 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Impact of Partial Sums on Interconnect Bandwidth and Memory Accesses in a DNN Accelerator
Paper and Code
Nov 02, 2020

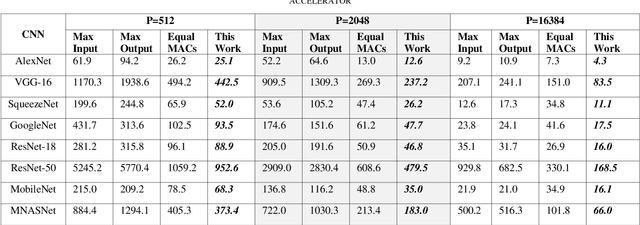

Dedicated accelerators are being designed to address the huge resource requirement of the deep neural network (DNN) applications. The power, performance and area (PPA) constraints limit the number of MACs available in these accelerators. The convolution layers which require huge number of MACs are often partitioned into multiple iterative sub-tasks. This puts huge pressure on the available system resources such as interconnect and memory bandwidth. The optimal partitioning of the feature maps for these sub-tasks can reduce the bandwidth requirement substantially. Some accelerators avoid off-chip or interconnect transfers by implementing local memories; however, the memory accesses are still performed and a reduced bandwidth can help in saving power in such architectures. In this paper, we propose a first order analytical method to partition the feature maps for optimal bandwidth and evaluate the impact of such partitioning on the bandwidth. This bandwidth can be saved by designing an active memory controller which can perform basic arithmetic operations. It is shown that the optimal partitioning and active memory controller can achieve up to 40% bandwidth reduction.