 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQFT: Post-training quantization via fast joint finetuning of all degrees of freedom
Dec 05, 2022The post-training quantization (PTQ) challenge of bringing quantized neural net accuracy close to original has drawn much attention driven by industry demand. Many of the methods emphasize optimization of a specific degree-of-freedom (DoF), such as quantization step size, preconditioning factors, bias fixing, often chained to others in multi-step solutions. Here we rethink quantized network parameterization in HW-aware fashion, towards a unified analysis of all quantization DoF, permitting for the first time their joint end-to-end finetuning. Our single-step simple and extendable method, dubbed quantization-aware finetuning (QFT), achieves 4-bit weight quantization results on-par with SoTA within PTQ constraints of speed and resource.
Same, Same But Different - Recovering Neural Network Quantization Error Through Weight Factorization
Feb 05, 2019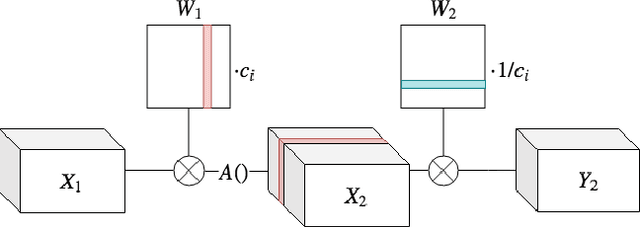
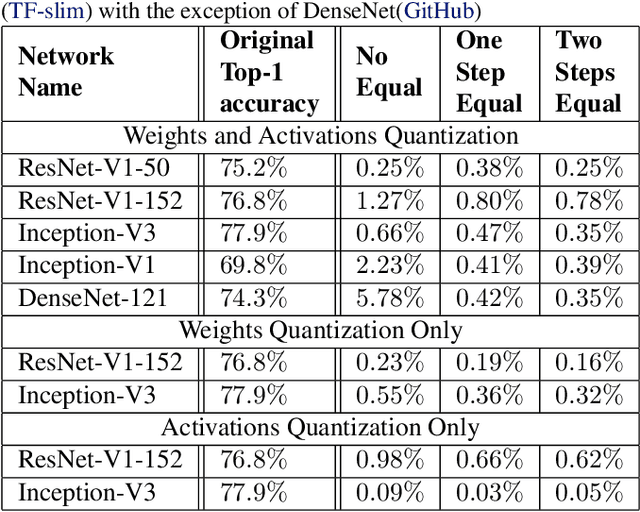
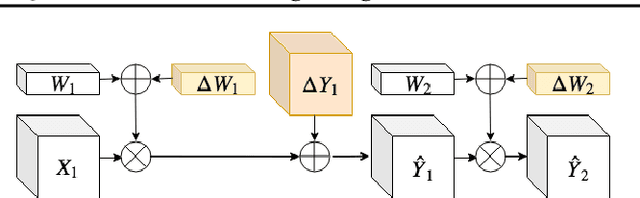
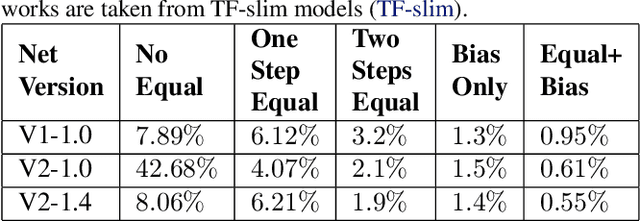
Quantization of neural networks has become common practice, driven by the need for efficient implementations of deep neural networks on embedded devices. In this paper, we exploit an oft-overlooked degree of freedom in most networks - for a given layer, individual output channels can be scaled by any factor provided that the corresponding weights of the next layer are inversely scaled. Therefore, a given network has many factorizations which change the weights of the network without changing its function. We present a conceptually simple and easy to implement method that uses this property and show that proper factorizations significantly decrease the degradation caused by quantization. We show improvement on a wide variety of networks and achieve state-of-the-art degradation results for MobileNets. While our focus is on quantization, this type of factorization is applicable to other domains such as network-pruning, neural nets regularization and network interpretability.