 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Much Do Unstated Problem Constraints Limit Deep Robotic Reinforcement Learning?
Paper and Code


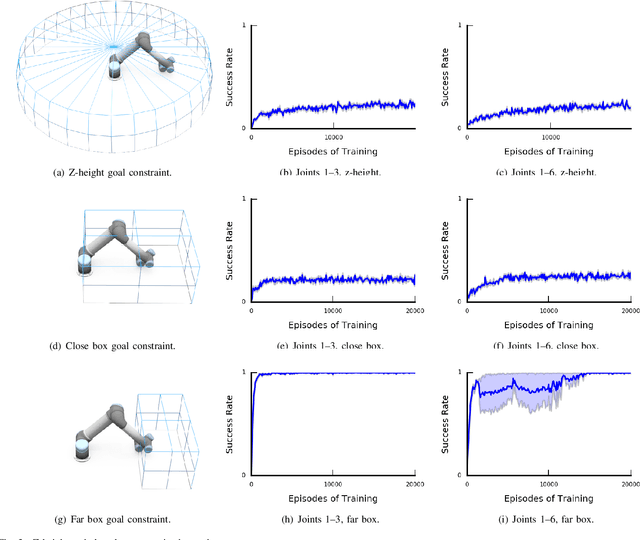

Deep Reinforcement Learning is a promising paradigm for robotic control which has been shown to be capable of learning policies for high-dimensional, continuous control of unmodeled systems. However, RoboticReinforcement Learning currently lacks clearly defined benchmark tasks, which makes it difficult for researchers to reproduce and compare against prior work. ``Reacher'' tasks, which are fundamental to robotic manipulation, are commonly used as benchmarks, but the lack of a formal specification elides details that are crucial to replication. In this paper we present a novel empirical analysis which shows that the unstated spatial constraints in commonly used implementations of Reacher tasks make it dramatically easier to learn a successful control policy with DeepDeterministic Policy Gradients (DDPG), a state-of-the-art Deep RL algorithm. Our analysis suggests that less constrained Reacher tasks are significantly more difficult to learn, and hence that existing de facto benchmarks are not representative of the difficulty of general robotic manipulation.