 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSubmodular Streaming in All its Glory: Tight Approximation, Minimum Memory and Low Adaptive Complexity
May 13, 2019
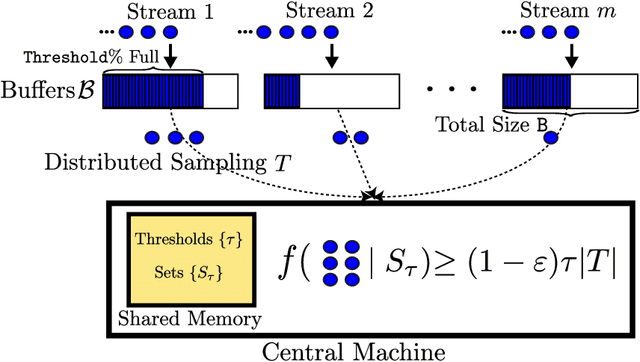
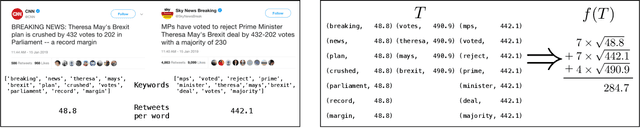

Streaming algorithms are generally judged by the quality of their solution, memory footprint, and computational complexity. In this paper, we study the problem of maximizing a monotone submodular function in the streaming setting with a cardinality constraint $k$. We first propose Sieve-Streaming++, which requires just one pass over the data, keeps only $O(k)$ elements and achieves the tight $(1/2)$-approximation guarantee. The best previously known streaming algorithms either achieve a suboptimal $(1/4)$-approximation with $\Theta(k)$ memory or the optimal $(1/2)$-approximation with $O(k\log k)$ memory. Next, we show that by buffering a small fraction of the stream and applying a careful filtering procedure, one can heavily reduce the number of adaptive computational rounds, thus substantially lowering the computational complexity of Sieve-Streaming++. We then generalize our results to the more challenging multi-source streaming setting. We show how one can achieve the tight $(1/2)$-approximation guarantee with $O(k)$ shared memory while minimizing not only the required rounds of computations but also the total number of communicated bits. Finally, we demonstrate the efficiency of our algorithms on real-world data summarization tasks for multi-source streams of tweets and of YouTube videos.
Adaptive Sequence Submodularity
Feb 15, 2019

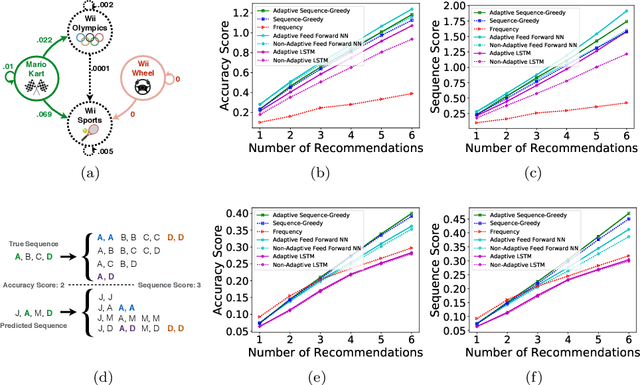
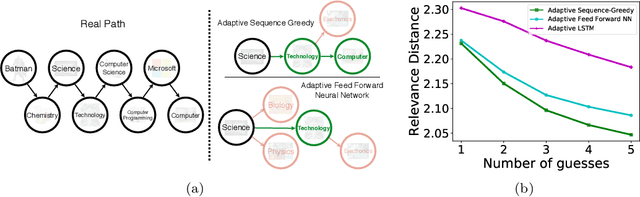
In many machine learning applications, one needs to interactively select a sequence of items (e.g., recommending movies based on a user's feedback) or make sequential decisions in certain orders (e.g., guiding an agent through a series of states). Not only do sequences already pose a dauntingly large search space, but we must take into account past observations, as well as the uncertainty of future outcomes. Without further structure, finding an optimal sequence is notoriously challenging, if not completely intractable. In this paper, we introduce adaptive sequence submodularity, a rich framework that generalizes the notion of submodularity to adaptive policies that explicitly consider sequential dependencies between items. We show that once such dependencies are encoded by a directed graph, an adaptive greedy policy is guaranteed to achieve a constant factor approximation guarantee, where the constant naturally depends on the structural properties of the underlying graph. Additionally, to demonstrate the practical utility of our results, we run experiments on Amazon product recommendation and Wikipedia link prediction tasks.
Data Summarization at Scale: A Two-Stage Submodular Approach
Jun 07, 2018
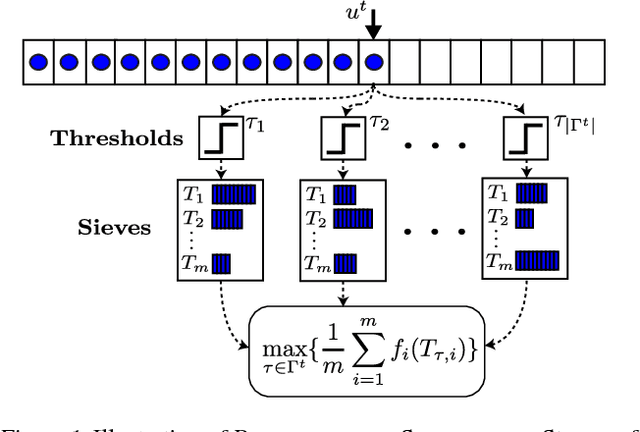
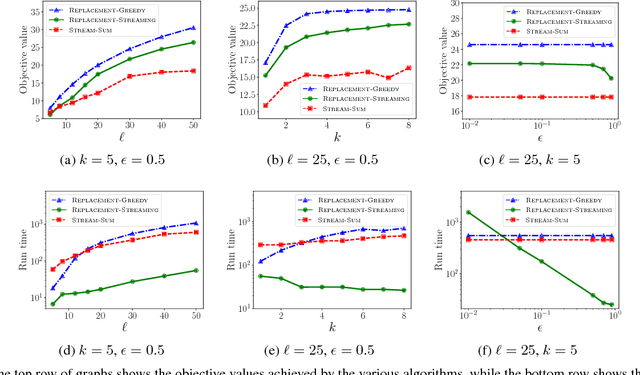

The sheer scale of modern datasets has resulted in a dire need for summarization techniques that identify representative elements in a dataset. Fortunately, the vast majority of data summarization tasks satisfy an intuitive diminishing returns condition known as submodularity, which allows us to find nearly-optimal solutions in linear time. We focus on a two-stage submodular framework where the goal is to use some given training functions to reduce the ground set so that optimizing new functions (drawn from the same distribution) over the reduced set provides almost as much value as optimizing them over the entire ground set. In this paper, we develop the first streaming and distributed solutions to this problem. In addition to providing strong theoretical guarantees, we demonstrate both the utility and efficiency of our algorithms on real-world tasks including image summarization and ride-share optimization.