 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Much Do Unstated Problem Constraints Limit Deep Robotic Reinforcement Learning?
Sep 20, 2019

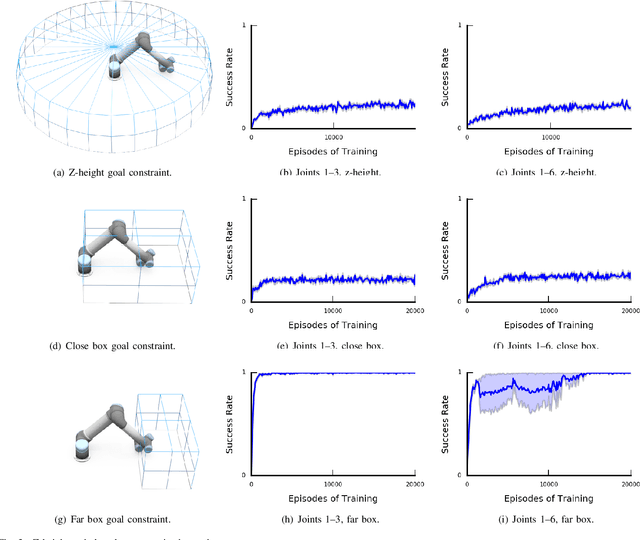

Deep Reinforcement Learning is a promising paradigm for robotic control which has been shown to be capable of learning policies for high-dimensional, continuous control of unmodeled systems. However, RoboticReinforcement Learning currently lacks clearly defined benchmark tasks, which makes it difficult for researchers to reproduce and compare against prior work. ``Reacher'' tasks, which are fundamental to robotic manipulation, are commonly used as benchmarks, but the lack of a formal specification elides details that are crucial to replication. In this paper we present a novel empirical analysis which shows that the unstated spatial constraints in commonly used implementations of Reacher tasks make it dramatically easier to learn a successful control policy with DeepDeterministic Policy Gradients (DDPG), a state-of-the-art Deep RL algorithm. Our analysis suggests that less constrained Reacher tasks are significantly more difficult to learn, and hence that existing de facto benchmarks are not representative of the difficulty of general robotic manipulation.
Randomized Physics-based Motion Planning for Grasping in Cluttered and Uncertain Environments
Nov 27, 2017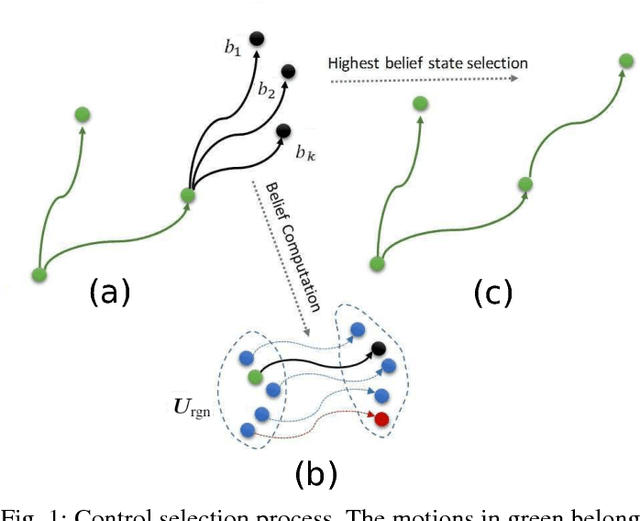
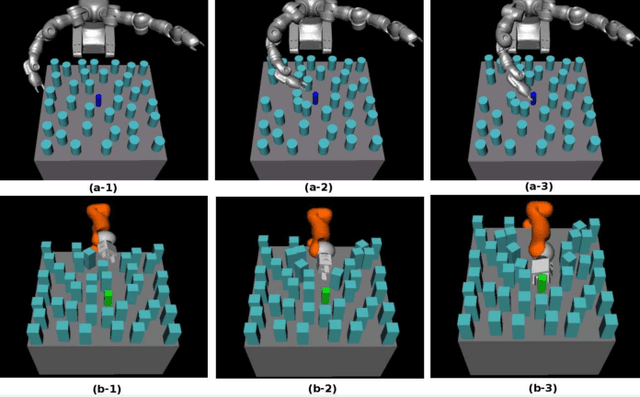
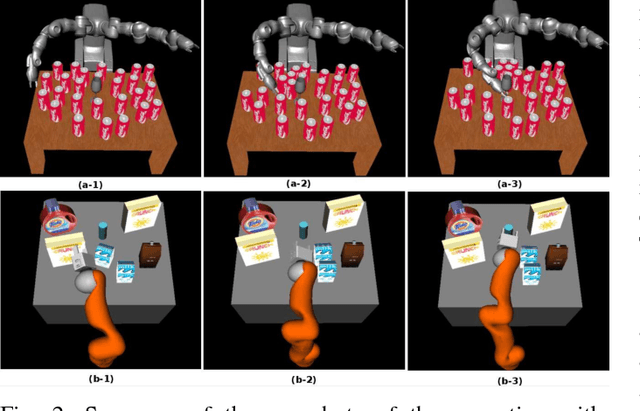

Planning motions to grasp an object in cluttered and uncertain environments is a challenging task, particularly when a collision-free trajectory does not exist and objects obstructing the way are required to be carefully grasped and moved out. This paper takes a different approach and proposes to address this problem by using a randomized physics-based motion planner that permits robot-object and object-object interactions. The main idea is to avoid an explicit high-level reasoning of the task by providing the motion planner with a physics engine to evaluate possible complex multi-body dynamical interactions. The approach is able to solve the problem in complex scenarios, also considering uncertainty in the objects pose and in the contact dynamics. The work enhances the state validity checker, the control sampler and the tree exploration strategy of a kinodynamic motion planner called KPIECE. The enhanced algorithm, called p-KPIECE, has been validated in simulation and with real experiments. The results have been compared with an ontological physics-based motion planner and with task and motion planning approaches, resulting in a significant improvement in terms of planning time, success rate and quality of the solution path.
An Extensible Benchmarking Infrastructure for Motion Planning Algorithms
Dec 20, 2014



Sampling-based planning algorithms are the most common probabilistically complete algorithms and are widely used on many robot platforms. Within this class of algorithms, many variants have been proposed over the last 20 years, yet there is still no characterization of which algorithms are well-suited for which classes of problems. This has motivated us to develop a benchmarking infrastructure for motion planning algorithms. It consists of three main components. First, we have created an extensive benchmarking software framework that is included with the Open Motion Planning Library (OMPL), a C++ library that contains implementations of many sampling-based algorithms. Second, we have defined extensible formats for storing benchmark results. The formats are fairly straightforward so that other planning libraries could easily produce compatible output. Finally, we have created an interactive, versatile visualization tool for compact presentation of collected benchmark data. The tool and underlying database facilitate the analysis of performance across benchmark problems and planners.
Experience-Based Planning with Sparse Roadmap Spanners
Oct 08, 2014



We present an experienced-based planning framework called Thunder that learns to reduce computation time required to solve high-dimensional planning problems in varying environments. The approach is especially suited for large configuration spaces that include many invariant constraints, such as those found with whole body humanoid motion planning. Experiences are generated using probabilistic sampling and stored in a sparse roadmap spanner (SPARS), which provides asymptotically near-optimal coverage of the configuration space, making storing, retrieving, and repairing past experiences very efficient with respect to memory and time. The Thunder framework improves upon past experience-based planners by storing experiences in a graph rather than in individual paths, eliminating redundant information, providing more opportunities for path reuse, and providing a theoretical limit to the size of the experience graph. These properties also lead to improved handling of dynamically changing environments, reasoning about optimal paths, and reducing query resolution time. The approach is demonstrated on a 30 degrees of freedom humanoid robot and compared with the Lightning framework, an experience-based planner that uses individual paths to store past experiences. In environments with variable obstacles and stability constraints, experiments show that Thunder is on average an order of magnitude faster than Lightning and planning from scratch. Thunder also uses 98.8% less memory to store its experiences after 10,000 trials when compared to Lightning. Our framework is implemented and freely available in the Open Motion Planning Library.