 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQFT: Post-training quantization via fast joint finetuning of all degrees of freedom
Dec 05, 2022The post-training quantization (PTQ) challenge of bringing quantized neural net accuracy close to original has drawn much attention driven by industry demand. Many of the methods emphasize optimization of a specific degree-of-freedom (DoF), such as quantization step size, preconditioning factors, bias fixing, often chained to others in multi-step solutions. Here we rethink quantized network parameterization in HW-aware fashion, towards a unified analysis of all quantization DoF, permitting for the first time their joint end-to-end finetuning. Our single-step simple and extendable method, dubbed quantization-aware finetuning (QFT), achieves 4-bit weight quantization results on-par with SoTA within PTQ constraints of speed and resource.
Tiled Squeeze-and-Excite: Channel Attention With Local Spatial Context
Jul 05, 2021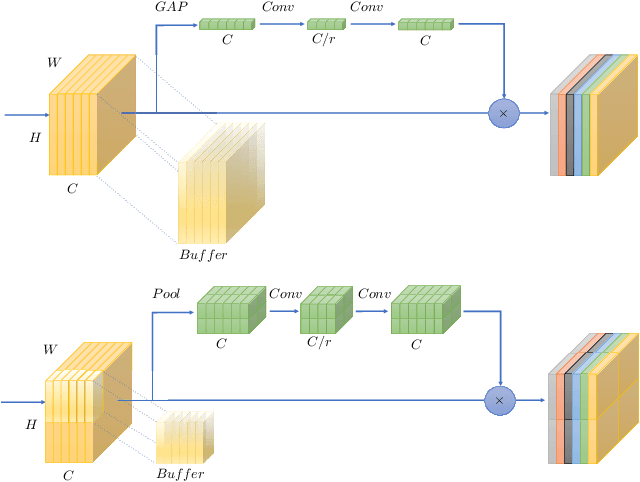
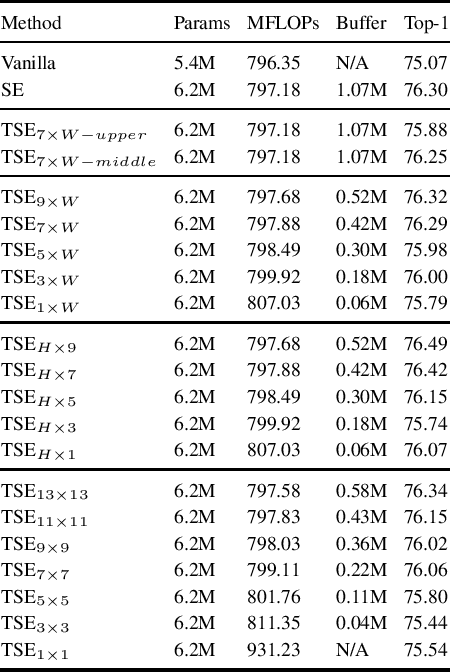
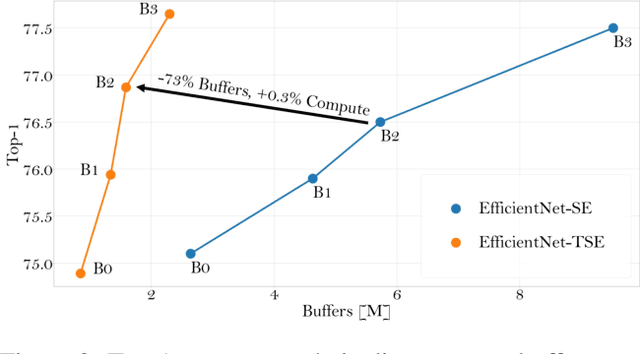
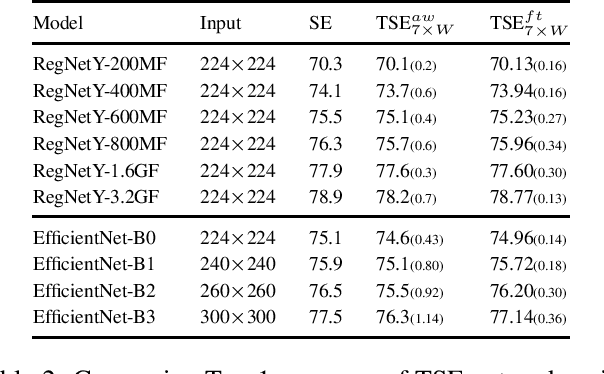
In this paper we investigate the amount of spatial context required for channel attention. To this end we study the popular squeeze-and-excite (SE) block which is a simple and lightweight channel attention mechanism. SE blocks and its numerous variants commonly use global average pooling (GAP) to create a single descriptor for each channel. Here, we empirically analyze the amount of spatial context needed for effective channel attention and find that limited localcontext on the order of seven rows or columns of the original image is sufficient to match the performance of global context. We propose tiled squeeze-and-excite (TSE), which is a framework for building SE-like blocks that employ several descriptors per channel, with each descriptor based on local context only. We further show that TSE is a drop-in replacement for the SE block and can be used in existing SE networks without re-training. This implies that local context descriptors are similar both to each other and to the global context descriptor. Finally, we show that TSE has important practical implications for deployment of SE-networks to dataflow AI accelerators due to their reduced pipeline buffering requirements. For example, using TSE reduces the amount of activation pipeline buffering in EfficientDetD2 by 90% compared to SE (from 50M to 4.77M) without loss of accuracy. Our code and pre-trained models will be publicly available.
Exploring Neural Networks Quantization via Layer-Wise Quantization Analysis
Dec 15, 2020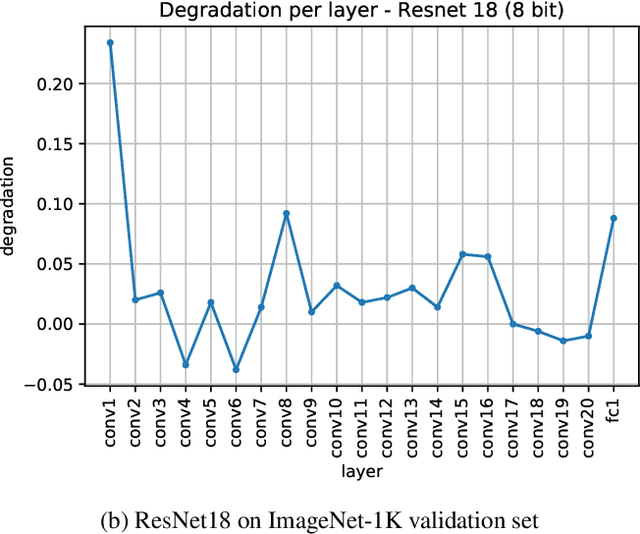
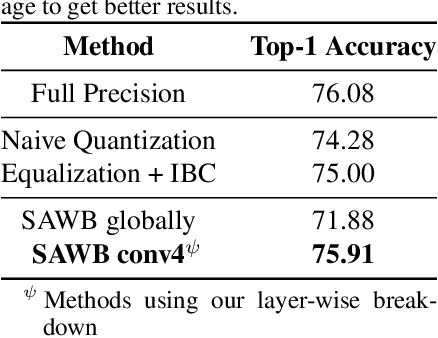
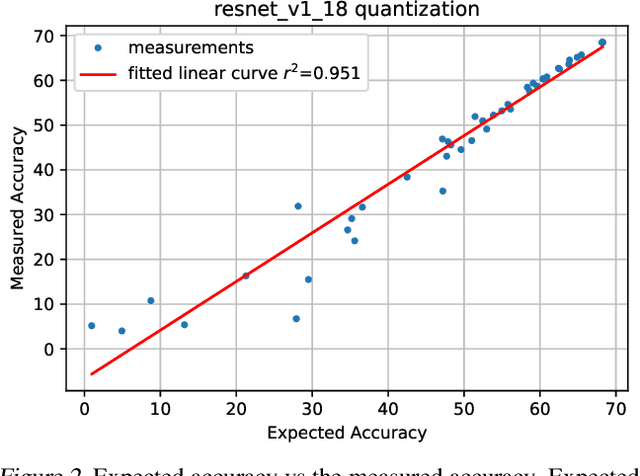
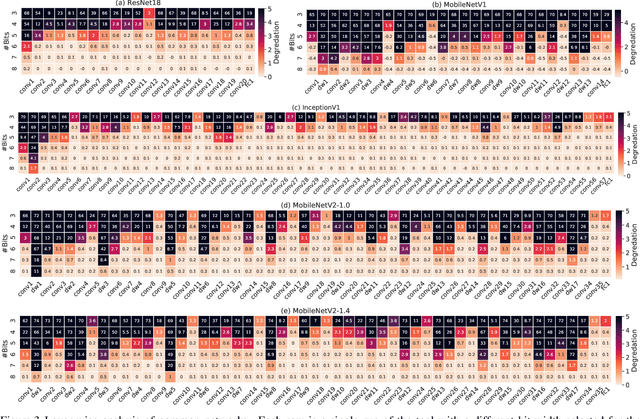
Quantization is an essential step in the efficient deployment of deep learning models and as such is an increasingly popular research topic. An important practical aspect that is not addressed in the current literature is how to analyze and fix fail cases where the use of quantization results in excessive degradation. In this paper, we present a simple analytic framework that breaks down overall degradation to its per layer contributions. We analyze many common networks and observe that a layer's contribution is determined by both intrinsic (local) factors - the distribution of the layer's weights and activations - and extrinsic (global) factors having to do with the the interaction with the rest of the layers. Layer-wise analysis of existing quantization schemes reveals local fail-cases of existing techniques which are not reflected when inspecting their overall performance. As an example, we consider ResNext26 on which SoTA post-training quantization methods perform poorly. We show that almost all of the degradation stems from a single layer. The same analysis also allows for local fixes - applying a common weight clipping heuristic only to this layer reduces degradation to a minimum while applying the same heuristic globally results in high degradation. More generally, layer-wise analysis allows for a more nuanced examination of how quantization affects the network, enabling the design of better performing schemes.
Fighting Quantization Bias With Bias
Jun 07, 2019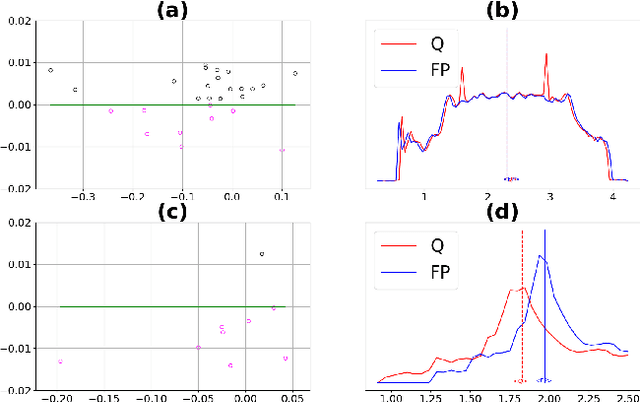
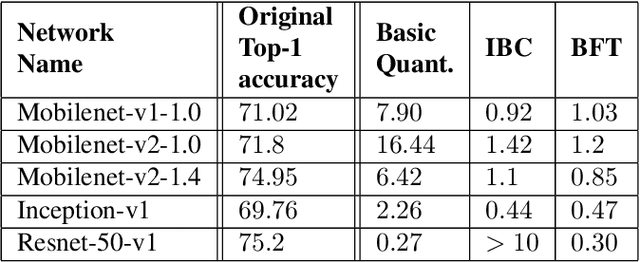
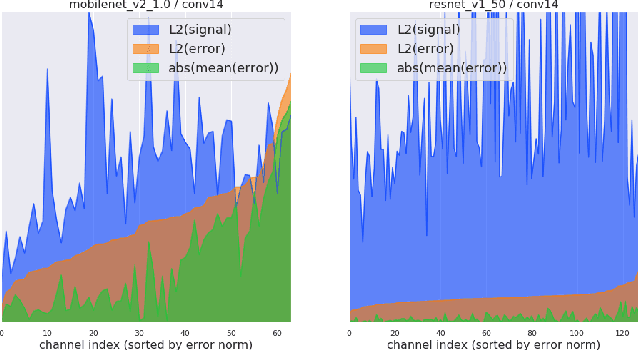
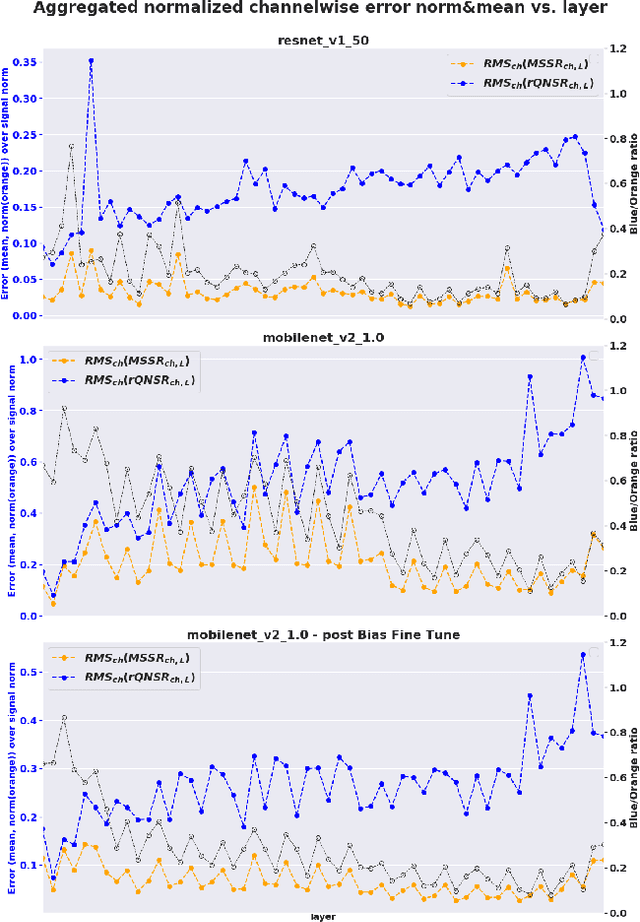
Low-precision representation of deep neural networks (DNNs) is critical for efficient deployment of deep learning application on embedded platforms, however, converting the network to low precision degrades its performance. Crucially, networks that are designed for embedded applications usually suffer from increased degradation since they have less redundancy. This is most evident for the ubiquitous MobileNet architecture which requires a costly quantization-aware training cycle to achieve acceptable performance when quantized to 8-bits. In this paper, we trace the source of the degradation in MobileNets to a shift in the mean activation value. This shift is caused by an inherent bias in the quantization process which builds up across layers, shifting all network statistics away from the learned distribution. We show that this phenomenon happens in other architectures as well. We propose a simple remedy - compensating for the quantization induced shift by adding a constant to the additive bias term of each channel. We develop two simple methods for estimating the correction constants - one using iterative evaluation of the quantized network and one where the constants are set using a short training phase. Both methods are fast and require only a small amount of unlabeled data, making them appealing for rapid deployment of neural networks. Using the above methods we are able to match the performance of training-based quantization of MobileNets at a fraction of the cost.
Same, Same But Different - Recovering Neural Network Quantization Error Through Weight Factorization
Feb 05, 2019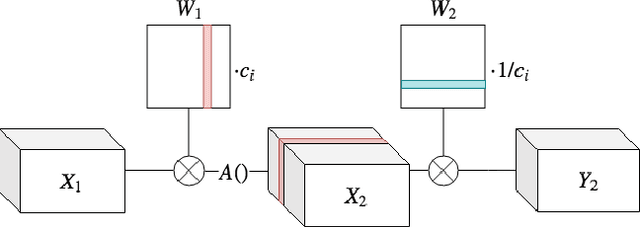
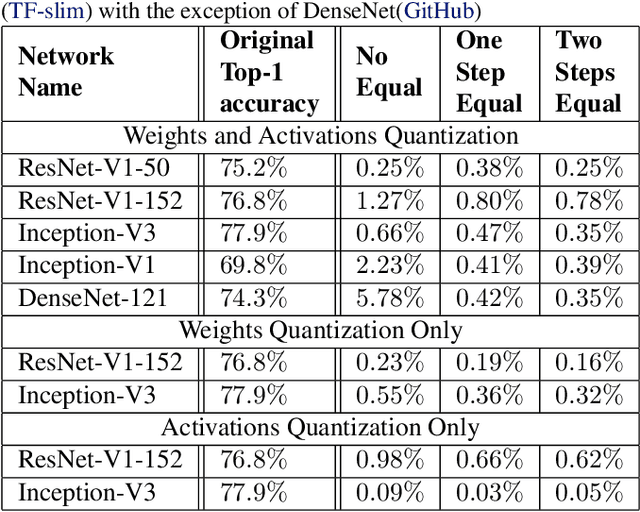
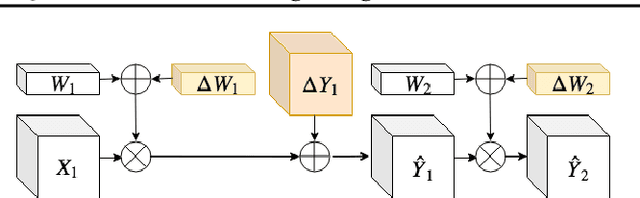
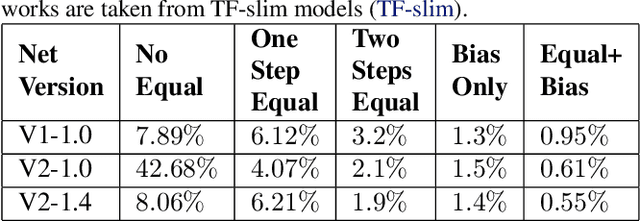
Quantization of neural networks has become common practice, driven by the need for efficient implementations of deep neural networks on embedded devices. In this paper, we exploit an oft-overlooked degree of freedom in most networks - for a given layer, individual output channels can be scaled by any factor provided that the corresponding weights of the next layer are inversely scaled. Therefore, a given network has many factorizations which change the weights of the network without changing its function. We present a conceptually simple and easy to implement method that uses this property and show that proper factorizations significantly decrease the degradation caused by quantization. We show improvement on a wide variety of networks and achieve state-of-the-art degradation results for MobileNets. While our focus is on quantization, this type of factorization is applicable to other domains such as network-pruning, neural nets regularization and network interpretability.