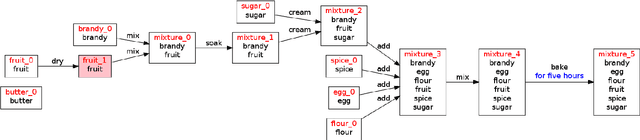
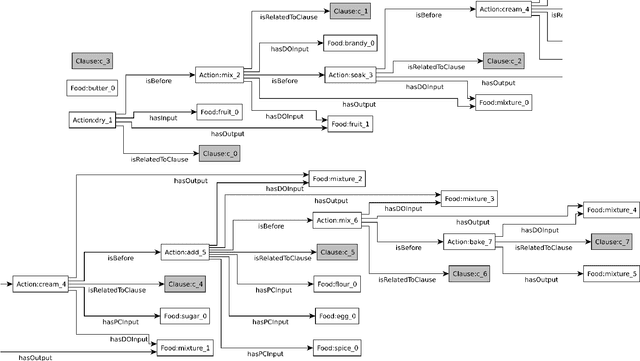
Taaable is a case-based reasoning system that adapts cooking recipes to user constraints. Within it, the preparation part of recipes is formalised as a graph. This graph is a semantic representation of the sequence of instructions composing the cooking process and is used to compute the procedure adaptation, conjointly with the textual adaptation. It is composed of cooking actions and ingredients, among others, represented as vertices, and semantic relations between those, shown as arcs, and is built automatically thanks to natural language processing. The results of the automatic annotation process is often a disconnected graph, representing an incomplete annotation, or may contain errors. Therefore, a validating and correcting step is required. In this paper, we present an existing graphic tool named \kcatos, conceived for representing and editing decision trees, and show how it has been adapted and integrated in WikiTaaable, the semantic wiki in which the knowledge used by Taaable is stored. This interface provides the wiki users with a way to correct the case representation of the cooking process, improving at the same time the quality of the knowledge about cooking procedures stored in WikiTaaable.