 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Implementation of Fixed-point Exponential Function for Machine Learning and Signal Processing Accelerators
Dec 04, 2021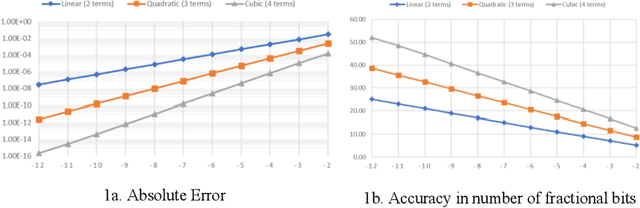
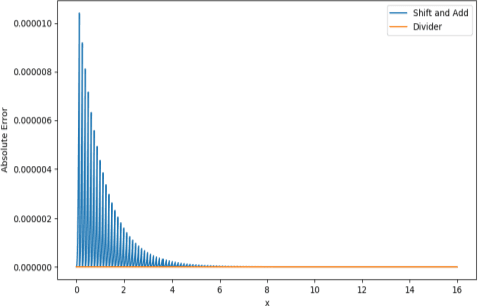
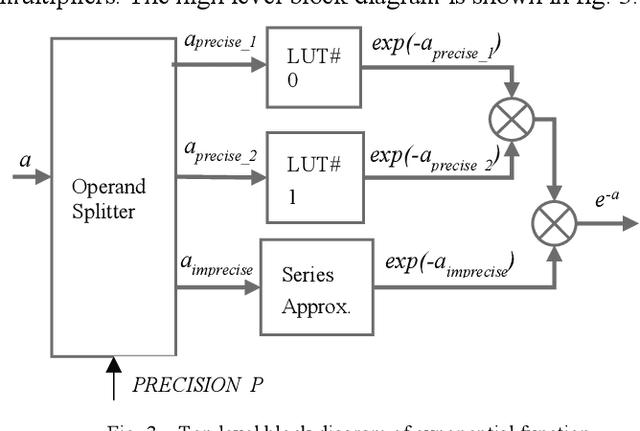
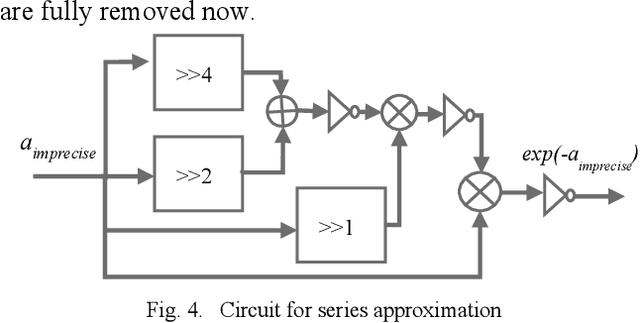
The natural exponential function is widely used in modeling many engineering and scientific systems. It is also an integral part of many neural network activation function such as sigmoid, tanh, ELU, RBF etc. Dedicated hardware accelerator and processors are designed for faster execution of such applications. Such accelerators can immensely benefit from an optimal implementation of exponential function. This can be achieved for most applications with the knowledge that the exponential function for a negative domain is more widely used than the positive domain. This paper presents an optimized implementation of exponential function for variable precision fixed point negative input. The implementation presented here significantly reduces the number of multipliers and adders. This is further optimized using mixed world-length implementation for the series expansion. The reduction in area and power consumption is more than 30% and 50% respectively over previous equivalent method.
* -
On the Impact of Partial Sums on Interconnect Bandwidth and Memory Accesses in a DNN Accelerator
Nov 02, 2020

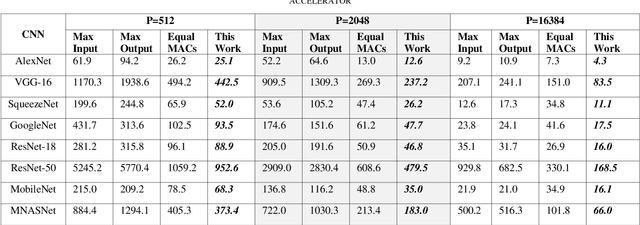

Dedicated accelerators are being designed to address the huge resource requirement of the deep neural network (DNN) applications. The power, performance and area (PPA) constraints limit the number of MACs available in these accelerators. The convolution layers which require huge number of MACs are often partitioned into multiple iterative sub-tasks. This puts huge pressure on the available system resources such as interconnect and memory bandwidth. The optimal partitioning of the feature maps for these sub-tasks can reduce the bandwidth requirement substantially. Some accelerators avoid off-chip or interconnect transfers by implementing local memories; however, the memory accesses are still performed and a reduced bandwidth can help in saving power in such architectures. In this paper, we propose a first order analytical method to partition the feature maps for optimal bandwidth and evaluate the impact of such partitioning on the bandwidth. This bandwidth can be saved by designing an active memory controller which can perform basic arithmetic operations. It is shown that the optimal partitioning and active memory controller can achieve up to 40% bandwidth reduction.
Comparative Analysis of Polynomial and Rational Approximations of Hyperbolic Tangent Function for VLSI Implementation
Jul 13, 2020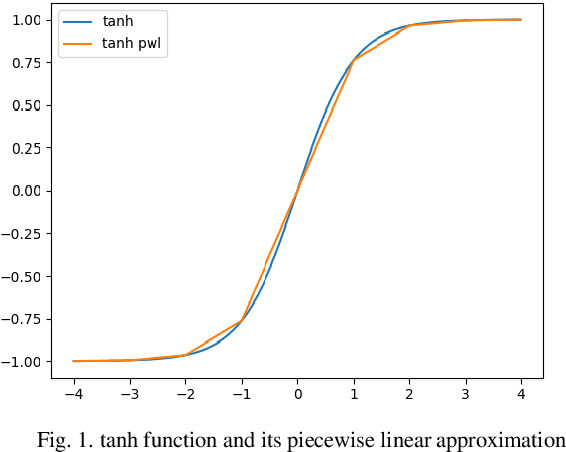

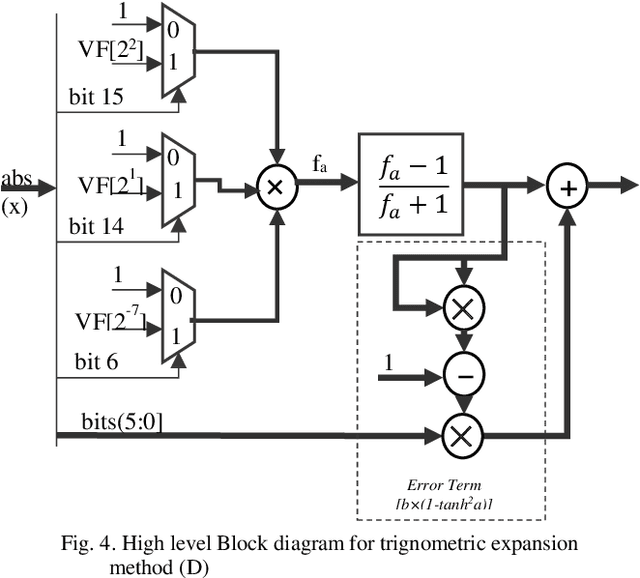
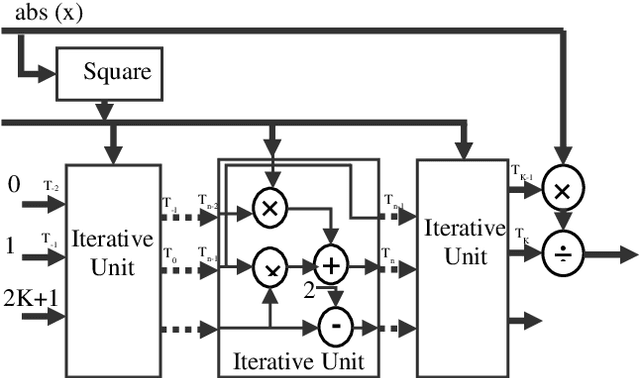
Deep neural networks yield the state-of-the-art results in many computer vision and human machine interface applications such as object detection, speech recognition etc. Since, these networks are computationally expensive, customized accelerators are designed for achieving the required performance at lower cost and power. One of the key building blocks of these neural networks is non-linear activation function such as sigmoid, hyperbolic tangent (tanh), and ReLU. A low complexity accurate hardware implementation of the activation function is required to meet the performance and area targets of the neural network accelerators. Even though, various methods and implementations of tanh activation function have been published, a comparative study is missing. This paper presents comparative analysis of polynomial and rational methods and their hardware implementation.
Hardware Implementation of Hyperbolic Tangent Function using Catmull-Rom Spline Interpolation
Jul 13, 2020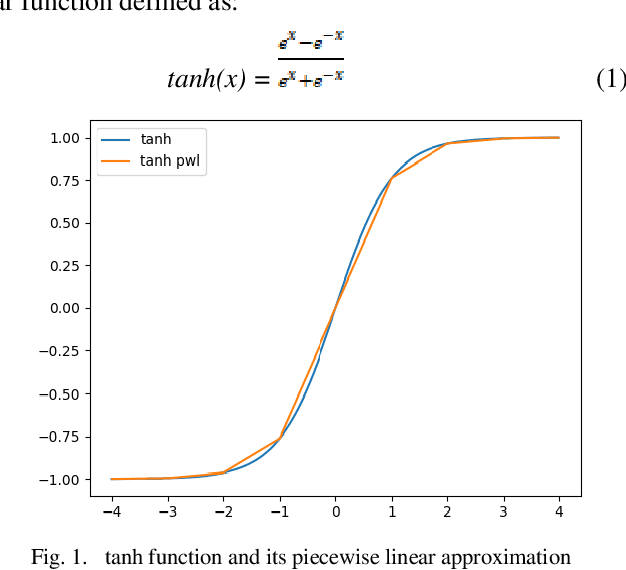
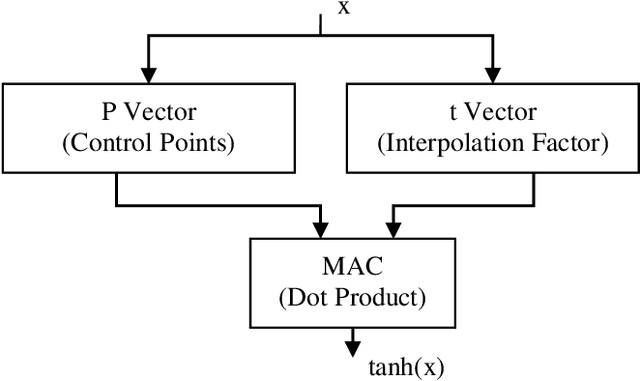

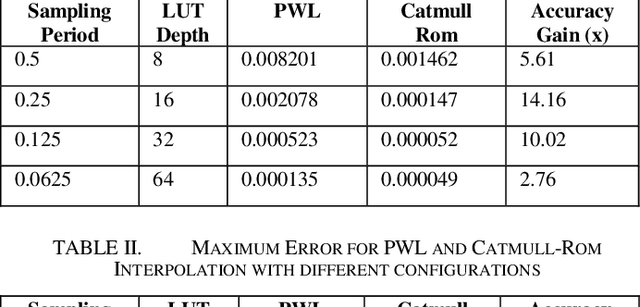
Deep neural networks yield the state of the art results in many computer vision and human machine interface tasks such as object recognition, speech recognition etc. Since, these networks are computationally expensive, customized accelerators are designed for achieving the required performance at lower cost and power. One of the key building blocks of these neural networks is non-linear activation function such as sigmoid, hyperbolic tangent (tanh), and ReLU. A low complexity accurate hardware implementation of the activation function is required to meet the performance and area targets of the neural network accelerators. This paper presents an implementation of tanh function using the Catmull-Rom spline interpolation. State of the art results are achieved using this method with comparatively smaller logic area.
DRACO: Co-Optimizing Hardware Utilization, and Performance of DNNs on Systolic Accelerator
Jun 26, 2020
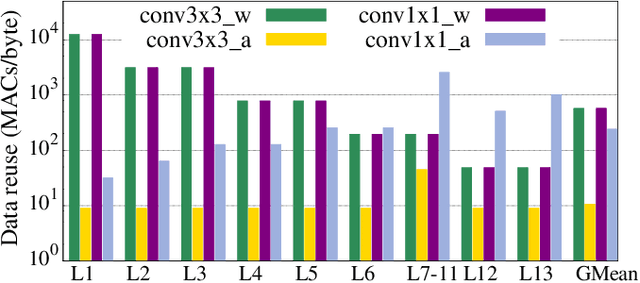


The number of processing elements (PEs) in a fixed-sized systolic accelerator is well matched for large and compute-bound DNNs; whereas, memory-bound DNNs suffer from PE underutilization and fail to achieve peak performance and energy efficiency. To mitigate this, specialized dataflow and/or micro-architectural techniques have been proposed. However, due to the longer development cycle and the rapid pace of evolution in the deep learning fields, these hardware-based solutions can be obsolete and ineffective in dealing with PE underutilization for state-of-the-art DNNs. In this work, we address the challenge of PE underutilization at the algorithm front and propose data reuse aware co-optimization (DRACO). This improves the PE utilization of memory-bound DNNs without any additional need for dataflow/micro-architecture modifications. Furthermore, unlike the previous co-optimization methods, DRACO not only maximizes performance and energy efficiency but also improves the predictive performance of DNNs. To the best of our knowledge, DRACO is the first work that resolves the resource underutilization challenge at the algorithm level and demonstrates a trade-off between computational efficiency, PE utilization, and predictive performance of DNN. Compared to the state-of-the-art row stationary dataflow, DRACO achieves 41.8% and 42.6% improvement in average PE utilization and inference latency (respectively) with negligible loss in predictive performance in MobileNetV1 on a $64\times64$ systolic array. DRACO provides seminal insights for utilization-aware DNN design methodologies that can fully leverage the computation power of systolic array-based hardware accelerators.
Spoken Language Identification Using Hybrid Feature Extraction Methods
Mar 29, 2010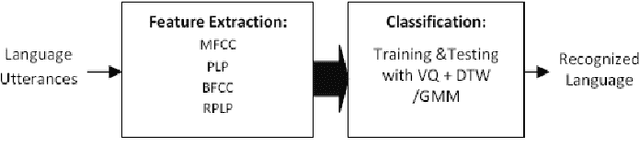
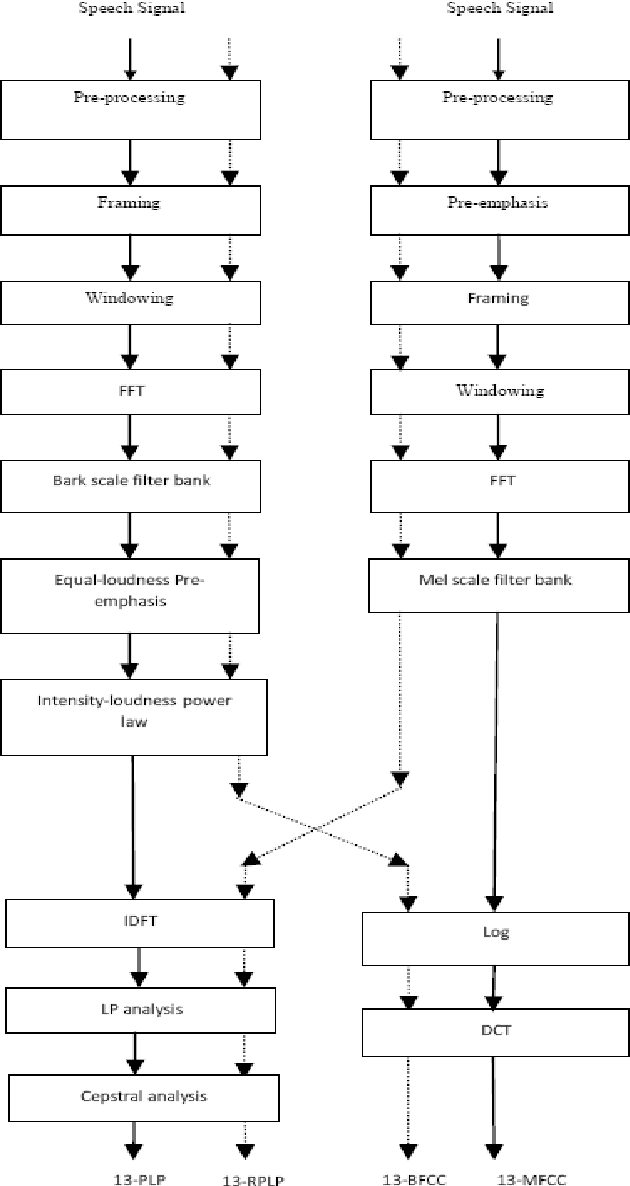
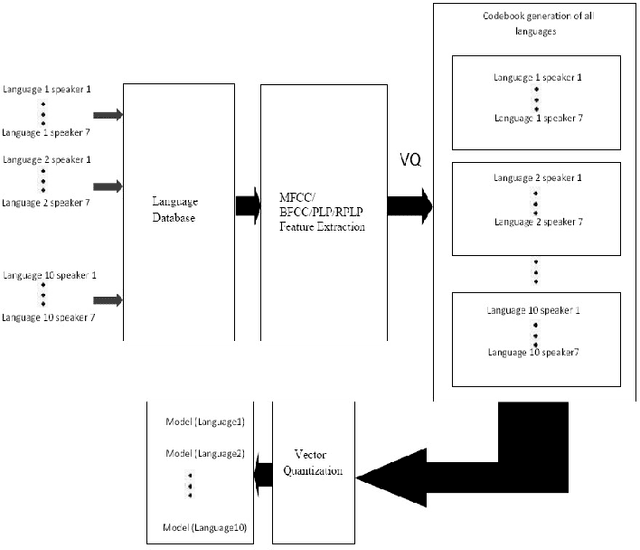
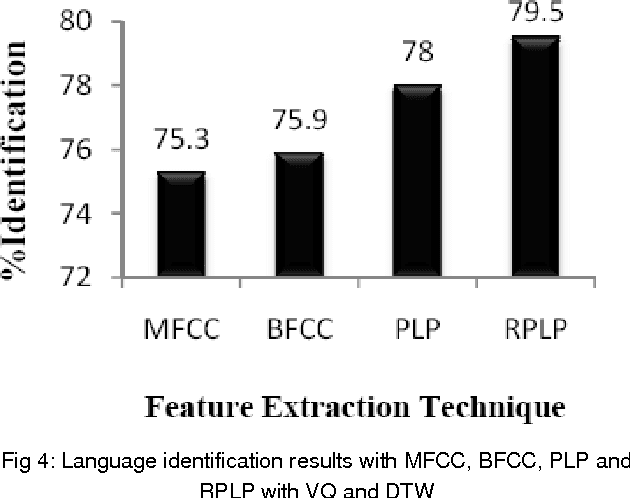
This paper introduces and motivates the use of hybrid robust feature extraction technique for spoken language identification (LID) system. The speech recognizers use a parametric form of a signal to get the most important distinguishable features of speech signal for recognition task. In this paper Mel-frequency cepstral coefficients (MFCC), Perceptual linear prediction coefficients (PLP) along with two hybrid features are used for language Identification. Two hybrid features, Bark Frequency Cepstral Coefficients (BFCC) and Revised Perceptual Linear Prediction Coefficients (RPLP) were obtained from combination of MFCC and PLP. Two different classifiers, Vector Quantization (VQ) with Dynamic Time Warping (DTW) and Gaussian Mixture Model (GMM) were used for classification. The experiment shows better identification rate using hybrid feature extraction techniques compared to conventional feature extraction methods.BFCC has shown better performance than MFCC with both classifiers. RPLP along with GMM has shown best identification performance among all feature extraction techniques.