 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDIETA: A Decoder-only transformer-based model for Italian-English machine TrAnslation
Jan 25, 2026In this paper, we present DIETA, a small, decoder-only Transformer model with 0.5 billion parameters, specifically designed and trained for Italian-English machine translation. We collect and curate a large parallel corpus consisting of approximately 207 million Italian-English sentence pairs across diverse domains, including parliamentary proceedings, legal texts, web-crawled content, subtitles, news, literature and 352 million back-translated data using pretrained models. Additionally, we create and release a new small-scale evaluation set, consisting of 450 sentences, based on 2025 WikiNews articles, enabling assessment of translation quality on contemporary text. Comprehensive evaluations show that DIETA achieves competitive performance on multiple Italian-English benchmarks, consistently ranking in the second quartile of a 32-system leaderboard and outperforming most other sub-3B models on four out of five test suites. The training script, trained models, curated corpus, and newly introduced evaluation set are made publicly available, facilitating further research and development in specialized Italian-English machine translation. https://github.com/pkasela/DIETA-Machine-Translation
The Promise of Large Language Models in Digital Health: Evidence from Sentiment Analysis in Online Health Communities
Aug 19, 2025Digital health analytics face critical challenges nowadays. The sophisticated analysis of patient-generated health content, which contains complex emotional and medical contexts, requires scarce domain expertise, while traditional ML approaches are constrained by data shortage and privacy limitations in healthcare settings. Online Health Communities (OHCs) exemplify these challenges with mixed-sentiment posts, clinical terminology, and implicit emotional expressions that demand specialised knowledge for accurate Sentiment Analysis (SA). To address these challenges, this study explores how Large Language Models (LLMs) can integrate expert knowledge through in-context learning for SA, providing a scalable solution for sophisticated health data analysis. Specifically, we develop a structured codebook that systematically encodes expert interpretation guidelines, enabling LLMs to apply domain-specific knowledge through targeted prompting rather than extensive training. Six GPT models validated alongside DeepSeek and LLaMA 3.1 are compared with pre-trained language models (BioBERT variants) and lexicon-based methods, using 400 expert-annotated posts from two OHCs. LLMs achieve superior performance while demonstrating expert-level agreement. This high agreement, with no statistically significant difference from inter-expert agreement levels, suggests knowledge integration beyond surface-level pattern recognition. The consistent performance across diverse LLM models, supported by in-context learning, offers a promising solution for digital health analytics. This approach addresses the critical challenge of expert knowledge shortage in digital health research, enabling real-time, expert-quality analysis for patient monitoring, intervention assessment, and evidence-based health strategies.
Reasoning Capabilities and Invariability of Large Language Models
May 01, 2025Large Language Models (LLMs) have shown remarkable capabilities in manipulating natural language across multiple applications, but their ability to handle simple reasoning tasks is often questioned. In this work, we aim to provide a comprehensive analysis of LLMs' reasoning competence, specifically focusing on their prompt dependency. In particular, we introduce a new benchmark dataset with a series of simple reasoning questions demanding shallow logical reasoning. Aligned with cognitive psychology standards, the questions are confined to a basic domain revolving around geometric figures, ensuring that responses are independent of any pre-existing intuition about the world and rely solely on deduction. An empirical analysis involving zero-shot and few-shot prompting across 24 LLMs of different sizes reveals that, while LLMs with over 70 billion parameters perform better in the zero-shot setting, there is still a large room for improvement. An additional test with chain-of-thought prompting over 22 LLMs shows that this additional prompt can aid or damage the performance of models, depending on whether the rationale is required before or after the answer.
Enhancing Health Information Retrieval with RAG by Prioritizing Topical Relevance and Factual Accuracy
Feb 07, 2025The exponential surge in online health information, coupled with its increasing use by non-experts, highlights the pressing need for advanced Health Information Retrieval models that consider not only topical relevance but also the factual accuracy of the retrieved information, given the potential risks associated with health misinformation. To this aim, this paper introduces a solution driven by Retrieval-Augmented Generation (RAG), which leverages the capabilities of generative Large Language Models (LLMs) to enhance the retrieval of health-related documents grounded in scientific evidence. In particular, we propose a three-stage model: in the first stage, the user's query is employed to retrieve topically relevant passages with associated references from a knowledge base constituted by scientific literature. In the second stage, these passages, alongside the initial query, are processed by LLMs to generate a contextually relevant rich text (GenText). In the last stage, the documents to be retrieved are evaluated and ranked both from the point of view of topical relevance and factual accuracy by means of their comparison with GenText, either through stance detection or semantic similarity. In addition to calculating factual accuracy, GenText can offer a layer of explainability for it, aiding users in understanding the reasoning behind the retrieval. Experimental evaluation of our model on benchmark datasets and against baseline models demonstrates its effectiveness in enhancing the retrieval of both topically relevant and factually accurate health information, thus presenting a significant step forward in the health misinformation mitigation problem.
Health Misinformation Detection in Web Content via Web2Vec: A Structural-, Content-based, and Context-aware Approach based on Web2Vec
Jul 05, 2024In recent years, we have witnessed the proliferation of large amounts of online content generated directly by users with virtually no form of external control, leading to the possible spread of misinformation. The search for effective solutions to this problem is still ongoing, and covers different areas of application, from opinion spam to fake news detection. A more recently investigated scenario, despite the serious risks that incurring disinformation could entail, is that of the online dissemination of health information. Early approaches in this area focused primarily on user-based studies applied to Web page content. More recently, automated approaches have been developed for both Web pages and social media content, particularly with the advent of the COVID-19 pandemic. These approaches are primarily based on handcrafted features extracted from online content in association with Machine Learning. In this scenario, we focus on Web page content, where there is still room for research to study structural-, content- and context-based features to assess the credibility of Web pages. Therefore, this work aims to study the effectiveness of such features in association with a deep learning model, starting from an embedded representation of Web pages that has been recently proposed in the context of phishing Web page detection, i.e., Web2Vec.
Enhancing Documents with Multidimensional Relevance Statements in Cross-encoder Re-ranking
Jun 19, 2023In this paper, we propose a novel approach to consider multiple dimensions of relevance beyond topicality in cross-encoder re-ranking. On the one hand, current multidimensional retrieval models often use na\"ive solutions at the re-ranking stage to aggregate multiple relevance scores into an overall one. On the other hand, cross-encoder re-rankers are effective in considering topicality but are not designed to straightforwardly account for other relevance dimensions. To overcome these issues, we envisage enhancing the candidate documents -- which are retrieved by a first-stage lexical retrieval model -- with "relevance statements" related to additional dimensions of relevance and then performing a re-ranking on them with cross-encoders. In particular, here we consider an additional relevance dimension beyond topicality, which is credibility. We test the effectiveness of our solution in the context of the Consumer Health Search task, considering publicly available datasets. Our results show that the proposed approach statistically outperforms both aggregation-based and cross-encoder re-rankers.
Responsible AI in Healthcare
Feb 19, 2022This article discusses open problems, implemented solutions, and future research in the area of responsible AI in healthcare. In particular, we illustrate two main research themes related to the work of two laboratories within the Department of Informatics, Systems, and Communication at the University of Milano-Bicocca. The problems addressed concern, in particular, {uncertainty in medical data and machine advice}, and the problem of online health information disorder.
Feature Analysis for Assessing the Quality of Wikipedia Articles through Supervised Classification
Dec 06, 2018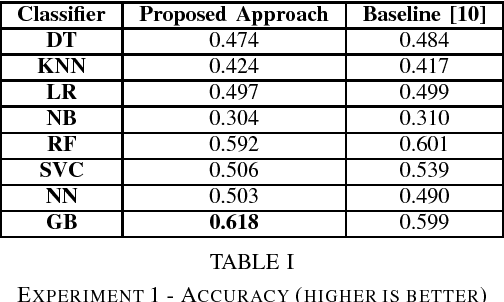
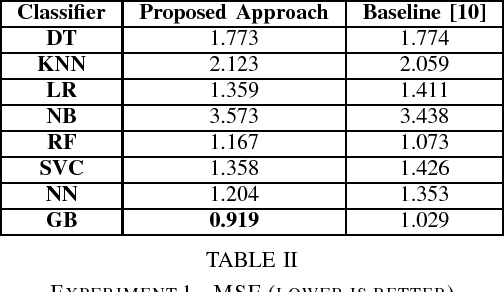
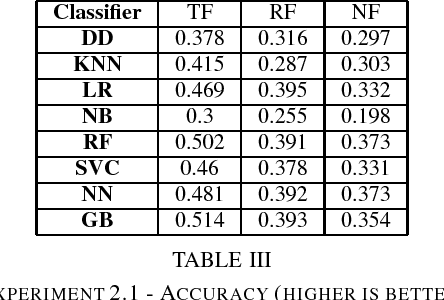
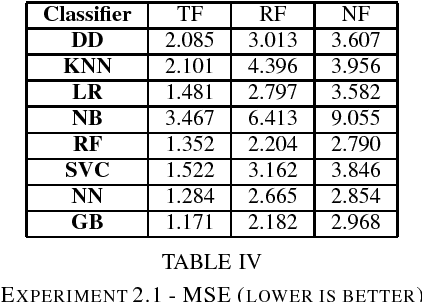
Nowadays, thanks to Web 2.0 technologies, people have the possibility to generate and spread contents on different social media in a very easy way. In this context, the evaluation of the quality of the information that is available online is becoming more and more a crucial issue. In fact, a constant flow of contents is generated every day by often unknown sources, which are not certified by traditional authoritative entities. This requires the development of appropriate methodologies that can evaluate in a systematic way these contents, based on `objective' aspects connected with them. This would help individuals, who nowadays tend to increasingly form their opinions based on what they read online and on social media, to come into contact with information that is actually useful and verified. Wikipedia is nowadays one of the biggest online resources on which users rely as a source of information. The amount of collaboratively generated content that is sent to the online encyclopedia every day can let to the possible creation of low-quality articles (and, consequently, misinformation) if not properly monitored and revised. For this reason, in this paper, the problem of automatically assessing the quality of Wikipedia articles is considered. In particular, the focus is on the analysis of hand-crafted features that can be employed by supervised machine learning techniques to perform the classification of Wikipedia articles on qualitative bases. With respect to prior literature, a wider set of characteristics connected to Wikipedia articles are taken into account and illustrated in detail. Evaluations are performed by considering a labeled dataset provided in a prior work, and different supervised machine learning algorithms, which produced encouraging results with respect to the considered features.