 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesian Synthesis of Probabilistic Programs for Automatic Data Modeling
Jul 14, 2019
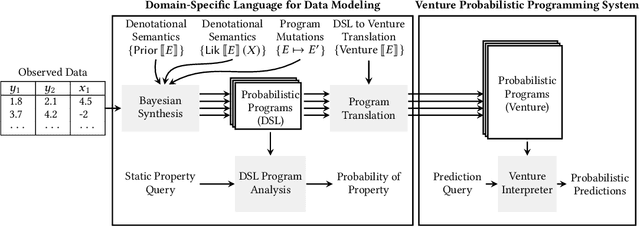


We present new techniques for automatically constructing probabilistic programs for data analysis, interpretation, and prediction. These techniques work with probabilistic domain-specific data modeling languages that capture key properties of a broad class of data generating processes, using Bayesian inference to synthesize probabilistic programs in these modeling languages given observed data. We provide a precise formulation of Bayesian synthesis for automatic data modeling that identifies sufficient conditions for the resulting synthesis procedure to be sound. We also derive a general class of synthesis algorithms for domain-specific languages specified by probabilistic context-free grammars and establish the soundness of our approach for these languages. We apply the techniques to automatically synthesize probabilistic programs for time series data and multivariate tabular data. We show how to analyze the structure of the synthesized programs to compute, for key qualitative properties of interest, the probability that the underlying data generating process exhibits each of these properties. Second, we translate probabilistic programs in the domain-specific language into probabilistic programs in Venture, a general-purpose probabilistic programming system. The translated Venture programs are then executed to obtain predictions of new time series data and new multivariate data records. Experimental results show that our techniques can accurately infer qualitative structure in multiple real-world data sets and outperform standard data analysis methods in forecasting and predicting new data.
Using probabilistic programs as proposals
Jan 13, 2018


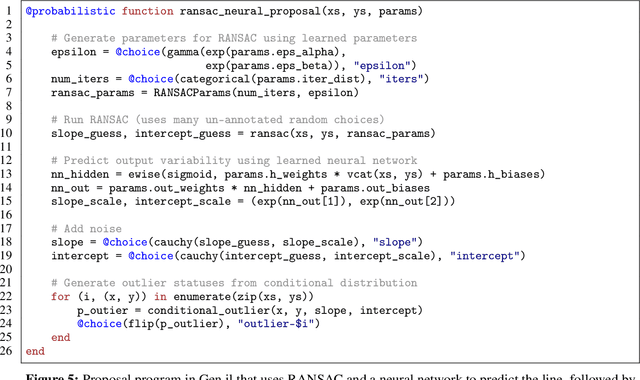
Monte Carlo inference has asymptotic guarantees, but can be slow when using generic proposals. Handcrafted proposals that rely on user knowledge about the posterior distribution can be efficient, but are difficult to derive and implement. This paper proposes to let users express their posterior knowledge in the form of proposal programs, which are samplers written in probabilistic programming languages. One strategy for writing good proposal programs is to combine domain-specific heuristic algorithms with neural network models. The heuristics identify high probability regions, and the neural networks model the posterior uncertainty around the outputs of the algorithm. Proposal programs can be used as proposal distributions in importance sampling and Metropolis-Hastings samplers without sacrificing asymptotic consistency, and can be optimized offline using inference compilation. Support for optimizing and using proposal programs is easily implemented in a sampling-based probabilistic programming runtime. The paper illustrates the proposed technique with a proposal program that combines RANSAC and neural networks to accelerate inference in a Bayesian linear regression with outliers model.
AIDE: An algorithm for measuring the accuracy of probabilistic inference algorithms
Nov 04, 2017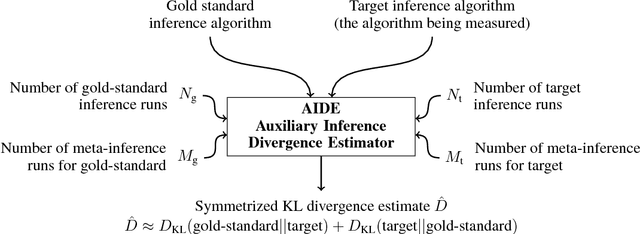
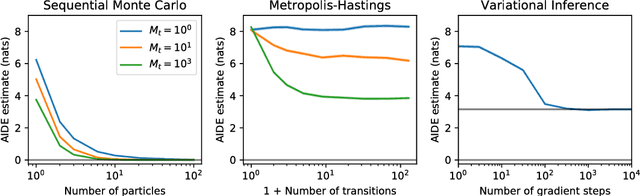
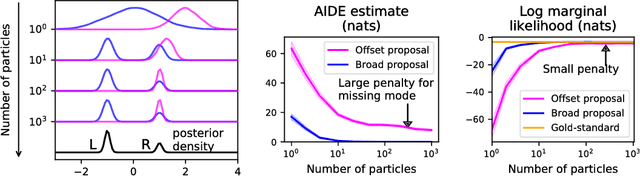
Approximate probabilistic inference algorithms are central to many fields. Examples include sequential Monte Carlo inference in robotics, variational inference in machine learning, and Markov chain Monte Carlo inference in statistics. A key problem faced by practitioners is measuring the accuracy of an approximate inference algorithm on a specific data set. This paper introduces the auxiliary inference divergence estimator (AIDE), an algorithm for measuring the accuracy of approximate inference algorithms. AIDE is based on the observation that inference algorithms can be treated as probabilistic models and the random variables used within the inference algorithm can be viewed as auxiliary variables. This view leads to a new estimator for the symmetric KL divergence between the approximating distributions of two inference algorithms. The paper illustrates application of AIDE to algorithms for inference in regression, hidden Markov, and Dirichlet process mixture models. The experiments show that AIDE captures the qualitative behavior of a broad class of inference algorithms and can detect failure modes of inference algorithms that are missed by standard heuristics.
Encapsulating models and approximate inference programs in probabilistic modules
May 06, 2017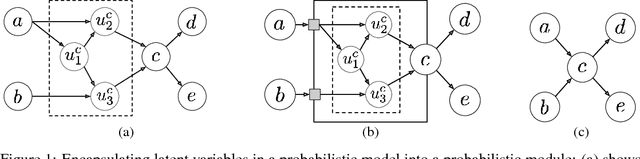

This paper introduces the probabilistic module interface, which allows encapsulation of complex probabilistic models with latent variables alongside custom stochastic approximate inference machinery, and provides a platform-agnostic abstraction barrier separating the model internals from the host probabilistic inference system. The interface can be seen as a stochastic generalization of a standard simulation and density interface for probabilistic primitives. We show that sound approximate inference algorithms can be constructed for networks of probabilistic modules, and we demonstrate that the interface can be implemented using learned stochastic inference networks and MCMC and SMC approximate inference programs.
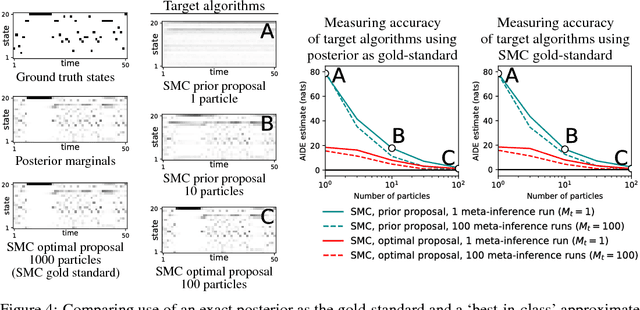
Measuring the non-asymptotic convergence of sequential Monte Carlo samplers using probabilistic programming
May 06, 2017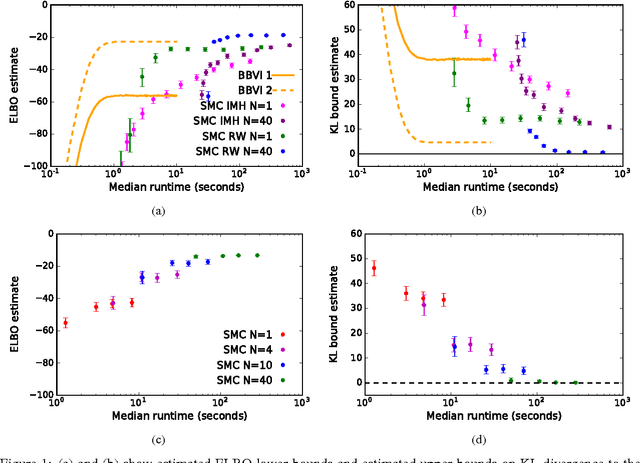
A key limitation of sampling algorithms for approximate inference is that it is difficult to quantify their approximation error. Widely used sampling schemes, such as sequential importance sampling with resampling and Metropolis-Hastings, produce output samples drawn from a distribution that may be far from the target posterior distribution. This paper shows how to upper-bound the symmetric KL divergence between the output distribution of a broad class of sequential Monte Carlo (SMC) samplers and their target posterior distributions, subject to assumptions about the accuracy of a separate gold-standard sampler. The proposed method applies to samplers that combine multiple particles, multinomial resampling, and rejuvenation kernels. The experiments show the technique being used to estimate bounds on the divergence of SMC samplers for posterior inference in a Bayesian linear regression model and a Dirichlet process mixture model.
Probabilistic programs for inferring the goals of autonomous agents
Apr 18, 2017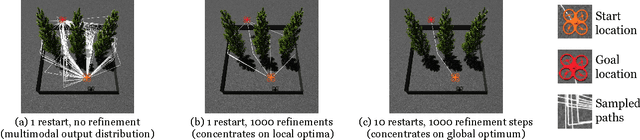
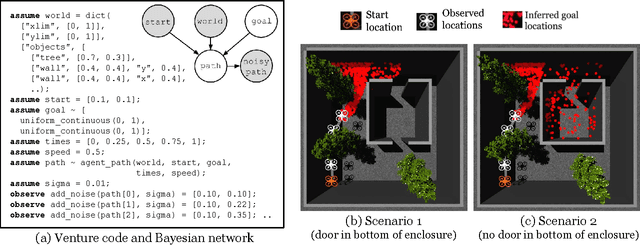
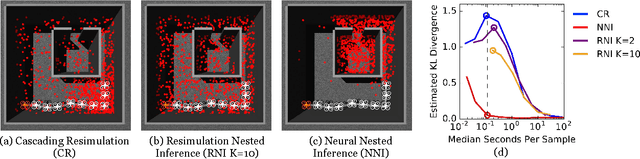
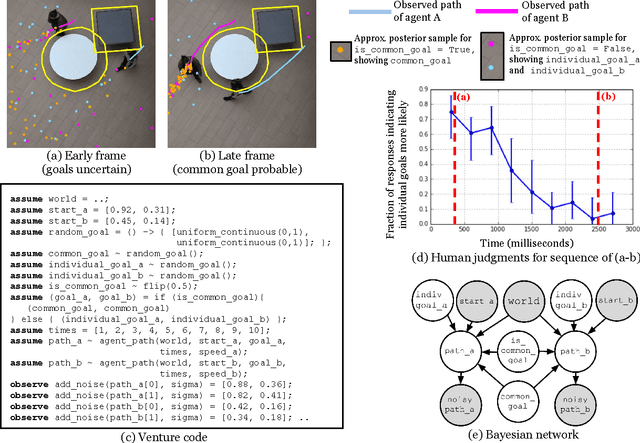
Intelligent systems sometimes need to infer the probable goals of people, cars, and robots, based on partial observations of their motion. This paper introduces a class of probabilistic programs for formulating and solving these problems. The formulation uses randomized path planning algorithms as the basis for probabilistic models of the process by which autonomous agents plan to achieve their goals. Because these path planning algorithms do not have tractable likelihood functions, new inference algorithms are needed. This paper proposes two Monte Carlo techniques for these "likelihood-free" models, one of which can use likelihood estimates from neural networks to accelerate inference. The paper demonstrates efficacy on three simple examples, each using under 50 lines of probabilistic code.