 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOrganizational Governance of Emerging Technologies: AI Adoption in Healthcare
May 10, 2023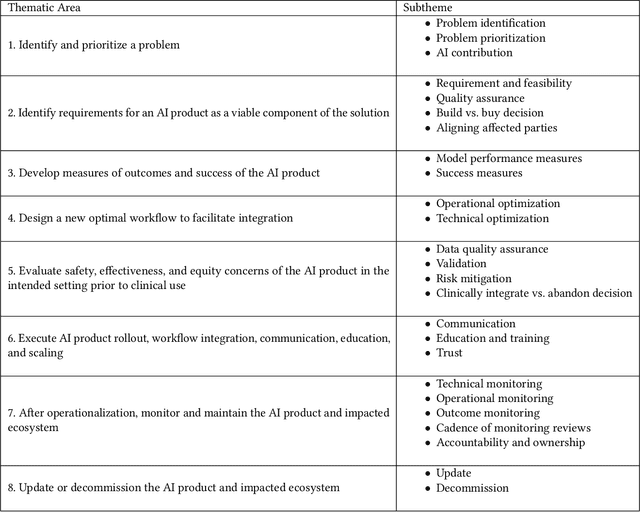
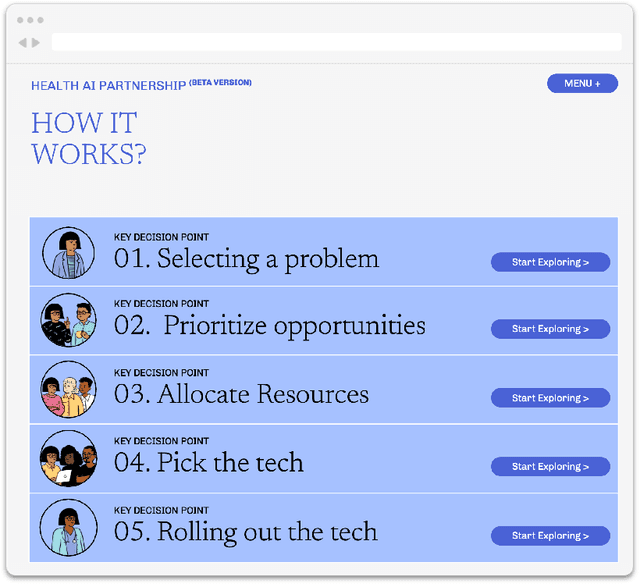

Private and public sector structures and norms refine how emerging technology is used in practice. In healthcare, despite a proliferation of AI adoption, the organizational governance surrounding its use and integration is often poorly understood. What the Health AI Partnership (HAIP) aims to do in this research is to better define the requirements for adequate organizational governance of AI systems in healthcare settings and support health system leaders to make more informed decisions around AI adoption. To work towards this understanding, we first identify how the standards for the AI adoption in healthcare may be designed to be used easily and efficiently. Then, we map out the precise decision points involved in the practical institutional adoption of AI technology within specific health systems. Practically, we achieve this through a multi-organizational collaboration with leaders from major health systems across the United States and key informants from related fields. Working with the consultancy IDEO [dot] org, we were able to conduct usability-testing sessions with healthcare and AI ethics professionals. Usability analysis revealed a prototype structured around mock key decision points that align with how organizational leaders approach technology adoption. Concurrently, we conducted semi-structured interviews with 89 professionals in healthcare and other relevant fields. Using a modified grounded theory approach, we were able to identify 8 key decision points and comprehensive procedures throughout the AI adoption lifecycle. This is one of the most detailed qualitative analyses to date of the current governance structures and processes involved in AI adoption by health systems in the United States. We hope these findings can inform future efforts to build capabilities to promote the safe, effective, and responsible adoption of emerging technologies in healthcare.
Development and Validation of ML-DQA -- a Machine Learning Data Quality Assurance Framework for Healthcare
Aug 04, 2022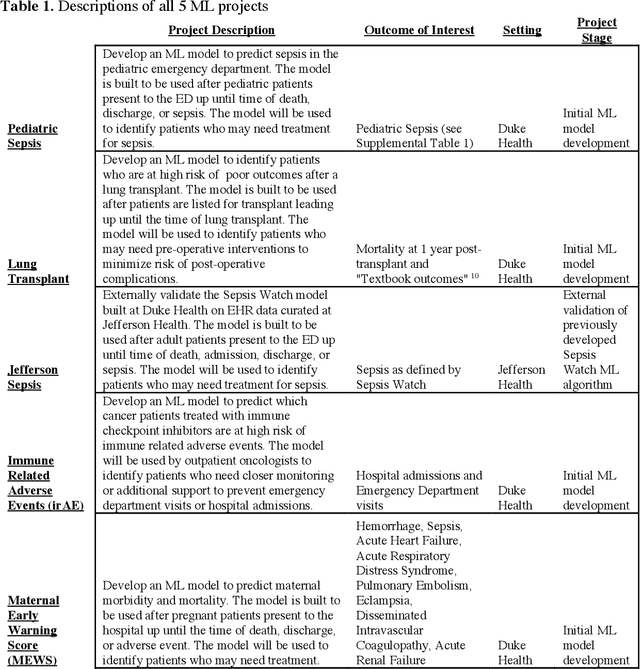
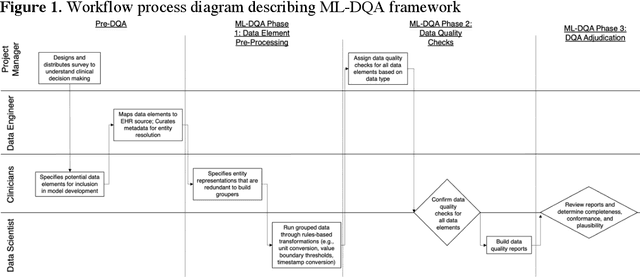
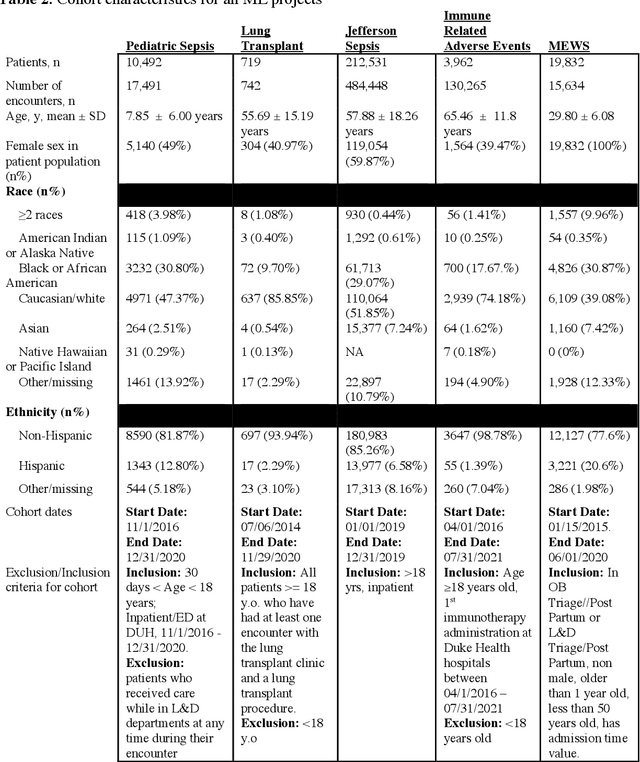
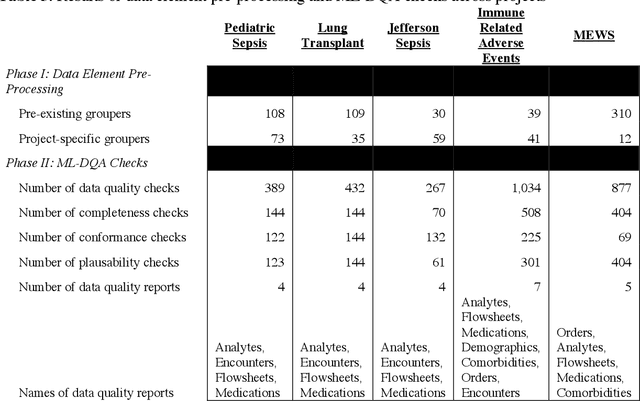
The approaches by which the machine learning and clinical research communities utilize real world data (RWD), including data captured in the electronic health record (EHR), vary dramatically. While clinical researchers cautiously use RWD for clinical investigations, ML for healthcare teams consume public datasets with minimal scrutiny to develop new algorithms. This study bridges this gap by developing and validating ML-DQA, a data quality assurance framework grounded in RWD best practices. The ML-DQA framework is applied to five ML projects across two geographies, different medical conditions, and different cohorts. A total of 2,999 quality checks and 24 quality reports were generated on RWD gathered on 247,536 patients across the five projects. Five generalizable practices emerge: all projects used a similar method to group redundant data element representations; all projects used automated utilities to build diagnosis and medication data elements; all projects used a common library of rules-based transformations; all projects used a unified approach to assign data quality checks to data elements; and all projects used a similar approach to clinical adjudication. An average of 5.8 individuals, including clinicians, data scientists, and trainees, were involved in implementing ML-DQA for each project and an average of 23.4 data elements per project were either transformed or removed in response to ML-DQA. This study demonstrates the importance role of ML-DQA in healthcare projects and provides teams a framework to conduct these essential activities.
"The Human Body is a Black Box": Supporting Clinical Decision-Making with Deep Learning
Dec 07, 2019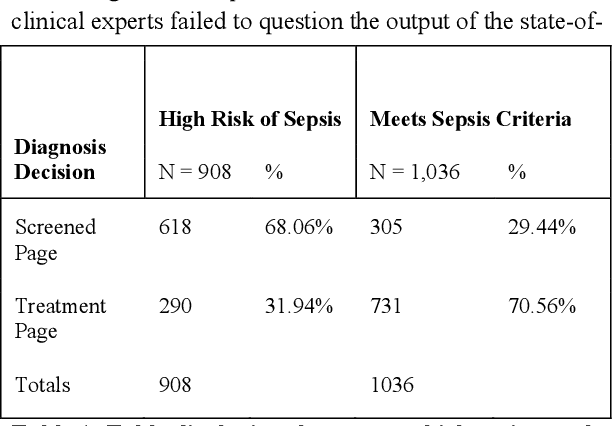
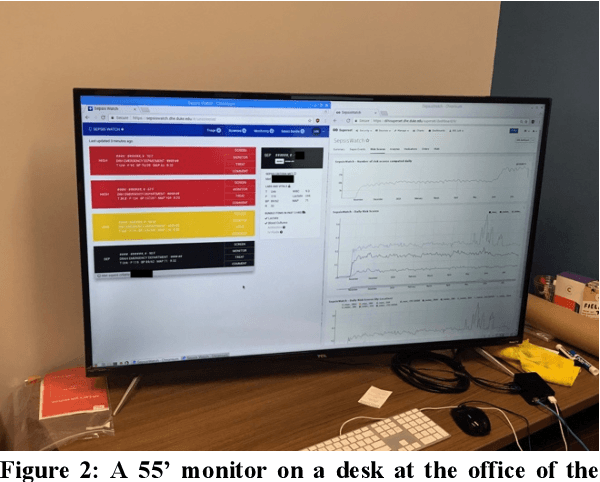
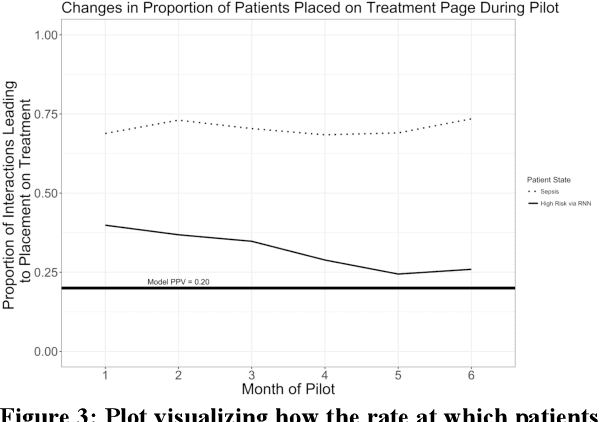
Machine learning technologies are increasingly developed for use in healthcare. While research communities have focused on creating state-of-the-art models, there has been less focus on real world implementation and the associated challenges to accuracy, fairness, accountability, and transparency that come from actual, situated use. Serious questions remain under examined regarding how to ethically build models, interpret and explain model output, recognize and account for biases, and minimize disruptions to professional expertise and work cultures. We address this gap in the literature and provide a detailed case study covering the development, implementation, and evaluation of Sepsis Watch, a machine learning-driven tool that assists hospital clinicians in the early diagnosis and treatment of sepsis. We, the team that developed and evaluated the tool, discuss our conceptualization of the tool not as a model deployed in the world but instead as a socio-technical system requiring integration into existing social and professional contexts. Rather than focusing on model interpretability to ensure a fair and accountable machine learning, we point toward four key values and practices that should be considered when developing machine learning to support clinical decision-making: rigorously define the problem in context, build relationships with stakeholders, respect professional discretion, and create ongoing feedback loops with stakeholders. Our work has significant implications for future research regarding mechanisms of institutional accountability and considerations for designing machine learning systems. Our work underscores the limits of model interpretability as a solution to ensure transparency, accuracy, and accountability in practice. Instead, our work demonstrates other means and goals to achieve FATML values in design and in practice.
An Improved Multi-Output Gaussian Process RNN with Real-Time Validation for Early Sepsis Detection
Aug 19, 2017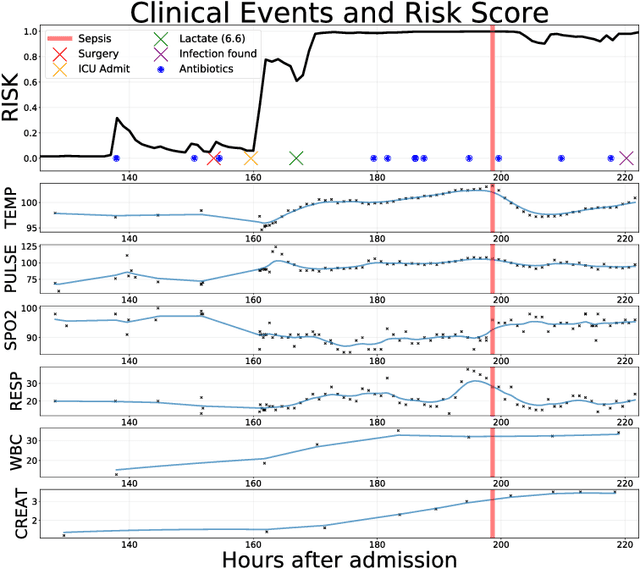
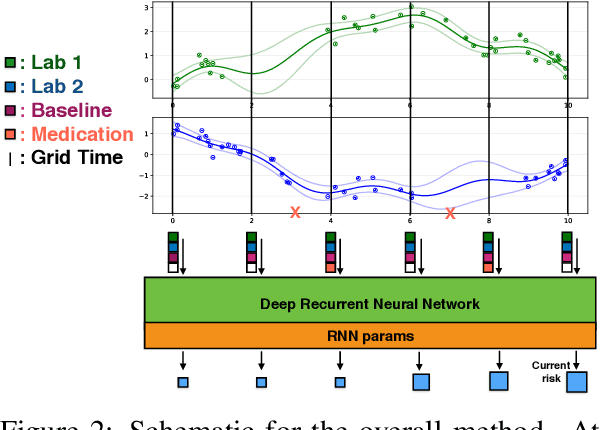
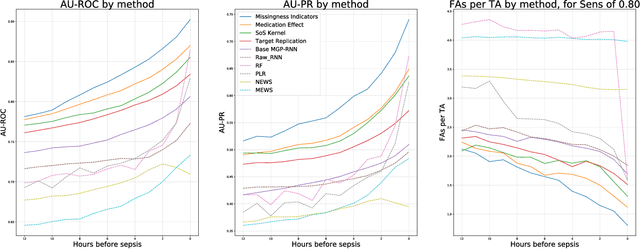
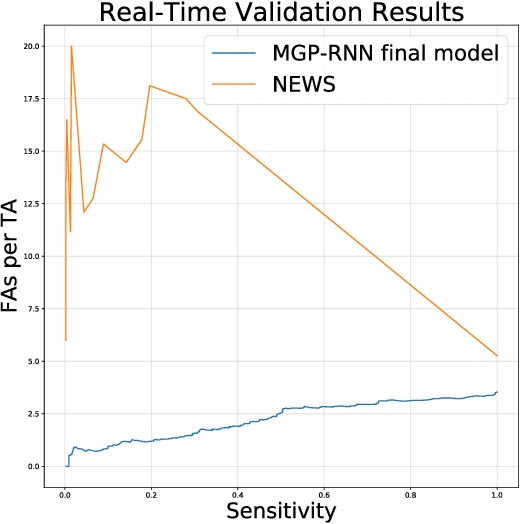
Sepsis is a poorly understood and potentially life-threatening complication that can occur as a result of infection. Early detection and treatment improves patient outcomes, and as such it poses an important challenge in medicine. In this work, we develop a flexible classifier that leverages streaming lab results, vitals, and medications to predict sepsis before it occurs. We model patient clinical time series with multi-output Gaussian processes, maintaining uncertainty about the physiological state of a patient while also imputing missing values. The mean function takes into account the effects of medications administered on the trajectories of the physiological variables. Latent function values from the Gaussian process are then fed into a deep recurrent neural network to classify patient encounters as septic or not, and the overall model is trained end-to-end using back-propagation. We train and validate our model on a large dataset of 18 months of heterogeneous inpatient stays from the Duke University Health System, and develop a new "real-time" validation scheme for simulating the performance of our model as it will actually be used. Our proposed method substantially outperforms clinical baselines, and improves on a previous related model for detecting sepsis. Our model's predictions will be displayed in a real-time analytics dashboard to be used by a sepsis rapid response team to help detect and improve treatment of sepsis.
Scalable Modeling of Multivariate Longitudinal Data for Prediction of Chronic Kidney Disease Progression
Aug 16, 2016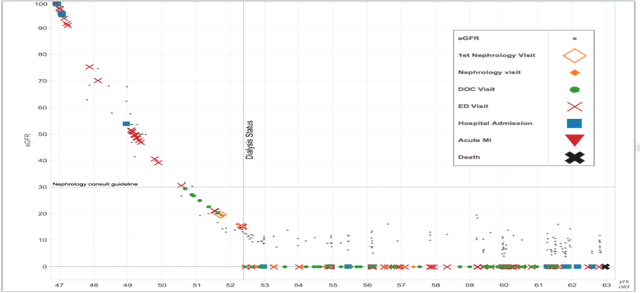
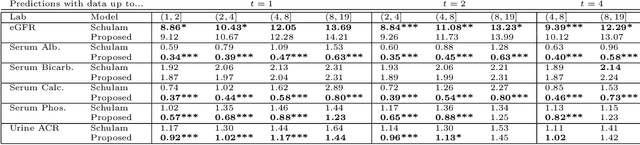
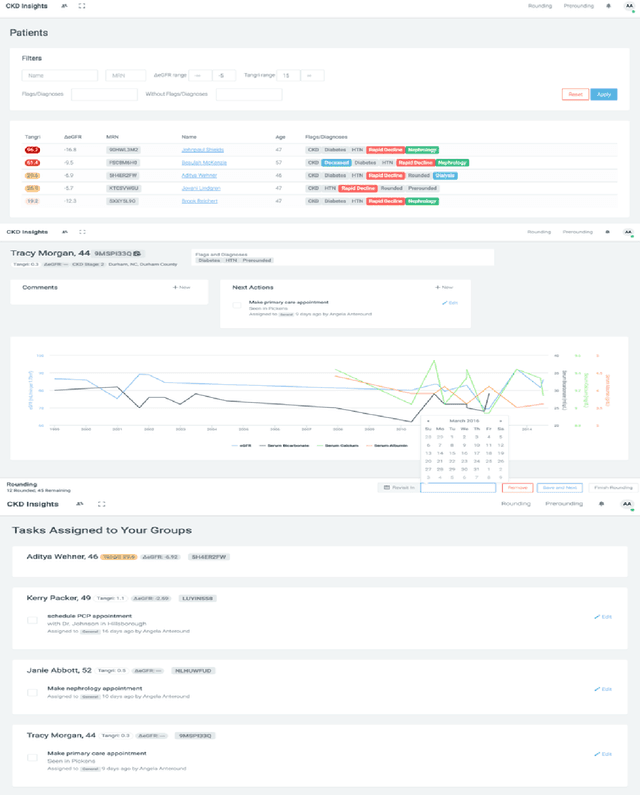
Prediction of the future trajectory of a disease is an important challenge for personalized medicine and population health management. However, many complex chronic diseases exhibit large degrees of heterogeneity, and furthermore there is not always a single readily available biomarker to quantify disease severity. Even when such a clinical variable exists, there are often additional related biomarkers routinely measured for patients that may better inform the predictions of their future disease state. To this end, we propose a novel probabilistic generative model for multivariate longitudinal data that captures dependencies between multivariate trajectories. We use a Gaussian process based regression model for each individual trajectory, and build off ideas from latent class models to induce dependence between their mean functions. We fit our method using a scalable variational inference algorithm to a large dataset of longitudinal electronic patient health records, and find that it improves dynamic predictions compared to a recent state of the art method. Our local accountable care organization then uses the model predictions during chart reviews of high risk patients with chronic kidney disease.