 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid Dynamic Pruning: A Pathway to Efficient Transformer Inference
Jul 17, 2024



In the world of deep learning, Transformer models have become very significant, leading to improvements in many areas from understanding language to recognizing images, covering a wide range of applications. Despite their success, the deployment of these models in real-time applications, particularly on edge devices, poses significant challenges due to their quadratic computational intensity and memory demands. To overcome these challenges we introduce a novel Hybrid Dynamic Pruning (HDP), an efficient algorithm-architecture co-design approach that accelerates transformers using head sparsity, block sparsity and approximation opportunities to reduce computations in attention and reduce memory access. With the observation of the huge redundancy in attention scores and attention heads, we propose a novel integer-based row-balanced block pruning to prune unimportant blocks in the attention matrix at run time, also propose integer-based head pruning to detect and prune unimportant heads at an early stage at run time. Also we propose an approximation method that reduces attention computations. To efficiently support these methods with lower latency and power efficiency, we propose a HDP co-processor architecture.
Area and Power Efficient FFT/IFFT Processor for FALCON Post-Quantum Cryptography
Jan 19, 2024



Quantum computing is an emerging technology on the verge of reshaping industries, while simultaneously challenging existing cryptographic algorithms. FALCON, a recent standard quantum-resistant digital signature, presents a challenging hardware implementation due to its extensive non-integer polynomial operations, necessitating FFT over the ring $\mathbb{Q}[x]/(x^n+1)$. This paper introduces an ultra-low power and compact processor tailored for FFT/IFFT operations over the ring, specifically optimized for FALCON applications on resource-constrained edge devices. The proposed processor incorporates various optimization techniques, including twiddle factor compression and conflict-free scheduling. In an ASIC implementation using a 22 nm GF process, the proposed processor demonstrates an area occupancy of 0.15 mm$^2$ and a power consumption of 12.6 mW at an operating frequency of 167 MHz. Since a hardware implementation of FFT/IFFT over the ring is currently non-existent, the execution time achieved by this processor is compared to the software implementation of FFT/IFFT of FALCON on a Raspberry Pi 4 with Cortex-A72, where the proposed processor achieves a speedup of up to 2.3$\times$. Furthermore, in comparison to dedicated state-of-the-art hardware accelerators for classic FFT, this processor occupies 42\% less area and consumes 83\% less power, on average. This suggests that the proposed hardware design offers a promising solution for implementing FALCON on resource-constrained devices.
Number Systems for Deep Neural Network Architectures: A Survey
Jul 11, 2023Deep neural networks (DNNs) have become an enabling component for a myriad of artificial intelligence applications. DNNs have shown sometimes superior performance, even compared to humans, in cases such as self-driving, health applications, etc. Because of their computational complexity, deploying DNNs in resource-constrained devices still faces many challenges related to computing complexity, energy efficiency, latency, and cost. To this end, several research directions are being pursued by both academia and industry to accelerate and efficiently implement DNNs. One important direction is determining the appropriate data representation for the massive amount of data involved in DNN processing. Using conventional number systems has been found to be sub-optimal for DNNs. Alternatively, a great body of research focuses on exploring suitable number systems. This article aims to provide a comprehensive survey and discussion about alternative number systems for more efficient representations of DNN data. Various number systems (conventional/unconventional) exploited for DNNs are discussed. The impact of these number systems on the performance and hardware design of DNNs is considered. In addition, this paper highlights the challenges associated with each number system and various solutions that are proposed for addressing them. The reader will be able to understand the importance of an efficient number system for DNN, learn about the widely used number systems for DNN, understand the trade-offs between various number systems, and consider various design aspects that affect the impact of number systems on DNN performance. In addition, the recent trends and related research opportunities will be highlighted
An Effective Spatial Modulation Based Scheme for Indoor VLC Systems
Jan 19, 2022We propose an enhanced spatial modulation (SM)-based scheme for indoor visible light communication systems. This scheme enhances the achievable throughput of conventional SM schemes by transmitting higher order complex modulation symbol, which is decomposed into three different parts. These parts carry the amplitude, phase, and quadrant components of the complex symbol, which are then represented by unipolar pulse amplitude modulation (PAM) symbols. Superposition coding is exploited to allocate a fraction of the total power to each part before they are all multiplexed and transmitted simultaneously, exploiting the entire available bandwidth. At the receiver, a two-step decoding process is proposed to decode the active light emitting diode index before the complex symbol is retrieved. It is shown that at higher spectral efficiency values, the proposed modulation scheme outperforms conventional SM schemes with PAM symbols in terms of average symbol error rate (ASER), and hence, enhancing the system throughput. Furthermore, since the performance of the proposed modulation scheme is sensitive to the power allocation factors, we formulated an ASER optimization problem and propose a sub-optimal solution using successive convex programming (SCP). Notably, the proposed algorithm converges after only few iterations, whilst the performance with the optimized power allocation coefficients outperforms both random and fixed power allocation.
Space-Time Block Coded Spatial Modulation for Indoor Visible Light Communications
Nov 06, 2021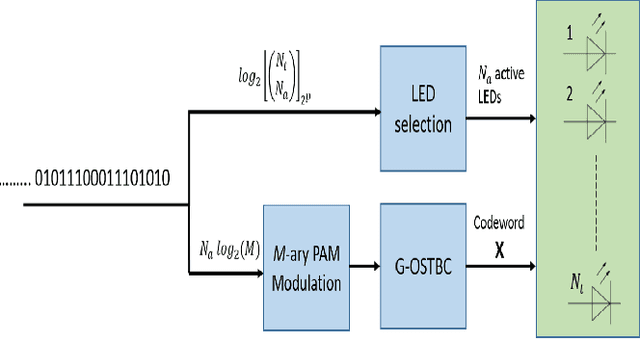
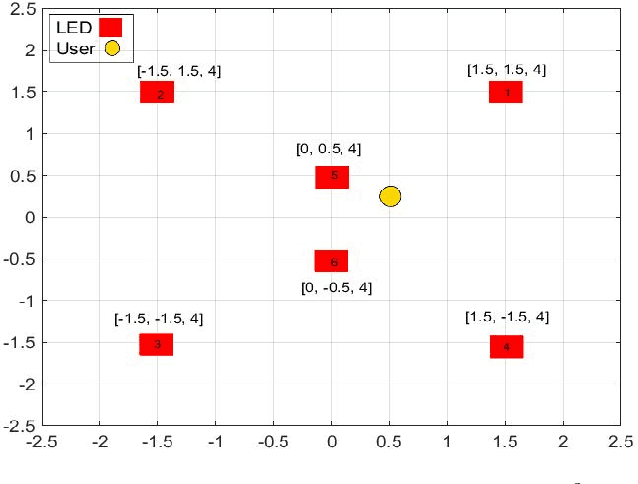
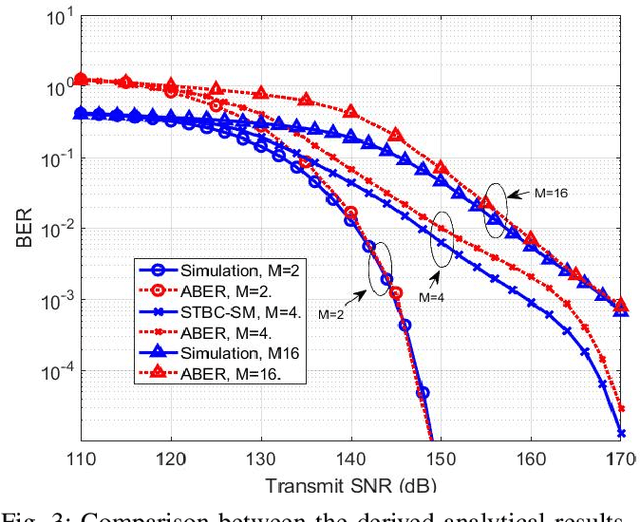
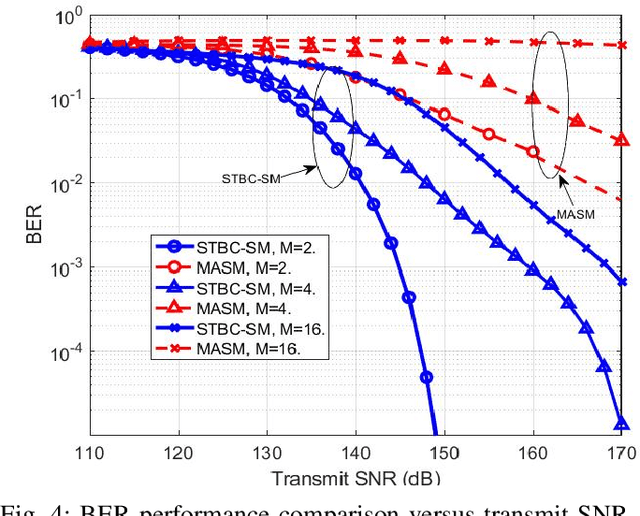
Visible light communication (VLC) has been recognized as a promising technology for handling the continuously increasing quality of service and connectivity requirements in modern wireless communications, particularly in indoor scenarios. In this context, the present work considers the integration of two distinct modulation schemes, namely spatial modulation (SM) with space time block codes (STBCs), aiming at improving the overall VLC system reliability. Based on this and in order to further enhance the achievable transmission data rate, we integrate quasi-orthogonal STBC (QOSTBC) with SM, since relaxing the orthogonality condition of OSTBC ultimately provides a higher coding rate. Then, we generalize the developed results to any number of active light-emitting diodes (LEDs) and any M-ary pulse amplitude modulation size. Furthermore, we derive a tight and tractable upper bound for the corresponding bit error rate (BER) by considering a simple two-step decoding procedure to detect the indices of the transmitting LEDs and then decode the signal domain symbols. Notably, the obtained results demonstrate that QOSTBC with SM enhances the achievable BER compared to SM with repetition coding (RC-SM). Finally, we compare STBC-SM with both multiple active SM (MASM) and RC-SM in terms of the achievable BER and overall data rate, which further justifies the usefulness of the proposed scheme.
Towards Federated Learning-Enabled Visible Light Communication in 6G Systems
Oct 07, 2021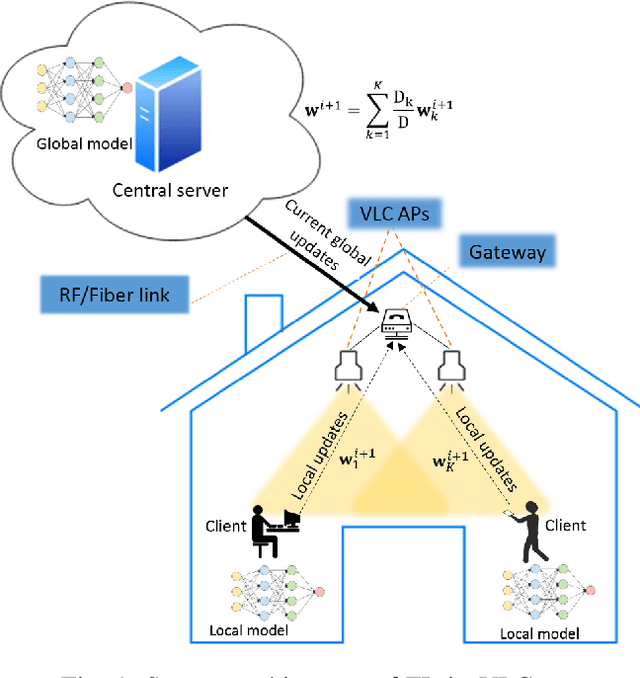
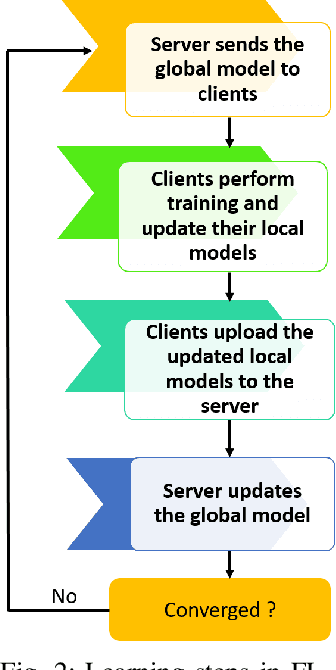
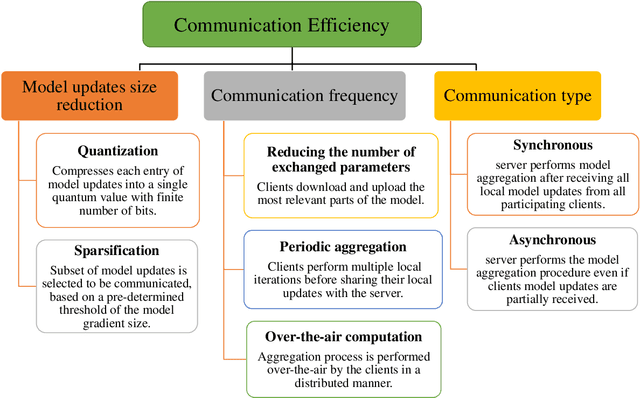
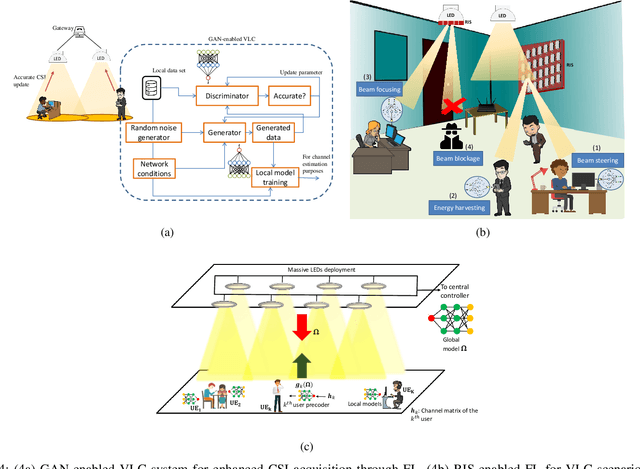
Visible light communication (VLC) technology was introduced as a key enabler for the next generation of wireless networks, mainly thanks to its simple and low-cost implementation. However, several challenges prohibit the realization of the full potentials of VLC, namely, limited modulation bandwidth, ambient light interference, optical diffuse reflection effects, devices non-linearity, and random receiver orientation. On the contrary, centralized machine learning (ML) techniques have demonstrated a significant potential in handling different challenges relating to wireless communication systems. Specifically, it was shown that ML algorithms exhibit superior capabilities in handling complicated network tasks, such as channel equalization, estimation and modeling, resources allocation, and opportunistic spectrum access control, to name a few. Nevertheless, concerns pertaining to privacy and communication overhead when sharing raw data of the involved clients with a server constitute major bottlenecks in the implementation of centralized ML techniques. This has motivated the emergence of a new distributed ML paradigm, namely federated learning (FL), which can reduce the cost associated with transferring raw data, and preserve privacy by training ML models locally and collaboratively at the clients' side. Hence, it becomes evident that integrating FL into VLC networks can provide ubiquitous and reliable implementation of VLC systems. With this motivation, this is the first in-depth review in the literature on the application of FL in VLC networks. To that end, besides the different architectures and related characteristics of FL, we provide a thorough overview on the main design aspects of FL based VLC systems. Finally, we also highlight some potential future research directions of FL that are envisioned to substantially enhance the performance and robustness of VLC systems.
Deep Neural Networks Based Weight Approximation and Computation Reuse for 2-D Image Classification
Apr 28, 2021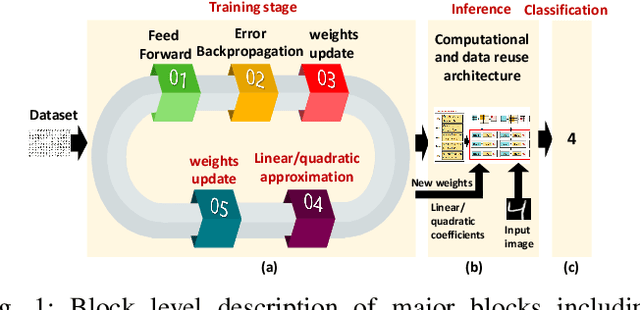
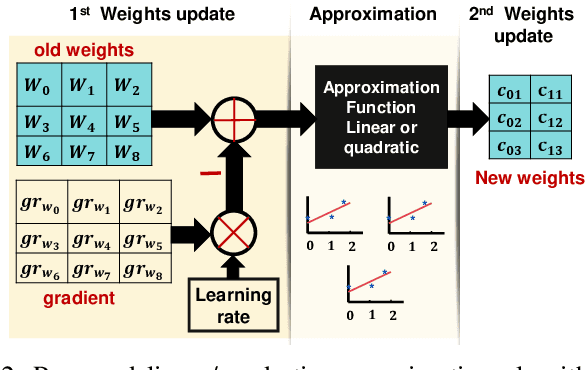


Deep Neural Networks (DNNs) are computationally and memory intensive, which makes their hardware implementation a challenging task especially for resource constrained devices such as IoT nodes. To address this challenge, this paper introduces a new method to improve DNNs performance by fusing approximate computing with data reuse techniques to be used for image recognition applications. DNNs weights are approximated based on the linear and quadratic approximation methods during the training phase, then, all of the weights are replaced with the linear/quadratic coefficients to execute the inference in a way where different weights could be computed using the same coefficients. This leads to a repetition of the weights across the processing element (PE) array, which in turn enables the reuse of the DNN sub-computations (computational reuse) and leverage the same data (data reuse) to reduce DNNs computations, memory accesses, and improve energy efficiency albeit at the cost of increased training time. Complete analysis for both MNIST and CIFAR 10 datasets is presented for image recognition , where LeNet 5 revealed a reduction in the number of parameters by a factor of 1211.3x with a drop of less than 0.9% in accuracy. When compared to the state of the art Row Stationary (RS) method, the proposed architecture saved 54% of the total number of adders and multipliers needed. Overall, the proposed approach is suitable for IoT edge devices as it reduces the memory size requirement as well as the number of needed memory accesses.