 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInsight Gained from Migrating a Machine Learning Model to Intelligence Processing Units
Apr 16, 2024

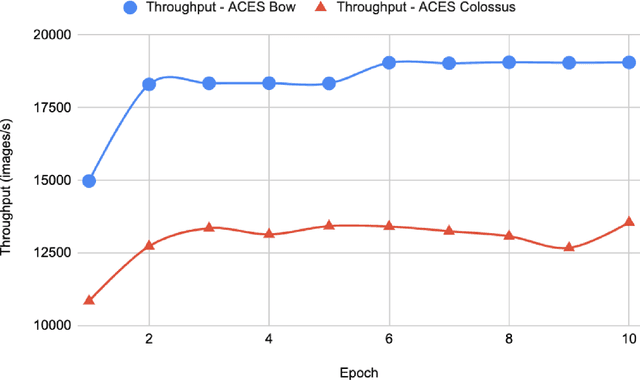
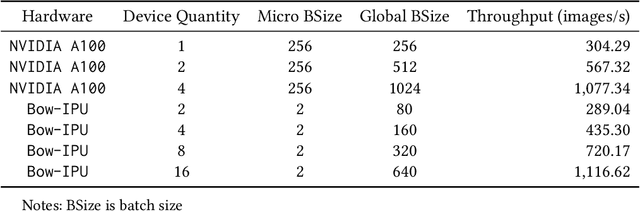
The discoveries in this paper show that Intelligence Processing Units (IPUs) offer a viable accelerator alternative to GPUs for machine learning (ML) applications within the fields of materials science and battery research. We investigate the process of migrating a model from GPU to IPU and explore several optimization techniques, including pipelining and gradient accumulation, aimed at enhancing the performance of IPU-based models. Furthermore, we have effectively migrated a specialized model to the IPU platform. This model is employed for predicting effective conductivity, a parameter crucial in ion transport processes, which govern the performance of multiple charge and discharge cycles of batteries. The model utilizes a Convolutional Neural Network (CNN) architecture to perform prediction tasks for effective conductivity. The performance of this model on the IPU is found to be comparable to its execution on GPUs. We also analyze the utilization and performance of Graphcore's Bow IPU. Through benchmark tests, we observe significantly improved performance with the Bow IPU when compared to its predecessor, the Colossus IPU.
Applications of Distributed Machine Learning for the Internet-of-Things: A Comprehensive Survey
Oct 16, 2023The emergence of new services and applications in emerging wireless networks (e.g., beyond 5G and 6G) has shown a growing demand for the usage of artificial intelligence (AI) in the Internet of Things (IoT). However, the proliferation of massive IoT connections and the availability of computing resources distributed across future IoT systems have strongly demanded the development of distributed AI for better IoT services and applications. Therefore, existing AI-enabled IoT systems can be enhanced by implementing distributed machine learning (aka distributed learning) approaches. This work aims to provide a comprehensive survey on distributed learning for IoT services and applications in emerging networks. In particular, we first provide a background of machine learning and present a preliminary to typical distributed learning approaches, such as federated learning, multi-agent reinforcement learning, and distributed inference. Then, we provide an extensive review of distributed learning for critical IoT services (e.g., data sharing and computation offloading, localization, mobile crowdsensing, and security and privacy) and IoT applications (e.g., smart healthcare, smart grid, autonomous vehicle, aerial IoT networks, and smart industry). From the reviewed literature, we also present critical challenges of distributed learning for IoT and propose several promising solutions and research directions in this emerging area.
Wirelessly Powered Federated Learning Networks: Joint Power Transfer, Data Sensing, Model Training, and Resource Allocation
Aug 09, 2023Federated learning (FL) has found many successes in wireless networks; however, the implementation of FL has been hindered by the energy limitation of mobile devices (MDs) and the availability of training data at MDs. How to integrate wireless power transfer and mobile crowdsensing towards sustainable FL solutions is a research topic entirely missing from the open literature. This work for the first time investigates a resource allocation problem in collaborative sensing-assisted sustainable FL (S2FL) networks with the goal of minimizing the total completion time. We investigate a practical harvesting-sensing-training-transmitting protocol in which energy-limited MDs first harvest energy from RF signals, use it to gain a reward for user participation, sense the training data from the environment, train the local models at MDs, and transmit the model updates to the server. The total completion time minimization problem of jointly optimizing power transfer, transmit power allocation, data sensing, bandwidth allocation, local model training, and data transmission is complicated due to the non-convex objective function, highly non-convex constraints, and strongly coupled variables. We propose a computationally-efficient path-following algorithm to obtain the optimal solution via the decomposition technique. In particular, inner convex approximations are developed for the resource allocation subproblem, and the subproblems are performed alternatively in an iterative fashion. Simulation results are provided to evaluate the effectiveness of the proposed S2FL algorithm in reducing the completion time up to 21.45% in comparison with other benchmark schemes. Further, we investigate an extension of our work from frequency division multiple access (FDMA) to non-orthogonal multiple access (NOMA) and show that NOMA can speed up the total completion time 8.36% on average of the considered FL system.