 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinding Concept Representations in Neural Networks with Self-Organizing Maps
Paper and Code
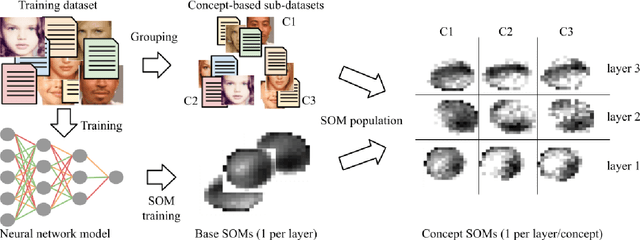

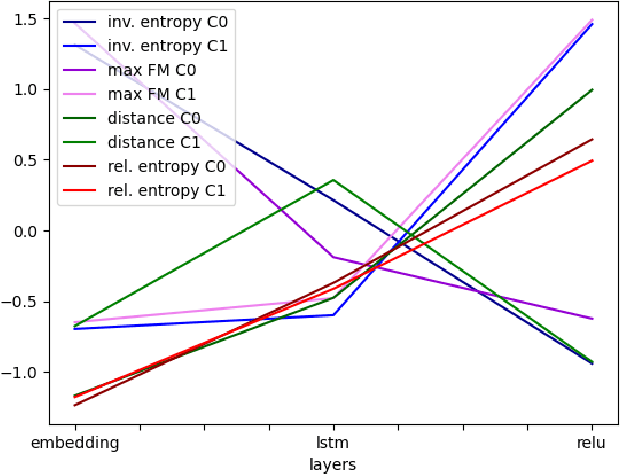
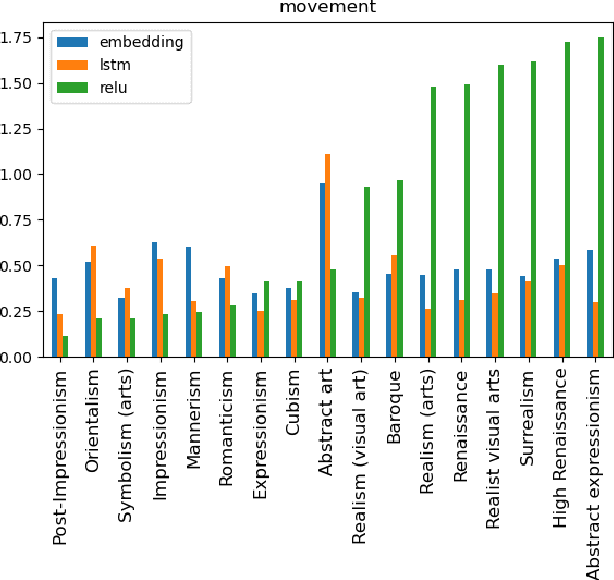
In sufficiently complex tasks, it is expected that as a side effect of learning to solve a problem, a neural network will learn relevant abstractions of the representation of that problem. This has been confirmed in particular in machine vision where a number of works showed that correlations could be found between the activations of specific units (neurons) in a neural network and the visual concepts (textures, colors, objects) present in the image. Here, we explore the use of self-organizing maps as a way to both visually and computationally inspect how activation vectors of whole layers of neural networks correspond to neural representations of abstract concepts such as `female person' or `realist painter'. We experiment with multiple measures applied to those maps to assess the level of representation of a concept in a network's layer. We show that, among the measures tested, the relative entropy of the activation map for a concept compared to the map for the whole data is a suitable candidate and can be used as part of a methodology to identify and locate the neural representation of a concept, visualize it, and understand its importance in solving the prediction task at hand.