 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocally Optimized Random Forests
Aug 27, 2019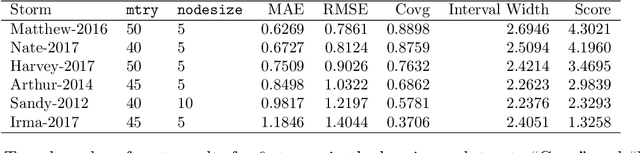

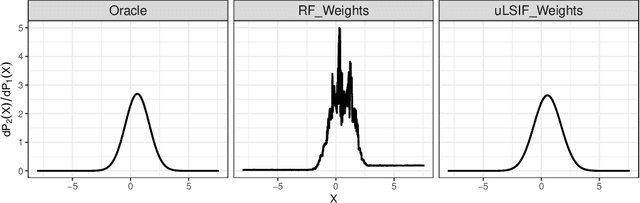

Standard supervised learning procedures are validated against a test set that is assumed to have come from the same distribution as the training data. However, in many problems, the test data may have come from a different distribution. We consider the case of having many labeled observations from one distribution, $P_1$, and making predictions at unlabeled points that come from $P_2$. We combine the high predictive accuracy of random forests (Breiman, 2001) with an importance sampling scheme, where the splits and predictions of the base-trees are done in a weighted manner, which we call Locally Optimized Random Forests. These weights correspond to a non-parametric estimate of the likelihood ratio between the training and test distributions. To estimate these ratios with an unlabeled test set, we make the covariate shift assumption, where the differences in distribution are only a function of the training distributions (Shimodaira, 2000.) This methodology is motivated by the problem of forecasting power outages during hurricanes. The extreme nature of the most devastating hurricanes means that typical validation set ups will overly favor less extreme storms. Our method provides a data-driven means of adapting a machine learning method to deal with extreme events.
Semiparametric Classification of Forest Graphical Models
Jun 06, 2018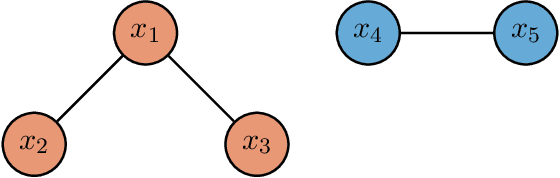

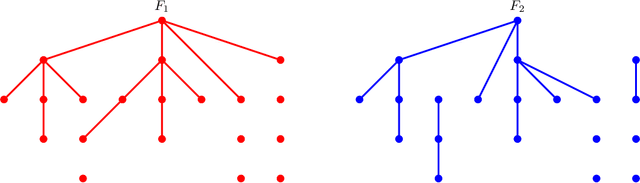
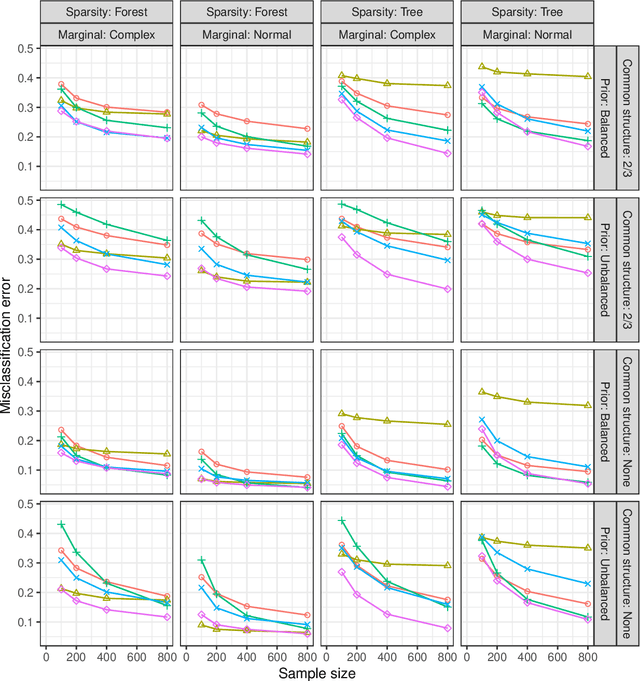
We propose a new semiparametric approach to binary classification that exploits the modeling flexibility of sparse graphical models. Specifically, we assume that each class can be represented by a forest-structured graphical model. Under this assumption, the optimal classifier is linear in the log of the one- and two-dimensional marginal densities. Our proposed procedure non-parametrically estimates the univariate and bivariate marginal densities, maps each sample to the logarithm of these estimated densities and constructs a linear SVM in the transformed space. We prove convergence of the resulting classifier to an oracle SVM classifier and give finite sample bounds on its excess risk. Experiments with simulated and real data indicate that the resulting classifier is competitive with several popular methods across a range of applications.