 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeG2CP: A Graph-Grounded Communication Protocol for Verifiable and Efficient Multi-Agent Reasoning
Feb 13, 2026Multi-agent systems powered by Large Language Models face a critical challenge: agents communicate through natural language, leading to semantic drift, hallucination propagation, and inefficient token consumption. We propose G2CP (Graph-Grounded Communication Protocol), a structured agent communication language where messages are graph operations rather than free text. Agents exchange explicit traversal commands, subgraph fragments, and update operations over a shared knowledge graph, enabling verifiable reasoning traces and eliminating ambiguity. We validate G2CP within an industrial knowledge management system where specialized agents (Diagnostic, Procedural, Synthesis, and Ingestion) coordinate to answer complex queries. Experimental results on 500 industrial scenarios and 21 real-world maintenance cases show that G2CP reduces inter-agent communication tokens by 73%, improves task completion accuracy by 34% over free-text baselines, eliminates cascading hallucinations, and produces fully auditable reasoning chains. G2CP represents a fundamental shift from linguistic to structural communication in multi-agent systems, with implications for any domain requiring precise agent coordination. Code, data, and evaluation scripts are publicly available.
Do Similar Entities have Similar Embeddings?
Dec 16, 2023
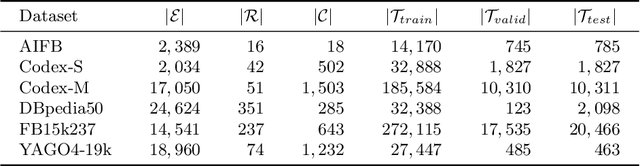

Knowledge graph embedding models (KGEMs) developed for link prediction learn vector representations for graph entities, known as embeddings. A common tacit assumption is the KGE entity similarity assumption, which states that these KGEMs retain the graph's structure within their embedding space, i.e., position similar entities close to one another. This desirable property make KGEMs widely used in downstream tasks such as recommender systems or drug repurposing. Yet, the alignment of graph similarity with embedding space similarity has rarely been formally evaluated. Typically, KGEMs are assessed based on their sole link prediction capabilities, using ranked-based metrics such as Hits@K or Mean Rank. This paper challenges the prevailing assumption that entity similarity in the graph is inherently mirrored in the embedding space. Therefore, we conduct extensive experiments to measure the capability of KGEMs to cluster similar entities together, and investigate the nature of the underlying factors. Moreover, we study if different KGEMs expose a different notion of similarity. Datasets, pre-trained embeddings and code are available at: https://github.com/nicolas-hbt/similar-embeddings.
PyGraft: Configurable Generation of Schemas and Knowledge Graphs at Your Fingertips
Sep 07, 2023Knowledge graphs (KGs) have emerged as a prominent data representation and management paradigm. Being usually underpinned by a schema (e.g. an ontology), KGs capture not only factual information but also contextual knowledge. In some tasks, a few KGs established themselves as standard benchmarks. However, recent works outline that relying on a limited collection of datasets is not sufficient to assess the generalization capability of an approach. In some data-sensitive fields such as education or medicine, access to public datasets is even more limited. To remedy the aforementioned issues, we release PyGraft, a Python-based tool that generates highly customized, domain-agnostic schemas and knowledge graphs. The synthesized schemas encompass various RDFS and OWL constructs, while the synthesized KGs emulate the characteristics and scale of real-world KGs. Logical consistency of the generated resources is ultimately ensured by running a description logic (DL) reasoner. By providing a way of generating both a schema and KG in a single pipeline, PyGraft's aim is to empower the generation of a more diverse array of KGs for benchmarking novel approaches in areas such as graph-based machine learning (ML), or more generally KG processing. In graph-based ML in particular, this should foster a more holistic evaluation of model performance and generalization capability, thereby going beyond the limited collection of available benchmarks. PyGraft is available at: https://github.com/nicolas-hbt/pygraft.
Schema First! Learn Versatile Knowledge Graph Embeddings by Capturing Semantics with MASCHInE
Jun 06, 2023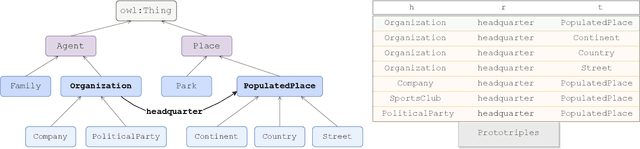
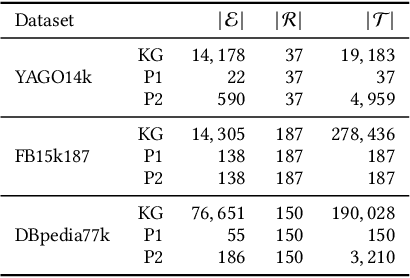
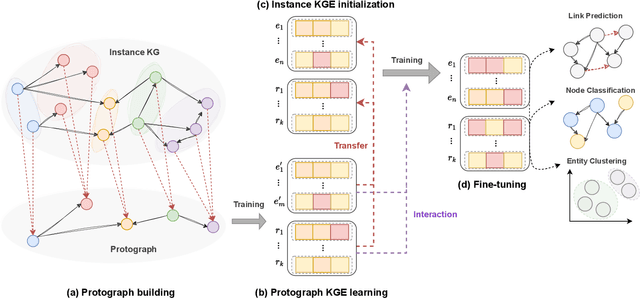
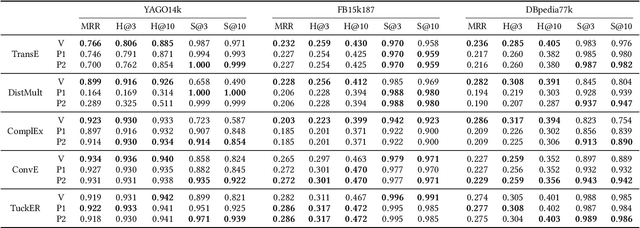
Knowledge graph embedding models (KGEMs) have gained considerable traction in recent years. These models learn a vector representation of knowledge graph entities and relations, a.k.a. knowledge graph embeddings (KGEs). Learning versatile KGEs is desirable as it makes them useful for a broad range of tasks. However, KGEMs are usually trained for a specific task, which makes their embeddings task-dependent. In parallel, the widespread assumption that KGEMs actually create a semantic representation of the underlying entities and relations (e.g., project similar entities closer than dissimilar ones) has been challenged. In this work, we design heuristics for generating protographs -- small, modified versions of a KG that leverage schema-based information. The learnt protograph-based embeddings are meant to encapsulate the semantics of a KG, and can be leveraged in learning KGEs that, in turn, also better capture semantics. Extensive experiments on various evaluation benchmarks demonstrate the soundness of this approach, which we call Modular and Agnostic SCHema-based Integration of protograph Embeddings (MASCHInE). In particular, MASCHInE helps produce more versatile KGEs that yield substantially better performance for entity clustering and node classification tasks. For link prediction, using MASCHInE has little impact on rank-based performance but increases the number of semantically valid predictions.
Enhancing Knowledge Graph Embedding Models with Semantic-driven Loss Functions
Mar 09, 2023Knowledge graph embedding models (KGEMs) are used for various tasks related to knowledge graphs (KGs), including link prediction. They are trained with loss functions that are computed considering a batch of scored triples and their corresponding labels. Traditional approaches consider the label of a triple to be either true or false. However, recent works suggest that all negative triples should not be valued equally. In line with this recent assumption, we posit that semantically valid negative triples might be high-quality negative triples. As such, loss functions should treat them differently from semantically invalid negative ones. To this aim, we propose semantic-driven versions for the three main loss functions for link prediction. In particular, we treat the scores of negative triples differently by injecting background knowledge about relation domains and ranges into the loss functions. In an extensive and controlled experimental setting, we show that the proposed loss functions systematically provide satisfying results on three public benchmark KGs underpinned with different schemas, which demonstrates both the generality and superiority of our proposed approach. In fact, the proposed loss functions do (1) lead to better MRR and Hits@$10$ values, (2) drive KGEMs towards better semantic awareness. This highlights that semantic information globally improves KGEMs, and thus should be incorporated into loss functions. Domains and ranges of relations being largely available in schema-defined KGs, this makes our approach both beneficial and widely usable in practice.
Sem@$K$: Is my knowledge graph embedding model semantic-aware?
Jan 13, 2023



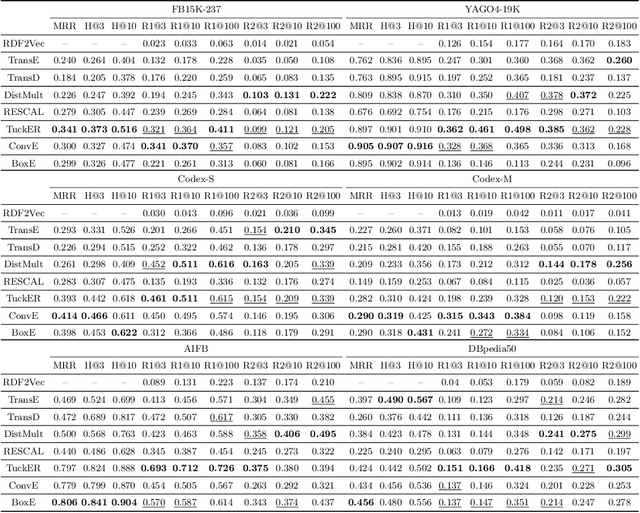
Using knowledge graph embedding models (KGEMs) is a popular approach for predicting links in knowledge graphs (KGs). Traditionally, the performance of KGEMs for link prediction is assessed using rank-based metrics, which evaluate their ability to give high scores to ground-truth entities. However, the literature claims that the KGEM evaluation procedure would benefit from adding supplementary dimensions to assess. That is why, in this paper, we extend our previously introduced metric Sem@$K$ that measures the capability of models to predict valid entities w.r.t. domain and range constrains. In particular, we consider a broad range of KGs and take their respective characteristics into account to propose different versions of Sem@$K$. We also perform an extensive study of KGEM semantic awareness. Our experiments show that Sem@$K$ provides a new perspective on KGEM quality. Its joint analysis with rank-based metrics offer different conclusions on the predictive power of models. Regarding Sem@$K$, some KGEMs are inherently better than others, but this semantic superiority is not indicative of their performance w.r.t. rank-based metrics. In this work, we generalize conclusions about the relative performance of KGEMs w.r.t. rank-based and semantic-oriented metrics at the level of families of models. The joint analysis of the aforementioned metrics gives more insight into the peculiarities of each model. This work paves the way for a more comprehensive evaluation of KGEM adequacy for specific downstream tasks.
Use of Bayesian Network characteristics to link project management maturity and risk of project overcost
Sep 18, 2020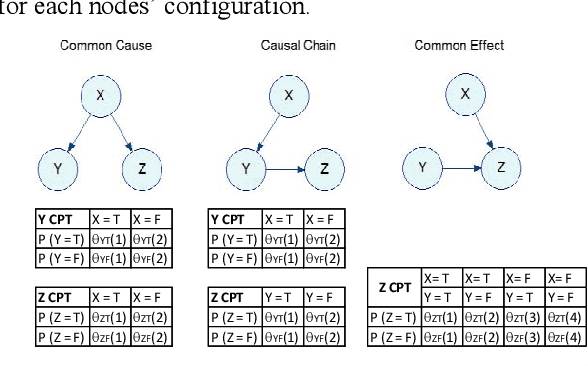
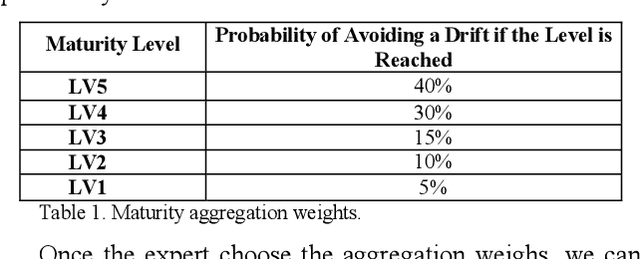
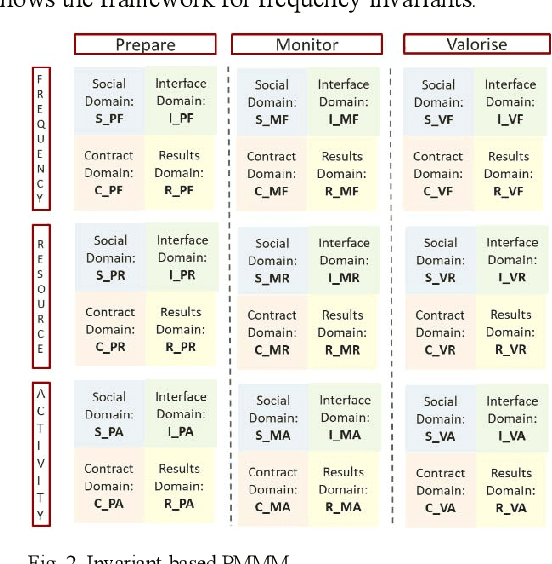
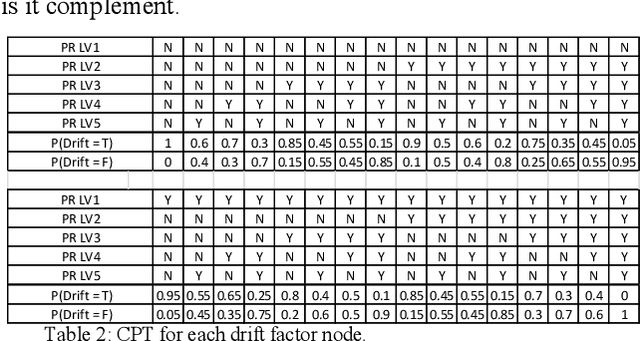
The project management field has the imperative to increase the project probability of success. Experts have developed several project management maturity models to assets and improve the project outcome. However, the current literature lacks of models allowing correlating the measured maturity and the expected probability of success. This paper uses the characteristics of Bayesian networks to formalize experts' knowledge and to extract knowledge from a project overcost database. It develops a method to estimate the impact of project management maturity on the risk of project overcost. A general framework is presented. An industrial case is used to illustrate the application of the method.
Results of multi-agent system and ontology to manage ideas and represent knowledge in a challenge of creativity
Sep 11, 2020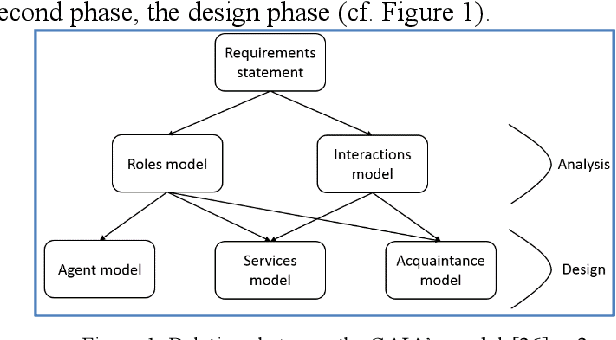
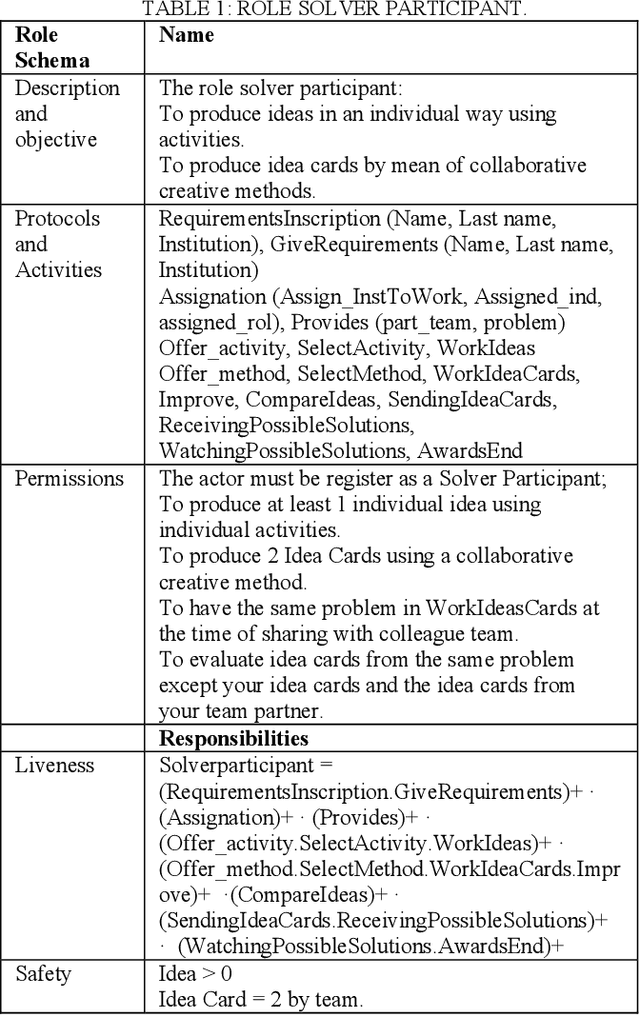

This article is about an intelligent system to support ideas management as a result of a multi-agent system used in a distributed system with heterogeneous information as ideas and knowledge, after the results about an ontology to describe the meaning of these ideas. The intelligent system assists participants of the creativity workshop to manage their ideas and consequently proposing an ontology dedicated to ideas. During the creative workshop many creative activities and collaborative creative methods are used by roles immersed in this creativity workshop event where they share knowledge. The collaboration of these roles is physically distant, their interactions might be synchrony or asynchrony, and the information of the ideas are heterogeneous, so we can say that the process is distributed. Those ideas are writing in natural language by participants which have a role and the ideas are heterogeneous since some of them are described by schema, text or scenario of use. This paper presents first, our MAS and second our Ontology design.