 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-shot Cross-country Generalization of Tabular Machine Learning and Foundation Models for Childhood Anemia Prediction under Distribution Shift
May 26, 2026Childhood anemia affects around 40% of children aged 6-59 months globally and arises from heterogeneous factors, limiting model generalizability. We evaluate a transformer-based tabular foundation model against classical supervised methods under cross-country and data-scarce settings. We used DHS data from 16 countries across Africa, Asia, Latin America, the Caucasus, and the Middle East (n=68,856). We compared Logistic Regression, XGBoost, LightGBM, and TabPFN v2.6. Performance was assessed using AUC-ROC, Brier score, and ECE. Generalization was evaluated using leave-one-country-out (LOCO), reverse-LOCO, and few-shot settings. Subgroup analyses included sex, age, residence, maternal education, and wealth. Feature importance was estimated using SHAP. TabPFN outperformed classical models in low-data regimes (<200 samples), showing higher discrimination and better calibration. Across countries, it achieved the lowest Brier score (0.042) and ECE (0.203). Under full-data settings, AUC-ROC ranged from 0.59-0.76 with small between-model differences ($\leq 0.05$). LOCO performance was stable (0.58-0.69), driven by country context. Reverse-LOCO showed asymmetric transferability. Subgroup performance was consistent with no systematic demographic bias. SHAP identified child age, altitude, and height-for-age z-score as dominant predictors, followed by wealth and maternal education. Performance in childhood anemia prediction is driven more by population variation than model choice. TabPFN provides advantages in low-resource settings through improved discrimination and calibration, highlighting foundation models as promising tools for data-scarce global health prediction.
Bridging visual saliency and large language models for explainable deep learning in medical imaging
May 07, 2026The opaque nature of deep learning models remains a significant barrier to their clinical adoption in medical imaging. This paper presents a multimodal explainability framework that bridges the gap between convolutional neural network (CNN) predictions and clinically actionable insights for brain tumor classification, leveraging large language models (LLMs) to deliver human-interpretable diagnostic narratives. The proposed framework operates through three coupled stages. First, nine CNN architectures are extended with a dual-output hybrid formulation that simultaneously optimises a classification head and a segmentation head, enabling spatially richer feature learning. Second, visual saliency attribution methods, namely Grad-CAM, Grad-CAM++, and ScoreCAM, are applied to generate class-discriminative heatmaps, which are subsequently refined into binary tumor masks via an adaptive percentile thresholding pipeline. Third, the resulting masks are mapped onto the Harvard-Oxford cortical atlas to translate pixel-level evidence into named neuroanatomical structures, and the extracted findings are encoded into a structured JSON file that conditions three LLMs (Grok3, Mistral, and LLaMA) to generate coherent, radiological-style diagnostic reports. Evaluated on a dataset of 4,834 contrast-enhanced T1-weighted brain MRI images spanning three tumor classes, InceptionResNetV2 achieved the highest classification performance and Grad-CAM++ yielded the best segmentation overlap. Among the language models, Grok3 led in lexical diversity and coherence, while LLaMA achieved the highest readability score. By integrating visual, anatomical, and linguistic modalities into a unified pipeline, the framework produces explanations that are technically grounded and meaningfully interpretable, advancing the transparency and clinical accountability of artificial intelligence assisted brain tumor diagnosis.
Hierarchical Spatio-Channel Clustering for Efficient Model Compression in Medical Image Analysis
Apr 25, 2026Convolutional neural networks (CNNs) have become increasingly difficult to deploy in resource-constrained environments due to their large memory and computational requirements. Although low-rank compression methods can reduce this burden, most existing approaches compress spatial and channel redundancy independently and therefore do not fully exploit the localised structure within convolutional feature maps. This paper proposes a hierarchical spatio-channel low-rank compression framework for CNNs that exploits redundancy across spatial regions and channel activations. Unlike conventional methods, which apply a uniform decomposition across an entire layer, the proposed approach first partitions feature maps into spatial regions, then groups channels according to their co-activation patterns within each region, and finally applies rank-adaptive SVD to each resulting spatio-channel cluster. The method is evaluated on an AlexNet-based brain tumour MRI classification model and compared with Global SVD and Tucker decomposition under \(3\times\) and \(6\times\) compression budgets. Our method outperforms both baselines, reducing FLOPs from \(8.21\,\mathrm{G}\) to \(1.55\,\mathrm{G}\) (\(81.1\%\) reduction), achieving a \(1.38\times\) inference speed-up, and increasing classification accuracy from \(87.76\%\) to \(89.80\%\). The method also improves the macro \(F_1\)-score and performance on challenging classes such as meningioma. A hyper-parameter trade-off analysis demonstrates that the framework provides Pareto-optimal configurations, enabling control over the balance between compression and predictive performance. Moderate clustering with adaptive rank selection yields strong results. Bootstrap standard errors are reported for all classification metrics.
An Optimised Greedy-Weighted Ensemble Framework for Financial Loan Default Prediction
Mar 19, 2026Accurate prediction of loan defaults is a central challenge in credit risk management, particularly in modern financial datasets characterised by nonlinear relationships, class imbalance, and evolving borrower behaviour. Traditional statistical models and static ensemble methods often struggle to maintain reliable performance under such conditions. This study proposes an Optimised Greedy-Weighted Ensemble framework for loan default prediction that dynamically allocates model weights based on empirical predictive performance. The framework integrates multiple machine learning classifiers, with their hyperparameters first optimised using Particle Swarm Optimisation. Model predictions are then combined via a regularised greedy weighting mechanism. At the same time, a neural-network-based meta-learner is employed within stacked-ensemble to capture higher-order relationships among model outputs. Experiments conducted on the Lending Club dataset demonstrate that the proposed framework improves predictive performance compared with individual classifiers. The BlendNet ensemble achieved the strongest results with an AUC of 0.80, a macro-average F1-score of 0.73, and a default recall of 0.81. Calibration analysis further shows that tree-based ensembles such as Extra Trees and Gradient Boosting provide the most reliable probability estimates, while the stacked ensemble offers superior ranking capability. Feature analysis using Recursive Feature Elimination identifies revolving utilisation, annual income, and debt-to-income ratio as the most influential predictors of loan default. These findings demonstrate that performance-driven ensemble weighting can improve both predictive accuracy and interpretability in credit risk modelling. The proposed framework provides a scalable data-driven approach to support institutional credit assessment, risk monitoring, and financial decision-making.
Balancing Performance and Fairness in Explainable AI for Anomaly Detection in Distributed Power Plants Monitoring
Mar 19, 2026Reliable anomaly detection in distributed power plant monitoring systems is essential for ensuring operational continuity and reducing maintenance costs, particularly in regions where telecom operators heavily rely on diesel generators. However, this task is challenged by extreme class imbalance, lack of interpretability, and potential fairness issues across regional clusters. In this work, we propose a supervised ML framework that integrates ensemble methods (LightGBM, XGBoost, Random Forest, CatBoost, GBDT, AdaBoost) and baseline models (Support Vector Machine, K-Nearrest Neighbors, Multilayer Perceptrons, and Logistic Regression) with advanced resampling techniques (SMOTE with Tomek Links and ENN) to address imbalance in a dataset of diesel generator operations in Cameroon. Interpretability is achieved through SHAP (SHapley Additive exPlanations), while fairness is quantified using the Disparate Impact Ratio (DIR) across operational clusters. We further evaluate model generalization using Maximum Mean Discrepancy (MMD) to capture domain shifts between regions. Experimental results show that ensemble models consistently outperform baselines, with LightGBM achieving an F1-score of 0.99 and minimal bias across clusters (DIR $\approx 0.95$). SHAP analysis highlights fuel consumption rate and runtime per day as dominant predictors, providing actionable insights for operators. Our findings demonstrate that it is possible to balance performance, interpretability, and fairness in anomaly detection, paving the way for more equitable and explainable AI systems in industrial power management. {\color{black} Finally, beyond offline evaluation, we also discuss how the trained models can be deployed in practice for real-time monitoring. We show how containerized services can process in real-time, deliver low-latency predictions, and provide interpretable outputs for operators.
Robustness and Scalability Of Machine Learning for Imbalanced Clinical Data in Emergency and Critical Care
Dec 25, 2025



Emergency and intensive care environments require predictive models that are both accurate and computationally efficient, yet clinical data in these settings are often severely imbalanced. Such skewness undermines model reliability, particularly for rare but clinically crucial outcomes, making robustness and scalability essential for real-world usage. In this paper, we systematically evaluate the robustness and scalability of classical machine learning models on imbalanced tabular data from MIMIC-IV-ED and eICU. Class imbalance was quantified using complementary metrics, and we compared the performance of tree-based methods, the state-of-the-art TabNet deep learning model, and a custom lightweight residual network. TabResNet was designed as a computationally efficient alternative to TabNet, replacing its complex attention mechanisms with a streamlined residual architecture to maintain representational capacity for real-time clinical use. All models were optimized via a Bayesian hyperparameter search and assessed on predictive performance, robustness to increasing imbalance, and computational scalability. Our results, on seven clinically vital predictive tasks, show that tree-based methods, particularly XGBoost, consistently achieved the most stable performance across imbalance levels and scaled efficiently with sample size. Deep tabular models degraded more sharply under imbalance and incurred higher computational costs, while TabResNet provided a lighter alternative to TabNet but did not surpass ensemble benchmarks. These findings indicate that in emergency and critical care, robustness to imbalance and computational scalability could outweigh architectural complexity. Tree-based ensemble methods currently offer the most practical and clinically feasible choice, equipping practitioners with a framework for selecting models suited to high-stakes, time-sensitive environments.
Clustering-based Low-Rank Matrix Approximation: An Adaptive Theoretical Analysis with Application to Data Compression
May 13, 2025Low-rank matrix approximation (LoRMA) is a fundamental tool for compressing high-resolution data matrices by extracting important features while suppressing redundancy. Low-rank methods, such as global singular value decomposition (SVD), apply uniform compression across the entire data matrix, often ignoring important local variations and leading to the loss of fine structural details. To address these limitations, we introduce an adaptive LoRMA, which partitions data matrix into overlapping patches, groups structurally similar patches into several clusters using k-means, and performs SVD within each cluster. We derive the overall compression factor accounting for patch overlap and analyze how patch size influences compression efficiency and computational cost. While the proposed adaptive LoRMA method is applicable to any data exhibiting high local variation, we focus on medical imaging due to its pronounced local variability. We evaluate and compare our adaptive LoRMA against global SVD across four imaging modalities: MRI, ultrasound, CT scan, and chest X-ray. Results demonstrate that adaptive LoRMA effectively preserves structural integrity, edge details, and diagnostic relevance, as measured by peak signal-to-noise ratio (PSNR), structural similarity index (SSIM), mean squared error (MSE), intersection over union (IoU), and edge preservation index (EPI). Adaptive LoRMA significantly minimizes block artifacts and residual errors, particularly in pathological regions, consistently outperforming global SVD in terms of PSNR, SSIM, IoU, EPI, and achieving lower MSE. Adaptive LoRMA prioritizes clinically salient regions while allowing aggressive compression in non-critical regions, optimizing storage efficiency. Although adaptive LoRMA requires higher processing time, its diagnostic fidelity justifies the overhead for high-compression applications.
Unsupervised anomaly detection in large-scale estuarine acoustic telemetry data
Feb 03, 2025



Acoustic telemetry data plays a vital role in understanding the behaviour and movement of aquatic animals. However, these datasets, which often consist of millions of individual data points, frequently contain anomalous movements that pose significant challenges. Traditionally, anomalous movements are identified either manually or through basic statistical methods, approaches that are time-consuming and prone to high rates of unidentified anomalies in large datasets. This study focuses on the development of automated classifiers for a large telemetry dataset comprising detections from fifty acoustically tagged dusky kob monitored in the Breede Estuary, South Africa. Using an array of 16 acoustic receivers deployed throughout the estuary between 2016 and 2021, we collected over three million individual data points. We present detailed guidelines for data pre-processing, resampling strategies, labelling process, feature engineering, data splitting methodologies, and the selection and interpretation of machine learning and deep learning models for anomaly detection. Among the evaluated models, neural networks autoencoder (NN-AE) demonstrated superior performance, aided by our proposed threshold-finding algorithm. NN-AE achieved a high recall with no false normal (i.e., no misclassifications of anomalous movements as normal patterns), a critical factor in ensuring that no true anomalies are overlooked. In contrast, other models exhibited false normal fractions exceeding 0.9, indicating they failed to detect the majority of true anomalies; a significant limitation for telemetry studies where undetected anomalies can distort interpretations of movement patterns. While the NN-AE's performance highlights its reliability and robustness in detecting anomalies, it faced challenges in accurately learning normal movement patterns when these patterns gradually deviated from anomalous ones.
Advancing Low-Rank and Local Low-Rank Matrix Approximation in Medical Imaging: A Systematic Literature Review and Future Directions
Feb 21, 2024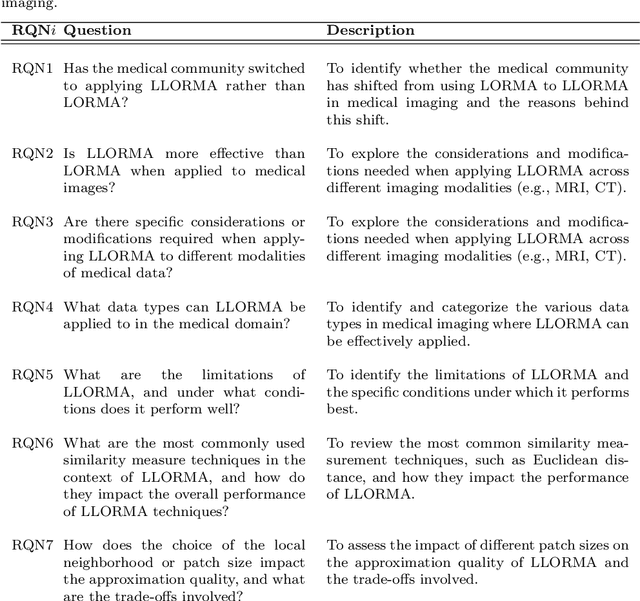
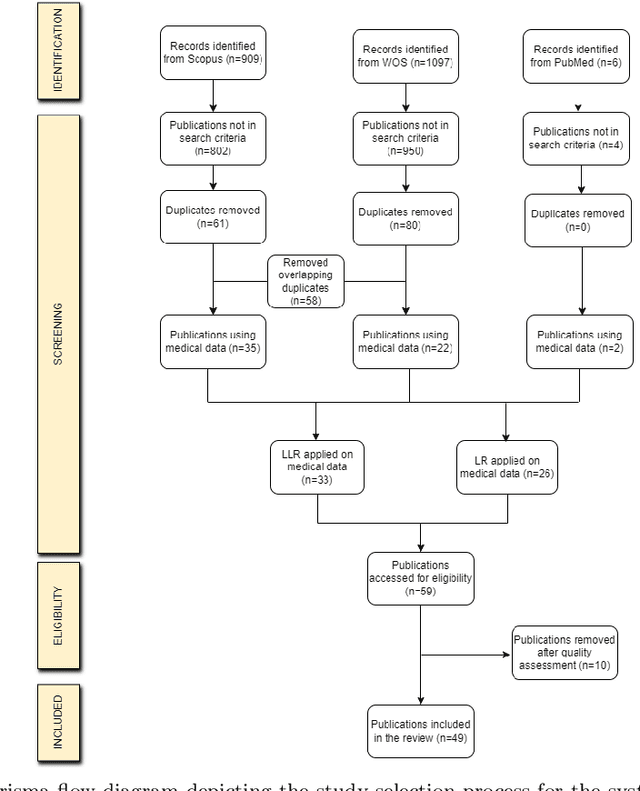
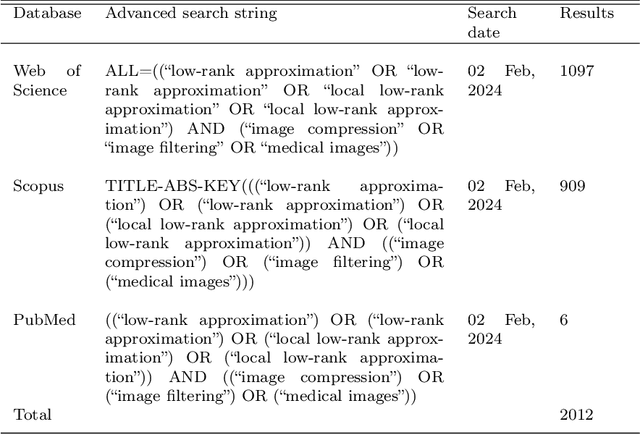
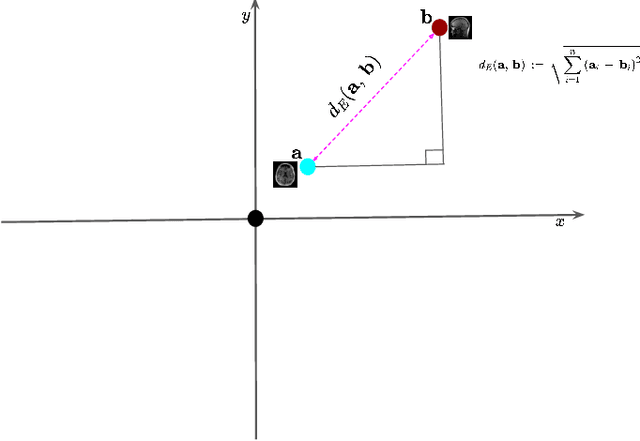
The large volume and complexity of medical imaging datasets are bottlenecks for storage, transmission, and processing. To tackle these challenges, the application of low-rank matrix approximation (LRMA) and its derivative, local LRMA (LLRMA) has demonstrated potential. This paper conducts a systematic literature review to showcase works applying LRMA and LLRMA in medical imaging. A detailed analysis of the literature identifies LRMA and LLRMA methods applied to various imaging modalities. This paper addresses the challenges and limitations associated with existing LRMA and LLRMA methods. We note a significant shift towards a preference for LLRMA in the medical imaging field since 2015, demonstrating its potential and effectiveness in capturing complex structures in medical data compared to LRMA. Acknowledging the limitations of shallow similarity methods used with LLRMA, we suggest advanced semantic image segmentation for similarity measure, explaining in detail how it can measure similar patches and their feasibility. We note that LRMA and LLRMA are mainly applied to unstructured medical data, and we propose extending their application to different medical data types, including structured and semi-structured. This paper also discusses how LRMA and LLRMA can be applied to regular data with missing entries and the impact of inaccuracies in predicting missing values and their effects. We discuss the impact of patch size and propose the use of random search (RS) to determine the optimal patch size. To enhance feasibility, a hybrid approach using Bayesian optimization and RS is proposed, which could improve the application of LRMA and LLRMA in medical imaging.
Anomaly Detection in Power Generation Plants with Generative Adversarial Networks
Sep 30, 2023



Anomaly detection is a critical task that involves the identification of data points that deviate from a predefined pattern, useful for fraud detection and related activities. Various techniques are employed for anomaly detection, but recent research indicates that deep learning methods, with their ability to discern intricate data patterns, are well-suited for this task. This study explores the use of Generative Adversarial Networks (GANs) for anomaly detection in power generation plants. The dataset used in this investigation comprises fuel consumption records obtained from power generation plants operated by a telecommunications company. The data was initially collected in response to observed irregularities in the fuel consumption patterns of the generating sets situated at the company's base stations. The dataset was divided into anomalous and normal data points based on specific variables, with 64.88% classified as normal and 35.12% as anomalous. An analysis of feature importance, employing the random forest classifier, revealed that Running Time Per Day exhibited the highest relative importance. A GANs model was trained and fine-tuned both with and without data augmentation, with the goal of increasing the dataset size to enhance performance. The generator model consisted of five dense layers using the tanh activation function, while the discriminator comprised six dense layers, each integrated with a dropout layer to prevent overfitting. Following data augmentation, the model achieved an accuracy rate of 98.99%, compared to 66.45% before augmentation. This demonstrates that the model nearly perfectly classified data points into normal and anomalous categories, with the augmented data significantly enhancing the GANs' performance in anomaly detection. Consequently, this study recommends the use of GANs, particularly when using large datasets, for effective anomaly detection.