 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal Rate of Kernel Regression in Large Dimensions
Sep 08, 2023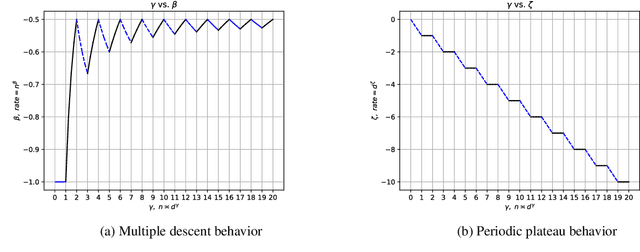
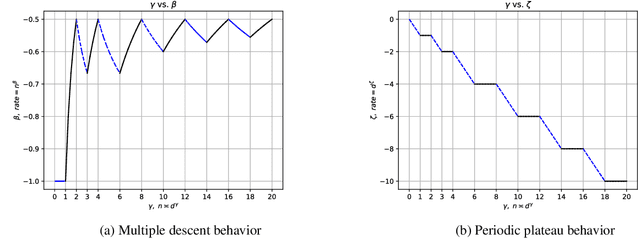
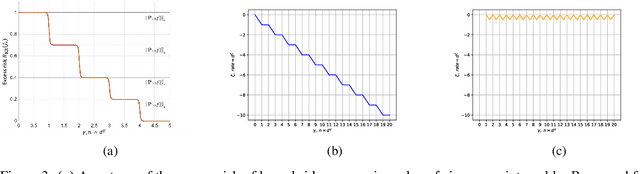
We perform a study on kernel regression for large-dimensional data (where the sample size $n$ is polynomially depending on the dimension $d$ of the samples, i.e., $n\asymp d^{\gamma}$ for some $\gamma >0$ ). We first build a general tool to characterize the upper bound and the minimax lower bound of kernel regression for large dimensional data through the Mendelson complexity $\varepsilon_{n}^{2}$ and the metric entropy $\bar{\varepsilon}_{n}^{2}$ respectively. When the target function falls into the RKHS associated with a (general) inner product model defined on $\mathbb{S}^{d}$, we utilize the new tool to show that the minimax rate of the excess risk of kernel regression is $n^{-1/2}$ when $n\asymp d^{\gamma}$ for $\gamma =2, 4, 6, 8, \cdots$. We then further determine the optimal rate of the excess risk of kernel regression for all the $\gamma>0$ and find that the curve of optimal rate varying along $\gamma$ exhibits several new phenomena including the {\it multiple descent behavior} and the {\it periodic plateau behavior}. As an application, For the neural tangent kernel (NTK), we also provide a similar explicit description of the curve of optimal rate. As a direct corollary, we know these claims hold for wide neural networks as well.
Generalization Ability of Wide Neural Networks on $\mathbb{R}$
Feb 12, 2023We perform a study on the generalization ability of the wide two-layer ReLU neural network on $\mathbb{R}$. We first establish some spectral properties of the neural tangent kernel (NTK): $a)$ $K_{d}$, the NTK defined on $\mathbb{R}^{d}$, is positive definite; $b)$ $\lambda_{i}(K_{1})$, the $i$-th largest eigenvalue of $K_{1}$, is proportional to $i^{-2}$. We then show that: $i)$ when the width $m\rightarrow\infty$, the neural network kernel (NNK) uniformly converges to the NTK; $ii)$ the minimax rate of regression over the RKHS associated to $K_{1}$ is $n^{-2/3}$; $iii)$ if one adopts the early stopping strategy in training a wide neural network, the resulting neural network achieves the minimax rate; $iv)$ if one trains the neural network till it overfits the data, the resulting neural network can not generalize well. Finally, we provide an explanation to reconcile our theory and the widely observed ``benign overfitting phenomenon''.