 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Parametric Indoor Lighting Estimation
Oct 19, 2019

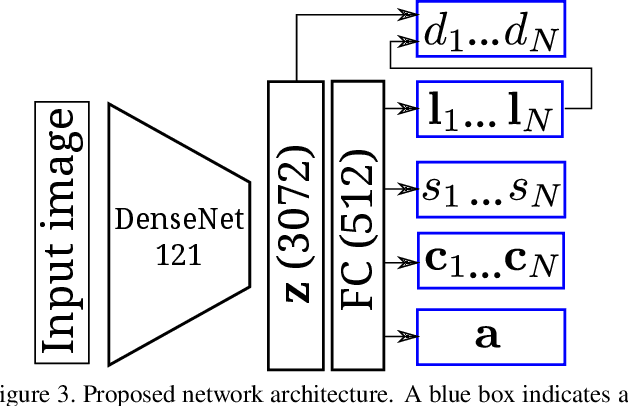

We present a method to estimate lighting from a single image of an indoor scene. Previous work has used an environment map representation that does not account for the localized nature of indoor lighting. Instead, we represent lighting as a set of discrete 3D lights with geometric and photometric parameters. We train a deep neural network to regress these parameters from a single image, on a dataset of environment maps annotated with depth. We propose a differentiable layer to convert these parameters to an environment map to compute our loss; this bypasses the challenge of establishing correspondences between estimated and ground truth lights. We demonstrate, via quantitative and qualitative evaluations, that our representation and training scheme lead to more accurate results compared to previous work, while allowing for more realistic 3D object compositing with spatially-varying lighting.
Learning to Become an Expert: Deep Networks Applied To Super-Resolution Microscopy
Mar 28, 2018
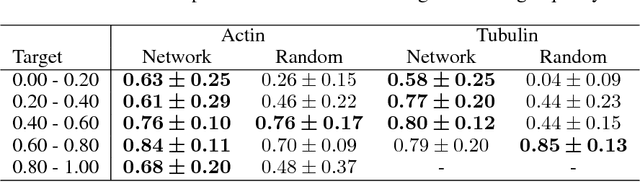

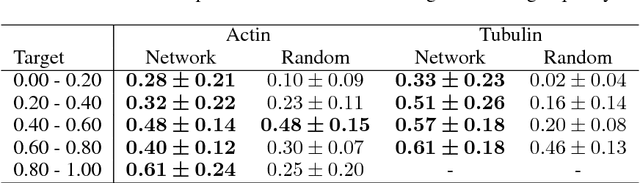
With super-resolution optical microscopy, it is now possible to observe molecular interactions in living cells. The obtained images have a very high spatial precision but their overall quality can vary a lot depending on the structure of interest and the imaging parameters. Moreover, evaluating this quality is often difficult for non-expert users. In this work, we tackle the problem of learning the quality function of super- resolution images from scores provided by experts. More specifically, we are proposing a system based on a deep neural network that can provide a quantitative quality measure of a STED image of neuronal structures given as input. We conduct a user study in order to evaluate the quality of the predictions of the neural network against those of a human expert. Results show the potential while highlighting some of the limits of the proposed approach.
Learning to Predict Indoor Illumination from a Single Image
Nov 21, 2017


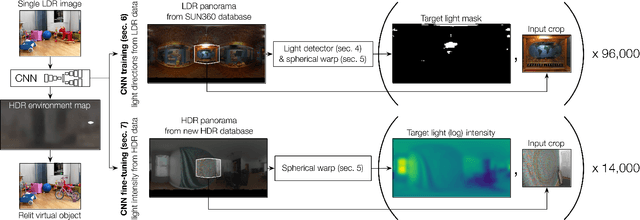
We propose an automatic method to infer high dynamic range illumination from a single, limited field-of-view, low dynamic range photograph of an indoor scene. In contrast to previous work that relies on specialized image capture, user input, and/or simple scene models, we train an end-to-end deep neural network that directly regresses a limited field-of-view photo to HDR illumination, without strong assumptions on scene geometry, material properties, or lighting. We show that this can be accomplished in a three step process: 1) we train a robust lighting classifier to automatically annotate the location of light sources in a large dataset of LDR environment maps, 2) we use these annotations to train a deep neural network that predicts the location of lights in a scene from a single limited field-of-view photo, and 3) we fine-tune this network using a small dataset of HDR environment maps to predict light intensities. This allows us to automatically recover high-quality HDR illumination estimates that significantly outperform previous state-of-the-art methods. Consequently, using our illumination estimates for applications like 3D object insertion, we can achieve results that are photo-realistic, which is validated via a perceptual user study.