 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDenoising Attention for Query-aware User Modeling in Personalized Search
Aug 30, 2023



The personalization of search results has gained increasing attention in the past few years, thanks to the development of Neural Networks-based approaches for Information Retrieval and the importance of personalization in many search scenarios. Recent works have proposed to build user models at query time by leveraging the Attention mechanism, which allows weighing the contribution of the user-related information w.r.t. the current query. This approach allows taking into account the diversity of the user's interests by giving more importance to those related to the current search performed by the user. In this paper, we first discuss some shortcomings of the standard Attention formulation when employed for personalization. In particular, we focus on issues related to its normalization mechanism and its inability to entirely filter out noisy user-related information. Then, we introduce the Denoising Attention mechanism: an Attention variant that directly tackles the above shortcomings by adopting a robust normalization scheme and introducing a filtering mechanism. The reported experimental evaluation shows the benefits of the proposed approach over other Attention-based variants.
Feature Analysis for Assessing the Quality of Wikipedia Articles through Supervised Classification
Dec 06, 2018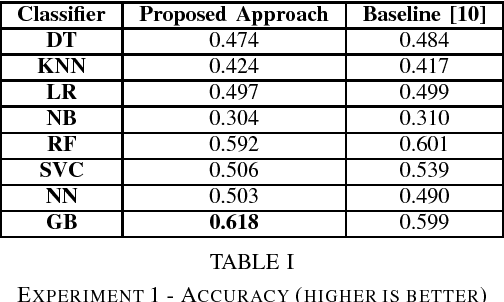
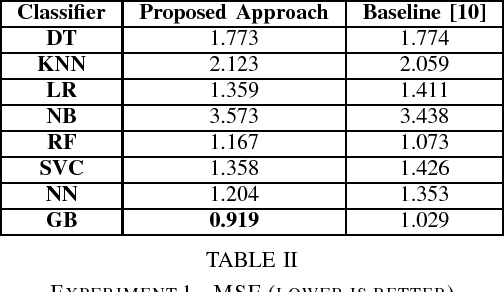
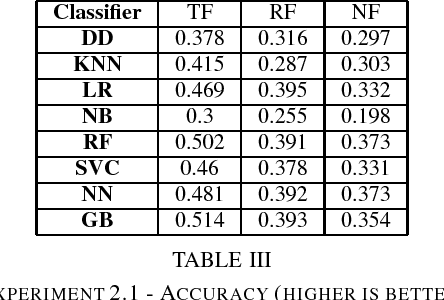
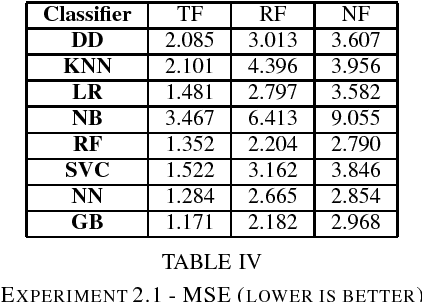
Nowadays, thanks to Web 2.0 technologies, people have the possibility to generate and spread contents on different social media in a very easy way. In this context, the evaluation of the quality of the information that is available online is becoming more and more a crucial issue. In fact, a constant flow of contents is generated every day by often unknown sources, which are not certified by traditional authoritative entities. This requires the development of appropriate methodologies that can evaluate in a systematic way these contents, based on `objective' aspects connected with them. This would help individuals, who nowadays tend to increasingly form their opinions based on what they read online and on social media, to come into contact with information that is actually useful and verified. Wikipedia is nowadays one of the biggest online resources on which users rely as a source of information. The amount of collaboratively generated content that is sent to the online encyclopedia every day can let to the possible creation of low-quality articles (and, consequently, misinformation) if not properly monitored and revised. For this reason, in this paper, the problem of automatically assessing the quality of Wikipedia articles is considered. In particular, the focus is on the analysis of hand-crafted features that can be employed by supervised machine learning techniques to perform the classification of Wikipedia articles on qualitative bases. With respect to prior literature, a wider set of characteristics connected to Wikipedia articles are taken into account and illustrated in detail. Evaluations are performed by considering a labeled dataset provided in a prior work, and different supervised machine learning algorithms, which produced encouraging results with respect to the considered features.