 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid Dynamic Pruning: A Pathway to Efficient Transformer Inference
Jul 17, 2024



In the world of deep learning, Transformer models have become very significant, leading to improvements in many areas from understanding language to recognizing images, covering a wide range of applications. Despite their success, the deployment of these models in real-time applications, particularly on edge devices, poses significant challenges due to their quadratic computational intensity and memory demands. To overcome these challenges we introduce a novel Hybrid Dynamic Pruning (HDP), an efficient algorithm-architecture co-design approach that accelerates transformers using head sparsity, block sparsity and approximation opportunities to reduce computations in attention and reduce memory access. With the observation of the huge redundancy in attention scores and attention heads, we propose a novel integer-based row-balanced block pruning to prune unimportant blocks in the attention matrix at run time, also propose integer-based head pruning to detect and prune unimportant heads at an early stage at run time. Also we propose an approximation method that reduces attention computations. To efficiently support these methods with lower latency and power efficiency, we propose a HDP co-processor architecture.
Area and Power Efficient FFT/IFFT Processor for FALCON Post-Quantum Cryptography
Jan 19, 2024



Quantum computing is an emerging technology on the verge of reshaping industries, while simultaneously challenging existing cryptographic algorithms. FALCON, a recent standard quantum-resistant digital signature, presents a challenging hardware implementation due to its extensive non-integer polynomial operations, necessitating FFT over the ring $\mathbb{Q}[x]/(x^n+1)$. This paper introduces an ultra-low power and compact processor tailored for FFT/IFFT operations over the ring, specifically optimized for FALCON applications on resource-constrained edge devices. The proposed processor incorporates various optimization techniques, including twiddle factor compression and conflict-free scheduling. In an ASIC implementation using a 22 nm GF process, the proposed processor demonstrates an area occupancy of 0.15 mm$^2$ and a power consumption of 12.6 mW at an operating frequency of 167 MHz. Since a hardware implementation of FFT/IFFT over the ring is currently non-existent, the execution time achieved by this processor is compared to the software implementation of FFT/IFFT of FALCON on a Raspberry Pi 4 with Cortex-A72, where the proposed processor achieves a speedup of up to 2.3$\times$. Furthermore, in comparison to dedicated state-of-the-art hardware accelerators for classic FFT, this processor occupies 42\% less area and consumes 83\% less power, on average. This suggests that the proposed hardware design offers a promising solution for implementing FALCON on resource-constrained devices.
A Heterogeneous RISC-V based SoC for Secure Nano-UAV Navigation
Jan 07, 2024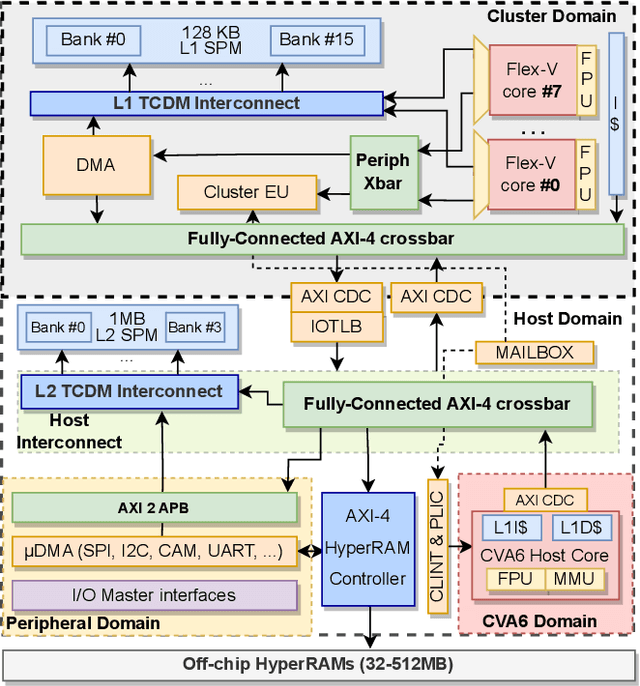
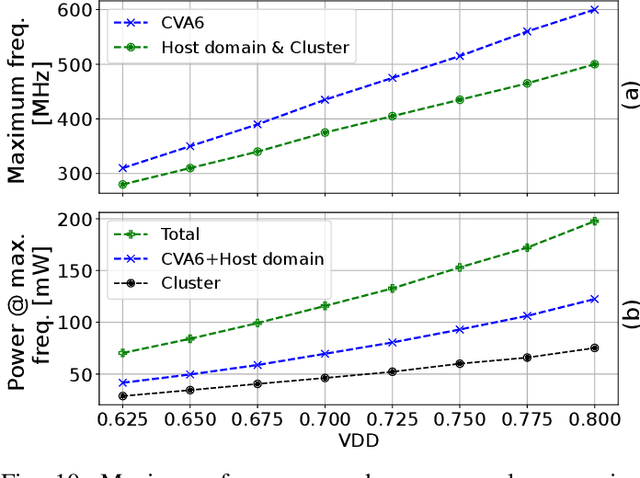
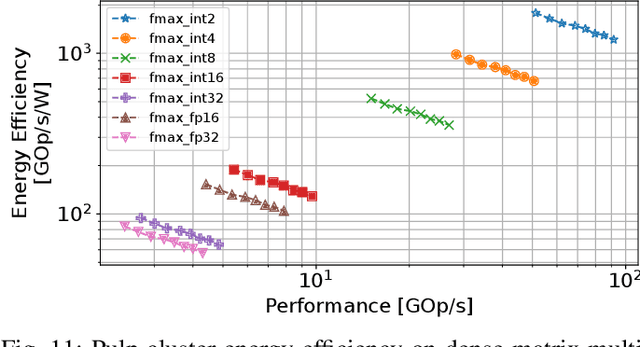
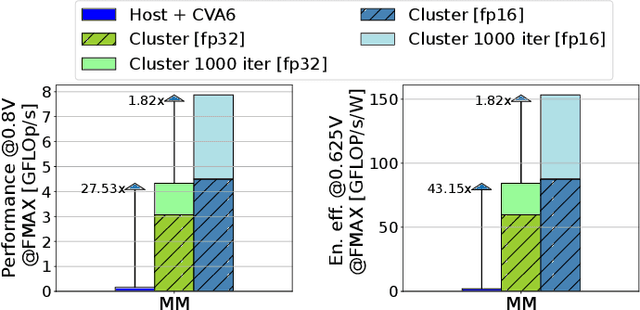
The rapid advancement of energy-efficient parallel ultra-low-power (ULP) ucontrollers units (MCUs) is enabling the development of autonomous nano-sized unmanned aerial vehicles (nano-UAVs). These sub-10cm drones represent the next generation of unobtrusive robotic helpers and ubiquitous smart sensors. However, nano-UAVs face significant power and payload constraints while requiring advanced computing capabilities akin to standard drones, including real-time Machine Learning (ML) performance and the safe co-existence of general-purpose and real-time OSs. Although some advanced parallel ULP MCUs offer the necessary ML computing capabilities within the prescribed power limits, they rely on small main memories (<1MB) and ucontroller-class CPUs with no virtualization or security features, and hence only support simple bare-metal runtimes. In this work, we present Shaheen, a 9mm2 200mW SoC implemented in 22nm FDX technology. Differently from state-of-the-art MCUs, Shaheen integrates a Linux-capable RV64 core, compliant with the v1.0 ratified Hypervisor extension and equipped with timing channel protection, along with a low-cost and low-power memory controller exposing up to 512MB of off-chip low-cost low-power HyperRAM directly to the CPU. At the same time, it integrates a fully programmable energy- and area-efficient multi-core cluster of RV32 cores optimized for general-purpose DSP as well as reduced- and mixed-precision ML. To the best of the authors' knowledge, it is the first silicon prototype of a ULP SoC coupling the RV64 and RV32 cores in a heterogeneous host+accelerator architecture fully based on the RISC-V ISA. We demonstrate the capabilities of the proposed SoC on a wide range of benchmarks relevant to nano-UAV applications. The cluster can deliver up to 90GOp/s and up to 1.8TOp/s/W on 2-bit integer kernels and up to 7.9GFLOp/s and up to 150GFLOp/s/W on 16-bit FP kernels.
Number Systems for Deep Neural Network Architectures: A Survey
Jul 11, 2023Deep neural networks (DNNs) have become an enabling component for a myriad of artificial intelligence applications. DNNs have shown sometimes superior performance, even compared to humans, in cases such as self-driving, health applications, etc. Because of their computational complexity, deploying DNNs in resource-constrained devices still faces many challenges related to computing complexity, energy efficiency, latency, and cost. To this end, several research directions are being pursued by both academia and industry to accelerate and efficiently implement DNNs. One important direction is determining the appropriate data representation for the massive amount of data involved in DNN processing. Using conventional number systems has been found to be sub-optimal for DNNs. Alternatively, a great body of research focuses on exploring suitable number systems. This article aims to provide a comprehensive survey and discussion about alternative number systems for more efficient representations of DNN data. Various number systems (conventional/unconventional) exploited for DNNs are discussed. The impact of these number systems on the performance and hardware design of DNNs is considered. In addition, this paper highlights the challenges associated with each number system and various solutions that are proposed for addressing them. The reader will be able to understand the importance of an efficient number system for DNN, learn about the widely used number systems for DNN, understand the trade-offs between various number systems, and consider various design aspects that affect the impact of number systems on DNN performance. In addition, the recent trends and related research opportunities will be highlighted
C3PU: Cross-Coupling Capacitor Processing Unit Using Analog-Mixed Signal In-Memory Computing for AI Inference
Oct 11, 2021
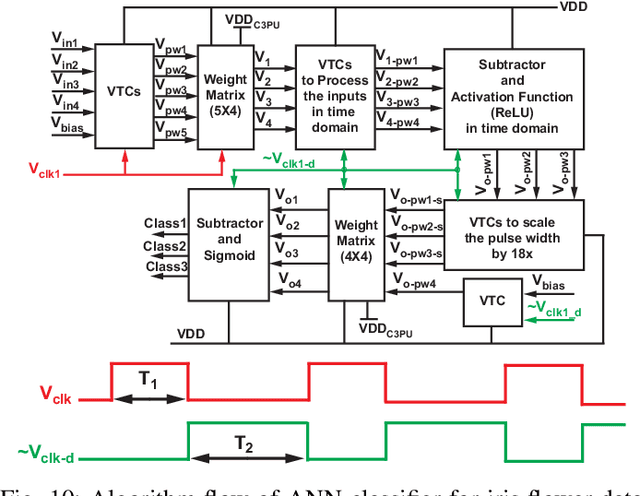
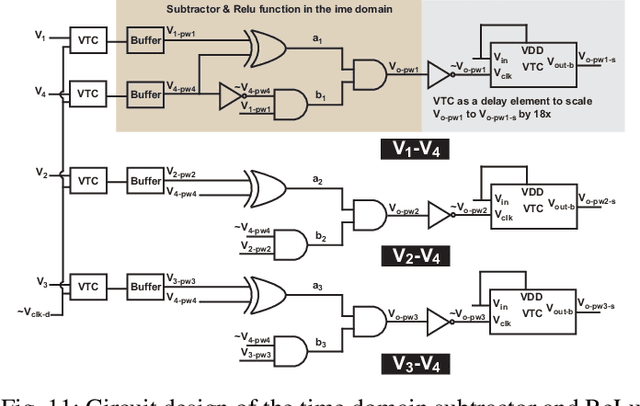
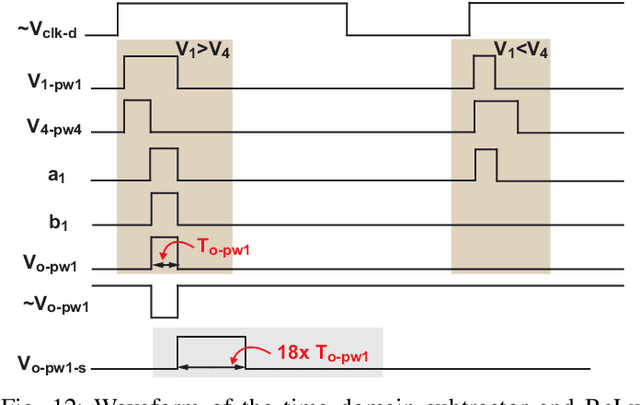
This paper presents a novel cross-coupling capacitor processing unit (C3PU) that supports analog-mixed signal in memory computing to perform multiply-and-accumulate (MAC) operations. The C3PU consists of a capacitive unit, a CMOS transistor, and a voltage-to-time converter (VTC). The capacitive unit serves as a computational element that holds the multiplier operand and performs multiplication once the multiplicand is applied at the terminal. The multiplicand is the input voltage that is converted to a pulse width signal using a low power VTC. The transistor transfers this multiplication where a voltage level is generated. A demonstrator of 5x4 C3PU array that is capable of implementing 4 MAC units is presented. The design has been verified using Monte Carlo simulation in 65 nm technology. The 5x4 C3PU consumed energy of 66.4 fJ/MAC at 0.3 V voltage supply with an error of 5.7%. The proposed unit achieves lower energy and occupies a smaller area by 3.4x and 3.6x, respectively, with similar error value when compared to a digital-based 8x4-bit fixed point MAC unit. The C3PU has been utilized through an iris fower classification utilizing an artificial neural network which achieved a 90% classification accuracy compared to ideal accuracy of 96.67% using MATLAB.
Deep Neural Networks Based Weight Approximation and Computation Reuse for 2-D Image Classification
Apr 28, 2021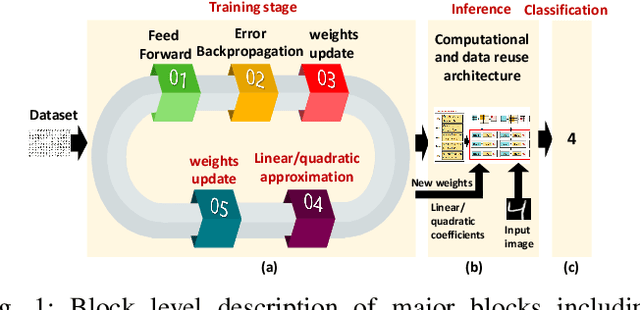
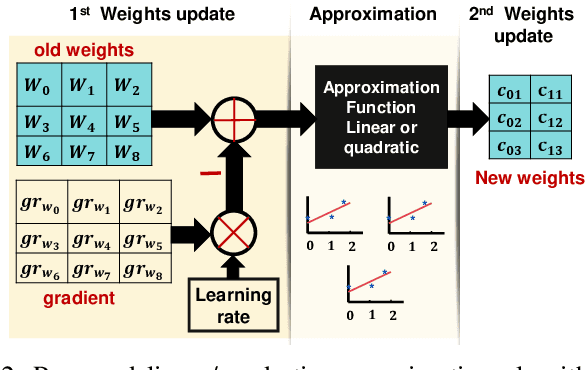


Deep Neural Networks (DNNs) are computationally and memory intensive, which makes their hardware implementation a challenging task especially for resource constrained devices such as IoT nodes. To address this challenge, this paper introduces a new method to improve DNNs performance by fusing approximate computing with data reuse techniques to be used for image recognition applications. DNNs weights are approximated based on the linear and quadratic approximation methods during the training phase, then, all of the weights are replaced with the linear/quadratic coefficients to execute the inference in a way where different weights could be computed using the same coefficients. This leads to a repetition of the weights across the processing element (PE) array, which in turn enables the reuse of the DNN sub-computations (computational reuse) and leverage the same data (data reuse) to reduce DNNs computations, memory accesses, and improve energy efficiency albeit at the cost of increased training time. Complete analysis for both MNIST and CIFAR 10 datasets is presented for image recognition , where LeNet 5 revealed a reduction in the number of parameters by a factor of 1211.3x with a drop of less than 0.9% in accuracy. When compared to the state of the art Row Stationary (RS) method, the proposed architecture saved 54% of the total number of adders and multipliers needed. Overall, the proposed approach is suitable for IoT edge devices as it reduces the memory size requirement as well as the number of needed memory accesses.