 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePassive Approach for the K-means Problem on Streaming Data
Dec 07, 2020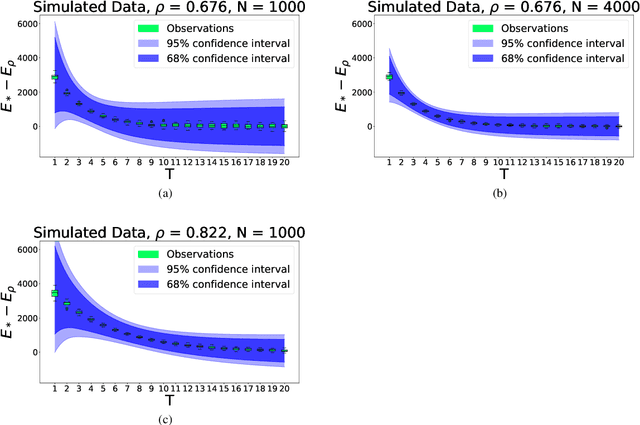
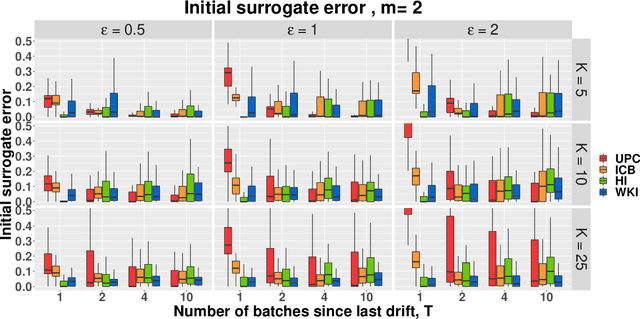
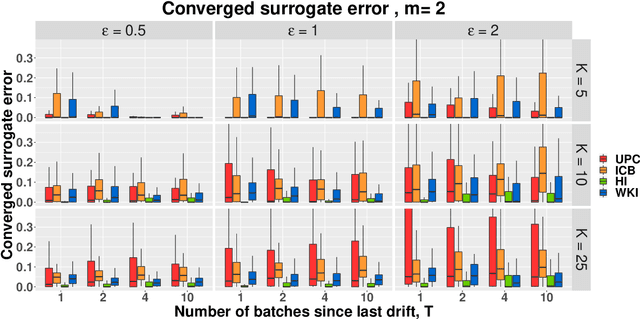
Currently the amount of data produced worldwide is increasing beyond measure, thus a high volume of unsupervised data must be processed continuously. One of the main unsupervised data analysis is clustering. In streaming data scenarios, the data is composed by an increasing sequence of batches of samples where the concept drift phenomenon may happen. In this paper, we formally define the Streaming $K$-means(S$K$M) problem, which implies a restart of the error function when a concept drift occurs. We propose a surrogate error function that does not rely on concept drift detection. We proof that the surrogate is a good approximation of the S$K$M error. Hence, we suggest an algorithm which minimizes this alternative error each time a new batch arrives. We present some initialization techniques for streaming data scenarios as well. Besides providing theoretical results, experiments demonstrate an improvement of the converged error for the non-trivial initialization methods.
An efficient K -means clustering algorithm for massive data
Jan 09, 2018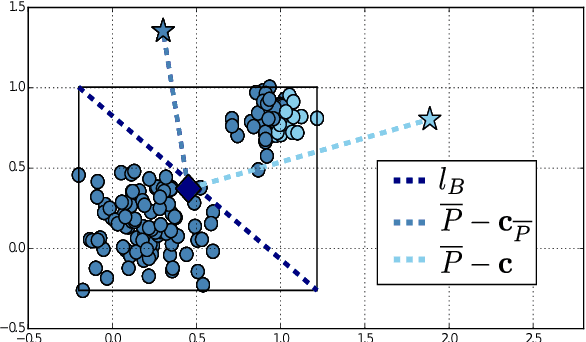
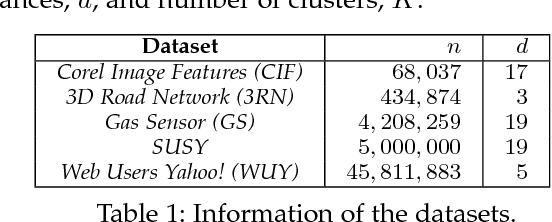
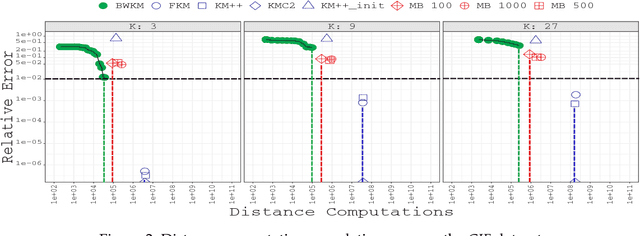
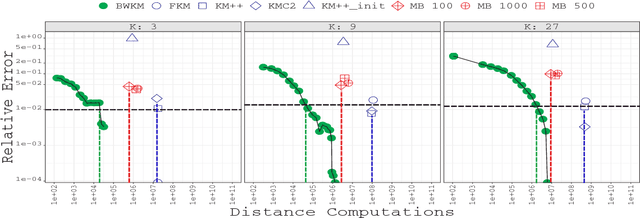
The analysis of continously larger datasets is a task of major importance in a wide variety of scientific fields. In this sense, cluster analysis algorithms are a key element of exploratory data analysis, due to their easiness in the implementation and relatively low computational cost. Among these algorithms, the K -means algorithm stands out as the most popular approach, besides its high dependency on the initial conditions, as well as to the fact that it might not scale well on massive datasets. In this article, we propose a recursive and parallel approximation to the K -means algorithm that scales well on both the number of instances and dimensionality of the problem, without affecting the quality of the approximation. In order to achieve this, instead of analyzing the entire dataset, we work on small weighted sets of points that mostly intend to extract information from those regions where it is harder to determine the correct cluster assignment of the original instances. In addition to different theoretical properties, which deduce the reasoning behind the algorithm, experimental results indicate that our method outperforms the state-of-the-art in terms of the trade-off between number of distance computations and the quality of the solution obtained.
An efficient K-means algorithm for Massive Data
May 10, 2016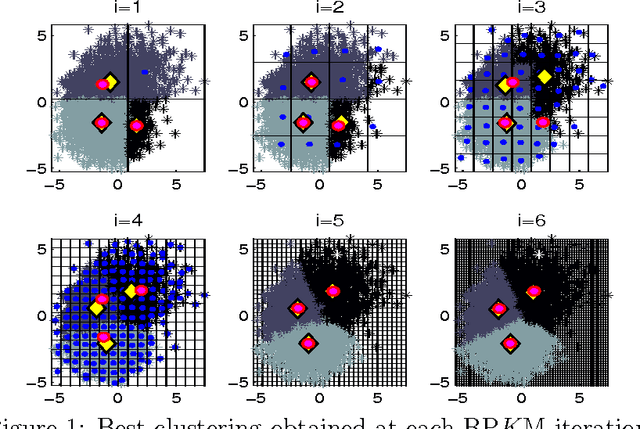

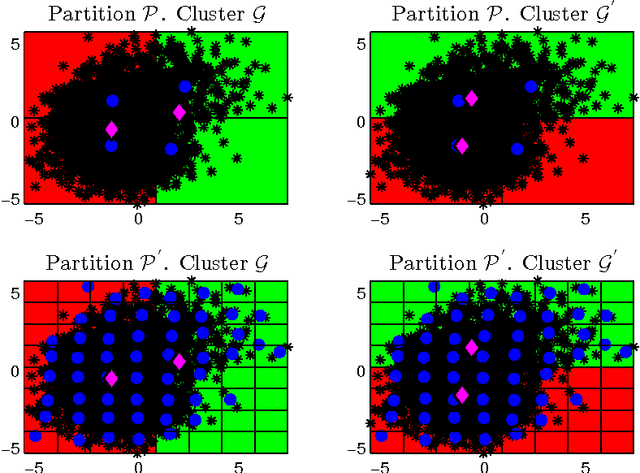
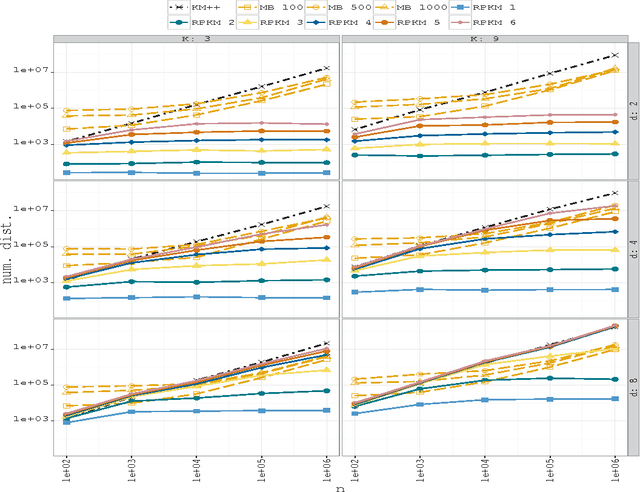
Due to the progressive growth of the amount of data available in a wide variety of scientific fields, it has become more difficult to ma- nipulate and analyze such information. Even though datasets have grown in size, the K-means algorithm remains as one of the most popular clustering methods, in spite of its dependency on the initial settings and high computational cost, especially in terms of distance computations. In this work, we propose an efficient approximation to the K-means problem intended for massive data. Our approach recursively partitions the entire dataset into a small number of sub- sets, each of which is characterized by its representative (center of mass) and weight (cardinality), afterwards a weighted version of the K-means algorithm is applied over such local representation, which can drastically reduce the number of distances computed. In addition to some theoretical properties, experimental results indicate that our method outperforms well-known approaches, such as the K-means++ and the minibatch K-means, in terms of the relation between number of distance computations and the quality of the approximation.