 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMVA2023 Small Object Detection Challenge for Spotting Birds: Dataset, Methods, and Results
Jul 18, 2023

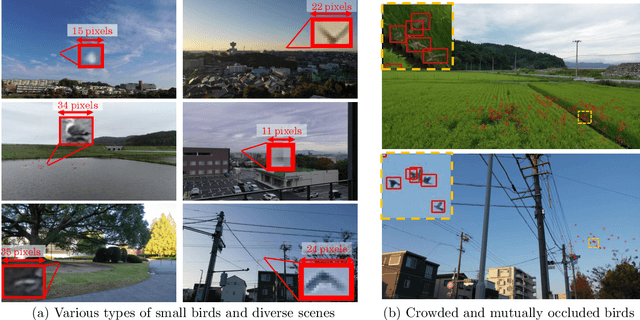
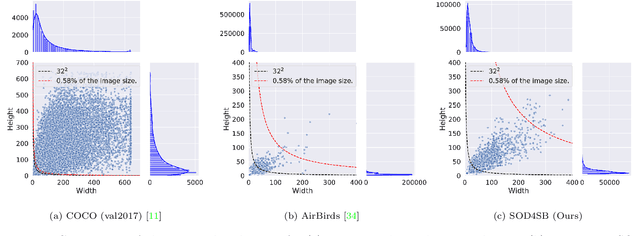
Small Object Detection (SOD) is an important machine vision topic because (i) a variety of real-world applications require object detection for distant objects and (ii) SOD is a challenging task due to the noisy, blurred, and less-informative image appearances of small objects. This paper proposes a new SOD dataset consisting of 39,070 images including 137,121 bird instances, which is called the Small Object Detection for Spotting Birds (SOD4SB) dataset. The detail of the challenge with the SOD4SB dataset is introduced in this paper. In total, 223 participants joined this challenge. This paper briefly introduces the award-winning methods. The dataset, the baseline code, and the website for evaluation on the public testset are publicly available.
IPA-CLIP: Integrating Phonetic Priors into Vision and Language Pretraining
Mar 06, 2023Recently, large-scale Vision and Language (V\&L) pretraining has become the standard backbone of many multimedia systems. While it has shown remarkable performance even in unseen situations, it often performs in ways not intuitive to humans. Particularly, they usually do not consider the pronunciation of the input, which humans would utilize to understand language, especially when it comes to unknown words. Thus, this paper inserts phonetic prior into Contrastive Language-Image Pretraining (CLIP), one of the V\&L pretrained models, to make it consider the pronunciation similarity among its pronunciation inputs. To achieve this, we first propose a phoneme embedding that utilizes the phoneme relationships provided by the International Phonetic Alphabet (IPA) chart as a phonetic prior. Next, by distilling the frozen CLIP text encoder, we train a pronunciation encoder employing the IPA-based embedding. The proposed model named IPA-CLIP comprises this pronunciation encoder and the original CLIP encoders (image and text). Quantitative evaluation reveals that the phoneme distribution on the embedding space represents phonetic relationships more accurately when using the proposed phoneme embedding. Furthermore, in some multimodal retrieval tasks, we confirm that the proposed pronunciation encoder enhances the performance of the text encoder and that the pronunciation encoder handles nonsense words in a more phonetic manner than the text encoder. Finally, qualitative evaluation verifies the correlation between the pronunciation encoder and human perception regarding pronunciation similarity.