 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Neural Networks Quantization via Layer-Wise Quantization Analysis
Paper and Code
Dec 15, 2020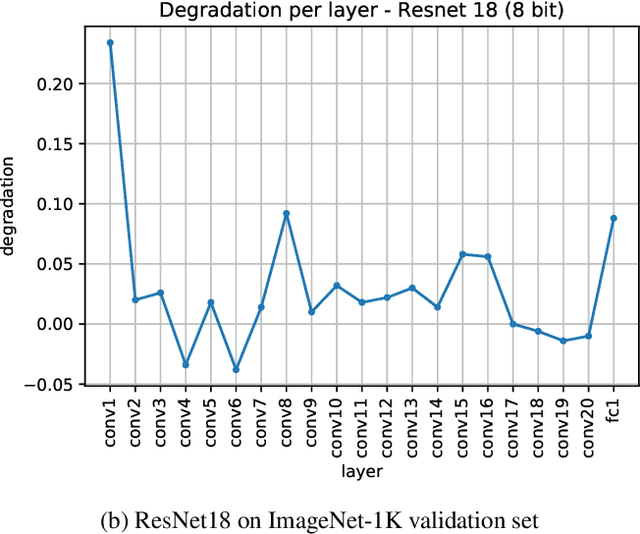
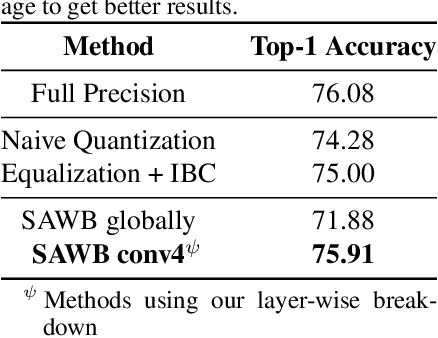
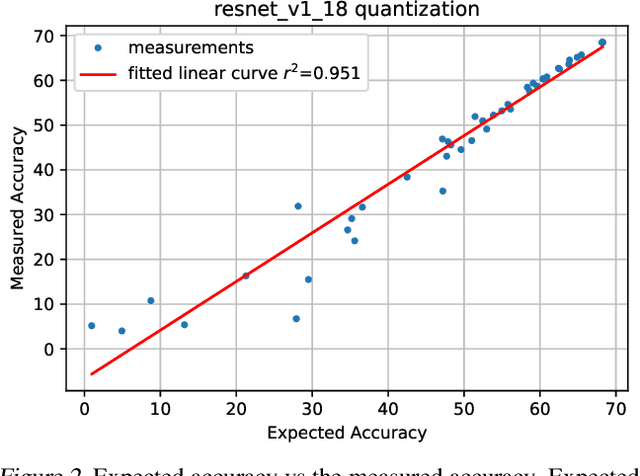
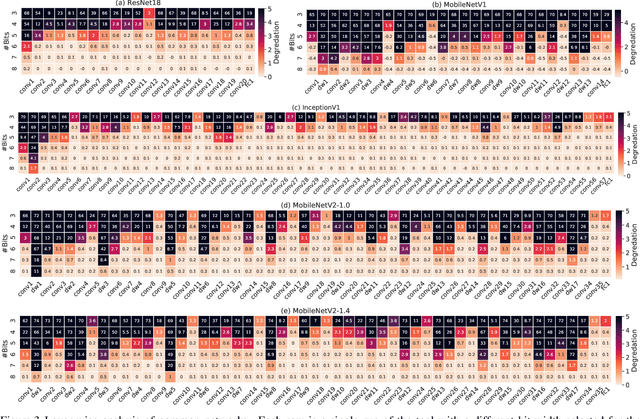
Quantization is an essential step in the efficient deployment of deep learning models and as such is an increasingly popular research topic. An important practical aspect that is not addressed in the current literature is how to analyze and fix fail cases where the use of quantization results in excessive degradation. In this paper, we present a simple analytic framework that breaks down overall degradation to its per layer contributions. We analyze many common networks and observe that a layer's contribution is determined by both intrinsic (local) factors - the distribution of the layer's weights and activations - and extrinsic (global) factors having to do with the the interaction with the rest of the layers. Layer-wise analysis of existing quantization schemes reveals local fail-cases of existing techniques which are not reflected when inspecting their overall performance. As an example, we consider ResNext26 on which SoTA post-training quantization methods perform poorly. We show that almost all of the degradation stems from a single layer. The same analysis also allows for local fixes - applying a common weight clipping heuristic only to this layer reduces degradation to a minimum while applying the same heuristic globally results in high degradation. More generally, layer-wise analysis allows for a more nuanced examination of how quantization affects the network, enabling the design of better performing schemes.