 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetric@CustomerN: Evaluating Metrics at a Customer Level in E-Commerce
Jul 31, 2023
Accuracy measures such as Recall, Precision, and Hit Rate have been a standard way of evaluating Recommendation Systems. The assumption is to use a fixed Top-N to represent them. We propose that median impressions viewed from historical sessions per diner be used as a personalized value for N. We present preliminary exploratory results and list future steps to improve upon and evaluate the efficacy of these personalized metrics.
Towards Creating a Standardized Collection of Simple and Targeted Experiments to Analyze Core Aspects of the Recommender Systems Problem
Oct 08, 2021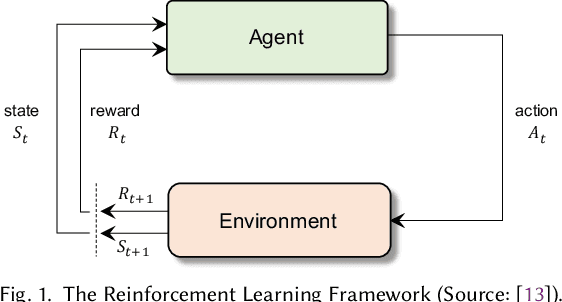
Imagine you are a teacher attempting to assess a student's level in a particular subject. If you design a test with only hard questions, and the student fails, this mostly proves that the student does not understand the more advanced material. A more insightful exam would include different types of questions varying in difficulty to truly understand the student's weaknesses and strengths from different perspectives. In the field of Recommender Systems (RS), more often than not, we design evaluations to measure an algorithm's ability to optimize goals in complex scenarios, representative of the real-world challenges the system would most probably face. Nevertheless, this paper posits that testing an algorithm's ability to address both simple and complex tasks/problems would offer a more detailed view of performance to help identify, at a more granular level, the weaknesses and strengths of solutions when facing different scenarios/domains. We believe the RS community would greatly benefit from creating a collection of standardized, simple, and targeted experiments, which, much like a suite of "unit tests", would individually assess an algorithm's ability to tackle core challenges that make up complex RS tasks. What's more, these experiments go beyond traditional pass/fail "unit tests". Running an algorithm against the collection of experiments allows a researcher to empirically analyze in which type of settings an algorithm performs best and to what degree under different metrics. Not only do we defend this position, in this paper, we also offer a proposal of how these simple and targeted experiments could be defined and shared and suggest potential next steps to make this project a reality.
Towards Sharing Task Environments to Support Reproducible Evaluations of Interactive Recommender Systems
Sep 16, 2019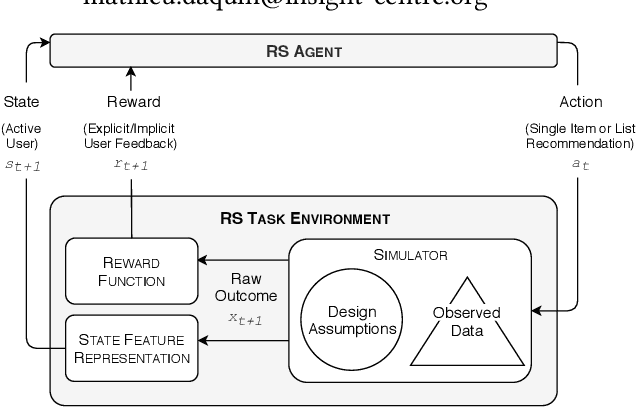
Beyond sharing datasets or simulations, we believe the Recommender Systems (RS) community should share Task Environments. In this work, we propose a high-level logical architecture that will help to reason about the core components of a RS Task Environment, identify the differences between Environments, datasets and simulations; and most importantly, understand what needs to be shared about Environments to achieve reproducible experiments. The work presents itself as valuable initial groundwork, open to discussion and extensions.