 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTiled Squeeze-and-Excite: Channel Attention With Local Spatial Context
Paper and Code
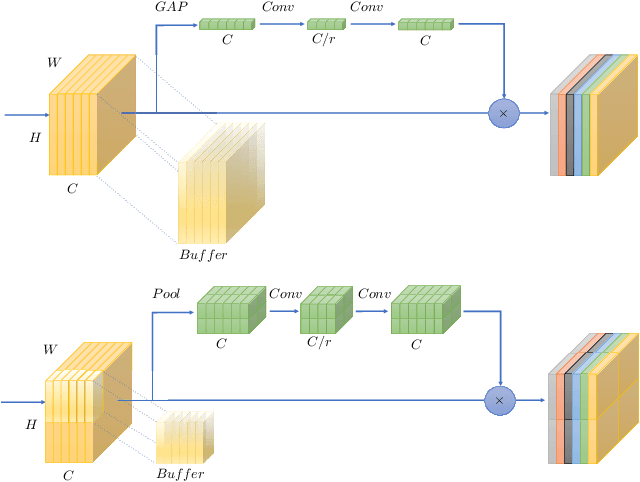
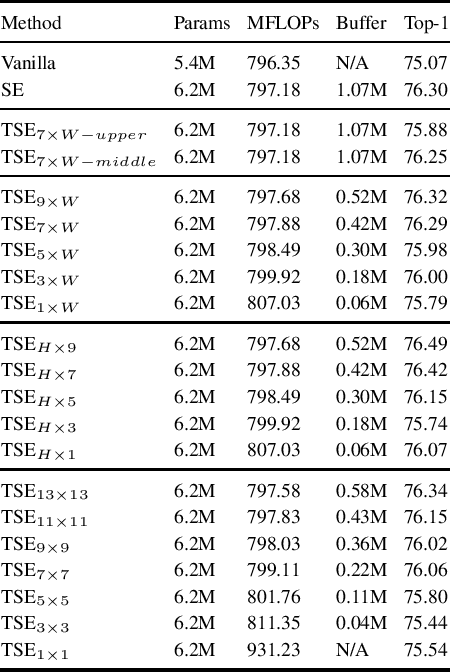
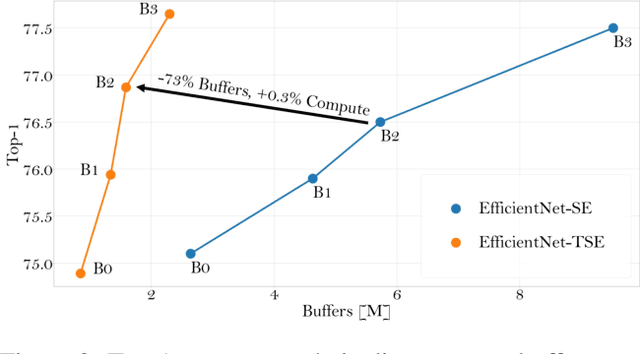
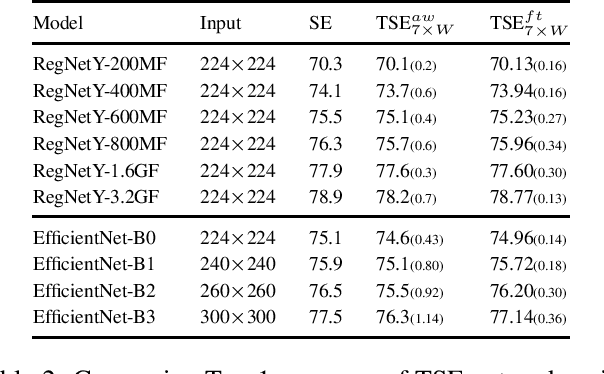
In this paper we investigate the amount of spatial context required for channel attention. To this end we study the popular squeeze-and-excite (SE) block which is a simple and lightweight channel attention mechanism. SE blocks and its numerous variants commonly use global average pooling (GAP) to create a single descriptor for each channel. Here, we empirically analyze the amount of spatial context needed for effective channel attention and find that limited localcontext on the order of seven rows or columns of the original image is sufficient to match the performance of global context. We propose tiled squeeze-and-excite (TSE), which is a framework for building SE-like blocks that employ several descriptors per channel, with each descriptor based on local context only. We further show that TSE is a drop-in replacement for the SE block and can be used in existing SE networks without re-training. This implies that local context descriptors are similar both to each other and to the global context descriptor. Finally, we show that TSE has important practical implications for deployment of SE-networks to dataflow AI accelerators due to their reduced pipeline buffering requirements. For example, using TSE reduces the amount of activation pipeline buffering in EfficientDetD2 by 90% compared to SE (from 50M to 4.77M) without loss of accuracy. Our code and pre-trained models will be publicly available.