 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Similar Entities have Similar Embeddings?
Paper and Code

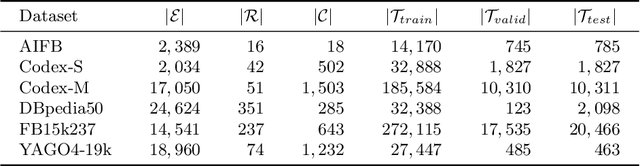

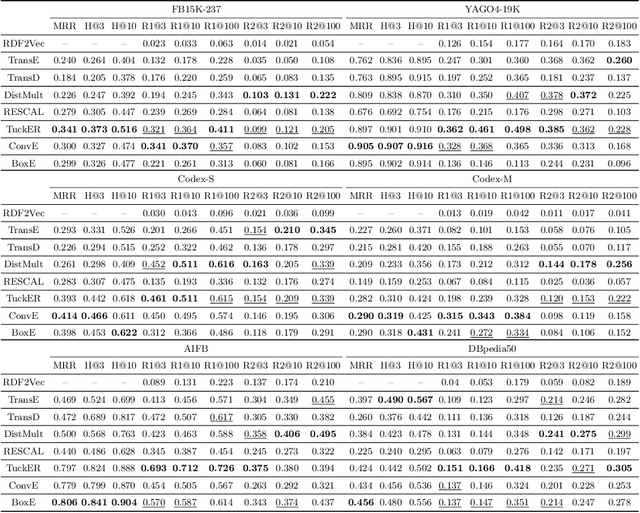
Knowledge graph embedding models (KGEMs) developed for link prediction learn vector representations for graph entities, known as embeddings. A common tacit assumption is the KGE entity similarity assumption, which states that these KGEMs retain the graph's structure within their embedding space, i.e., position similar entities close to one another. This desirable property make KGEMs widely used in downstream tasks such as recommender systems or drug repurposing. Yet, the alignment of graph similarity with embedding space similarity has rarely been formally evaluated. Typically, KGEMs are assessed based on their sole link prediction capabilities, using ranked-based metrics such as Hits@K or Mean Rank. This paper challenges the prevailing assumption that entity similarity in the graph is inherently mirrored in the embedding space. Therefore, we conduct extensive experiments to measure the capability of KGEMs to cluster similar entities together, and investigate the nature of the underlying factors. Moreover, we study if different KGEMs expose a different notion of similarity. Datasets, pre-trained embeddings and code are available at: https://github.com/nicolas-hbt/similar-embeddings.