 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClustering-based Low-Rank Matrix Approximation: An Adaptive Theoretical Analysis with Application to Data Compression
May 13, 2025Low-rank matrix approximation (LoRMA) is a fundamental tool for compressing high-resolution data matrices by extracting important features while suppressing redundancy. Low-rank methods, such as global singular value decomposition (SVD), apply uniform compression across the entire data matrix, often ignoring important local variations and leading to the loss of fine structural details. To address these limitations, we introduce an adaptive LoRMA, which partitions data matrix into overlapping patches, groups structurally similar patches into several clusters using k-means, and performs SVD within each cluster. We derive the overall compression factor accounting for patch overlap and analyze how patch size influences compression efficiency and computational cost. While the proposed adaptive LoRMA method is applicable to any data exhibiting high local variation, we focus on medical imaging due to its pronounced local variability. We evaluate and compare our adaptive LoRMA against global SVD across four imaging modalities: MRI, ultrasound, CT scan, and chest X-ray. Results demonstrate that adaptive LoRMA effectively preserves structural integrity, edge details, and diagnostic relevance, as measured by peak signal-to-noise ratio (PSNR), structural similarity index (SSIM), mean squared error (MSE), intersection over union (IoU), and edge preservation index (EPI). Adaptive LoRMA significantly minimizes block artifacts and residual errors, particularly in pathological regions, consistently outperforming global SVD in terms of PSNR, SSIM, IoU, EPI, and achieving lower MSE. Adaptive LoRMA prioritizes clinically salient regions while allowing aggressive compression in non-critical regions, optimizing storage efficiency. Although adaptive LoRMA requires higher processing time, its diagnostic fidelity justifies the overhead for high-compression applications.
Advancing Low-Rank and Local Low-Rank Matrix Approximation in Medical Imaging: A Systematic Literature Review and Future Directions
Feb 21, 2024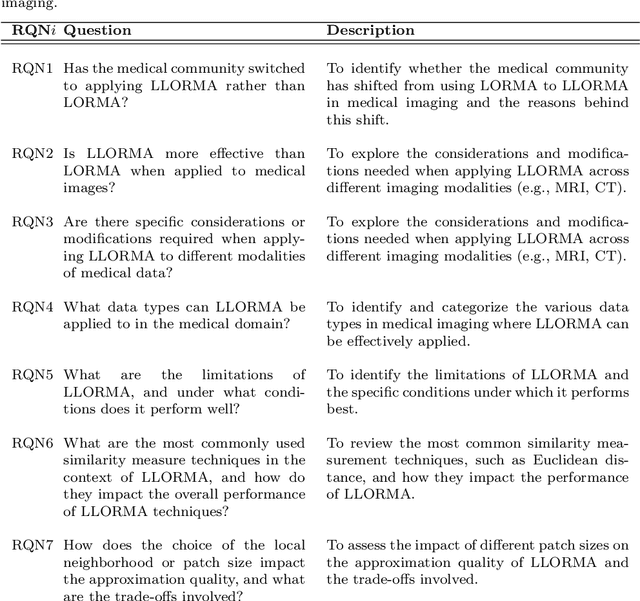
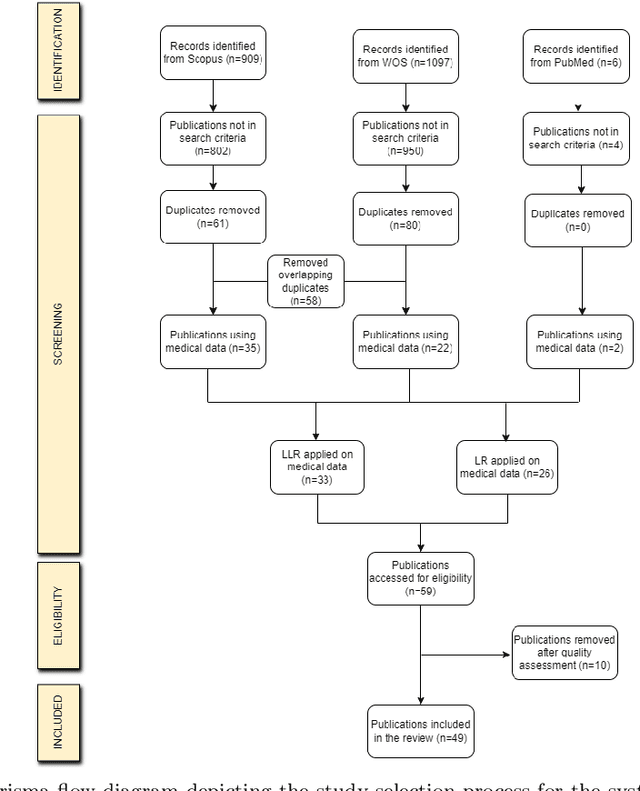
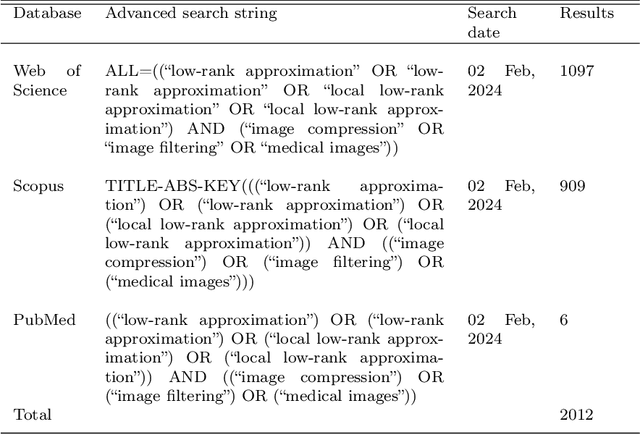
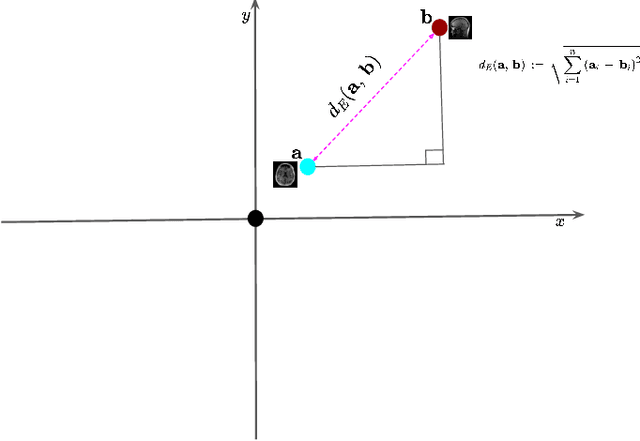
The large volume and complexity of medical imaging datasets are bottlenecks for storage, transmission, and processing. To tackle these challenges, the application of low-rank matrix approximation (LRMA) and its derivative, local LRMA (LLRMA) has demonstrated potential. This paper conducts a systematic literature review to showcase works applying LRMA and LLRMA in medical imaging. A detailed analysis of the literature identifies LRMA and LLRMA methods applied to various imaging modalities. This paper addresses the challenges and limitations associated with existing LRMA and LLRMA methods. We note a significant shift towards a preference for LLRMA in the medical imaging field since 2015, demonstrating its potential and effectiveness in capturing complex structures in medical data compared to LRMA. Acknowledging the limitations of shallow similarity methods used with LLRMA, we suggest advanced semantic image segmentation for similarity measure, explaining in detail how it can measure similar patches and their feasibility. We note that LRMA and LLRMA are mainly applied to unstructured medical data, and we propose extending their application to different medical data types, including structured and semi-structured. This paper also discusses how LRMA and LLRMA can be applied to regular data with missing entries and the impact of inaccuracies in predicting missing values and their effects. We discuss the impact of patch size and propose the use of random search (RS) to determine the optimal patch size. To enhance feasibility, a hybrid approach using Bayesian optimization and RS is proposed, which could improve the application of LRMA and LLRMA in medical imaging.
Label Assisted Autoencoder for Anomaly Detection in Power Generation Plants
Feb 06, 2023One of the critical factors that drive the economic development of a country and guarantee the sustainability of its industries is the constant availability of electricity. This is usually provided by the national electric grid. However, in developing countries where companies are emerging on a constant basis including telecommunication industries, those are still experiencing a non-stable electricity supply. Therefore, they have to rely on generators to guarantee their full functionality. Those generators depend on fuel to function and the rate of consumption gets usually high, if not monitored properly. Monitoring operation is usually carried out by a (non-expert) human. In some cases, this could be a tedious process, as some companies have reported an exaggerated high consumption rate. This work proposes a label assisted autoencoder for anomaly detection in the fuel consumed by power generating plants. In addition to the autoencoder model, we added a labelling assistance module that checks if an observation is labelled, the label is used to check the veracity of the corresponding anomaly classification given a threshold. A consensus is then reached on whether training should stop or whether the threshold should be updated or the training should continue with the search for hyper-parameters. Results show that the proposed model is highly efficient for reading anomalies with a detection accuracy of $97.20\%$ which outperforms the existing model of $96.1\%$ accuracy trained on the same dataset. In addition, the proposed model is able to classify the anomalies according to their degree of severity.