 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNL-Augmenter: A Framework for Task-Sensitive Natural Language Augmentation
Dec 06, 2021



Data augmentation is an important component in the robustness evaluation of models in natural language processing (NLP) and in enhancing the diversity of the data they are trained on. In this paper, we present NL-Augmenter, a new participatory Python-based natural language augmentation framework which supports the creation of both transformations (modifications to the data) and filters (data splits according to specific features). We describe the framework and an initial set of 117 transformations and 23 filters for a variety of natural language tasks. We demonstrate the efficacy of NL-Augmenter by using several of its transformations to analyze the robustness of popular natural language models. The infrastructure, datacards and robustness analysis results are available publicly on the NL-Augmenter repository (\url{https://github.com/GEM-benchmark/NL-Augmenter}).
Tab.IAIS: Flexible Table Recognition and Semantic Interpretation System
May 25, 2021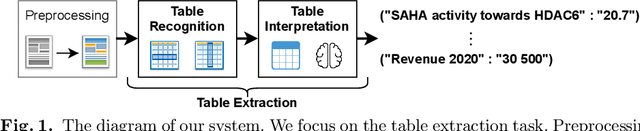

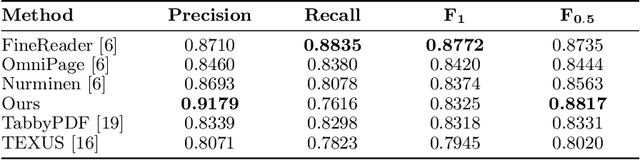
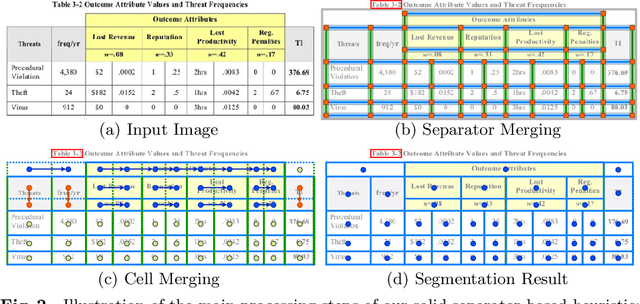
Table extraction is an important but still unsolved problem. In this paper, we introduce a flexible end-to-end table extraction system. We develop two rule-based algorithms that perform the complete table recognition process and support the most frequent table formats found in the scientific literature. Moreover, to incorporate the extraction of semantic information into the table recognition process, we develop a graph-based table interpretation method. We conduct extensive experiments on the challenging table recognition benchmarks ICDAR 2013 and ICDAR 2019. Our table recognition approach achieves results competitive with state-of-the-art approaches. Moreover, our complete information extraction system exhibited a high F1 score of 0.7380 proving the utility of our approach.
Empirical Error Modeling Improves Robustness of Noisy Neural Sequence Labeling
May 25, 2021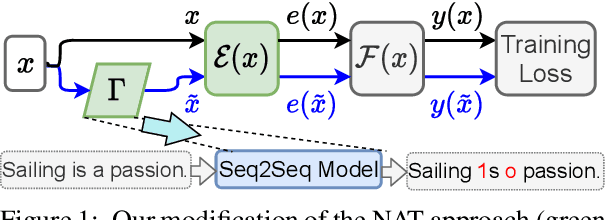
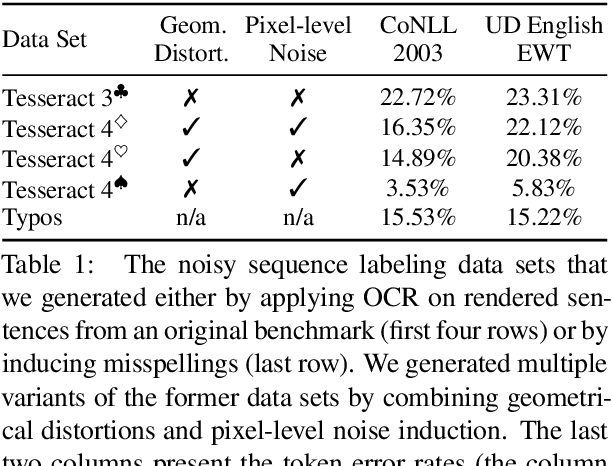
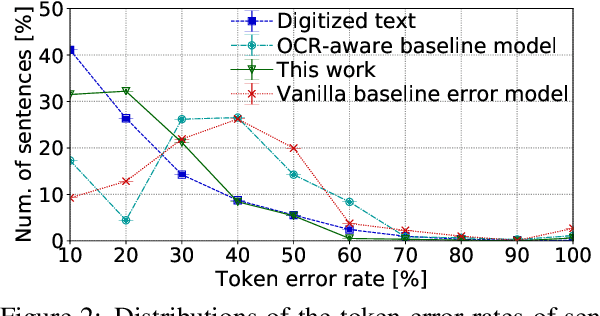
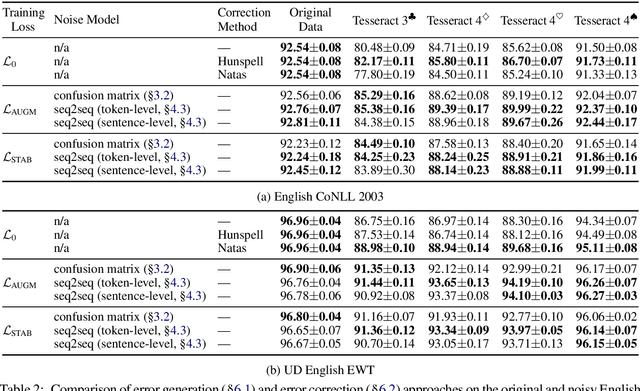
Despite recent advances, standard sequence labeling systems often fail when processing noisy user-generated text or consuming the output of an Optical Character Recognition (OCR) process. In this paper, we improve the noise-aware training method by proposing an empirical error generation approach that employs a sequence-to-sequence model trained to perform translation from error-free to erroneous text. Using an OCR engine, we generated a large parallel text corpus for training and produced several real-world noisy sequence labeling benchmarks for evaluation. Moreover, to overcome the data sparsity problem that exacerbates in the case of imperfect textual input, we learned noisy language model-based embeddings. Our approach outperformed the baseline noise generation and error correction techniques on the erroneous sequence labeling data sets. To facilitate future research on robustness, we make our code, embeddings, and data conversion scripts publicly available.
NAT: Noise-Aware Training for Robust Neural Sequence Labeling
May 14, 2020Sequence labeling systems should perform reliably not only under ideal conditions but also with corrupted inputs - as these systems often process user-generated text or follow an error-prone upstream component. To this end, we formulate the noisy sequence labeling problem, where the input may undergo an unknown noising process and propose two Noise-Aware Training (NAT) objectives that improve robustness of sequence labeling performed on perturbed input: Our data augmentation method trains a neural model using a mixture of clean and noisy samples, whereas our stability training algorithm encourages the model to create a noise-invariant latent representation. We employ a vanilla noise model at training time. For evaluation, we use both the original data and its variants perturbed with real OCR errors and misspellings. Extensive experiments on English and German named entity recognition benchmarks confirmed that NAT consistently improved robustness of popular sequence labeling models, preserving accuracy on the original input. We make our code and data publicly available for the research community.
Efficient, Lexicon-Free OCR using Deep Learning
Jun 05, 2019



Contrary to popular belief, Optical Character Recognition (OCR) remains a challenging problem when text occurs in unconstrained environments, like natural scenes, due to geometrical distortions, complex backgrounds, and diverse fonts. In this paper, we present a segmentation-free OCR system that combines deep learning methods, synthetic training data generation, and data augmentation techniques. We render synthetic training data using large text corpora and over 2000 fonts. To simulate text occurring in complex natural scenes, we augment extracted samples with geometric distortions and with a proposed data augmentation technique - alpha-compositing with background textures. Our models employ a convolutional neural network encoder to extract features from text images. Inspired by the recent progress in neural machine translation and language modeling, we examine the capabilities of both recurrent and convolutional neural networks in modeling the interactions between input elements.