 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGender Representation in Open Source Speech Resources
Mar 18, 2020
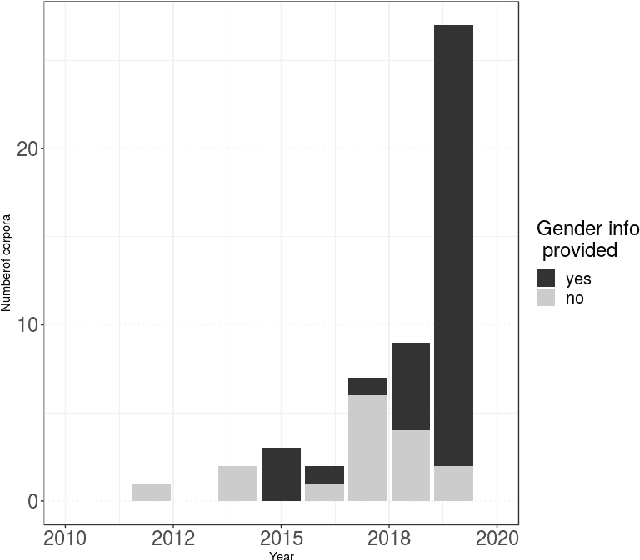

With the rise of artificial intelligence (AI) and the growing use of deep-learning architectures, the question of ethics, transparency and fairness of AI systems has become a central concern within the research community. We address transparency and fairness in spoken language systems by proposing a study about gender representation in speech resources available through the Open Speech and Language Resource platform. We show that finding gender information in open source corpora is not straightforward and that gender balance depends on other corpus characteristics (elicited/non elicited speech, low/high resource language, speech task targeted). The paper ends with recommendations about metadata and gender information for researchers in order to assure better transparency of the speech systems built using such corpora.
Gender Representation in French Broadcast Corpora and Its Impact on ASR Performance
Aug 23, 2019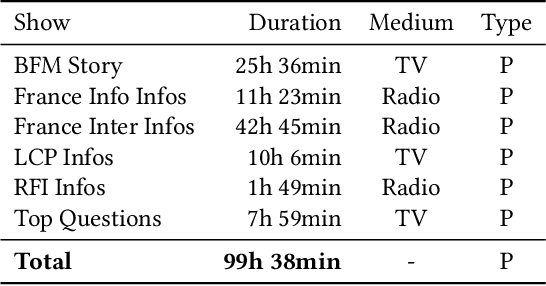
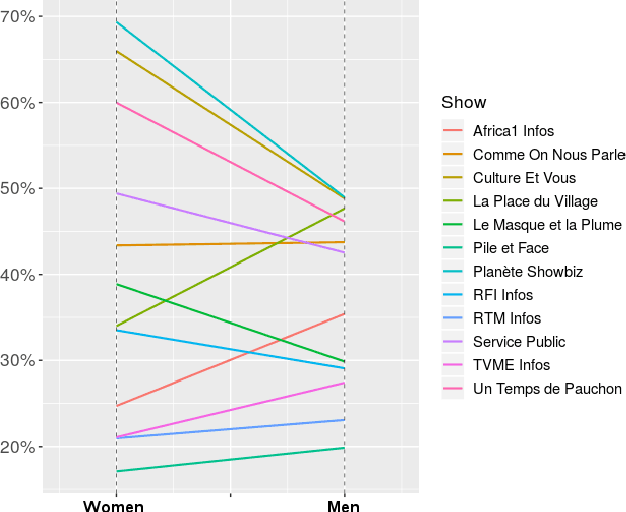


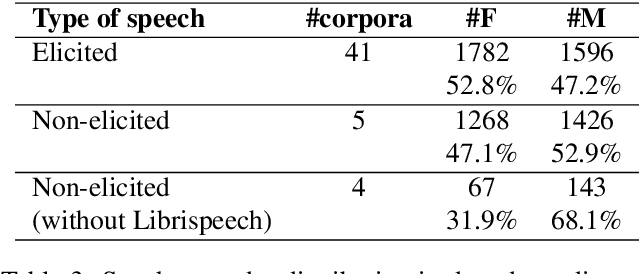
This paper analyzes the gender representation in four major corpora of French broadcast. These corpora being widely used within the speech processing community, they are a primary material for training automatic speech recognition (ASR) systems. As gender bias has been highlighted in numerous natural language processing (NLP) applications, we study the impact of the gender imbalance in TV and radio broadcast on the performance of an ASR system. This analysis shows that women are under-represented in our data in terms of speakers and speech turns. We introduce the notion of speaker role to refine our analysis and find that women are even fewer within the Anchor category corresponding to prominent speakers. The disparity of available data for both gender causes performance to decrease on women. However this global trend can be counterbalanced for speaker who are used to speak in the media when sufficient amount of data is available.
MaSS: A Large and Clean Multilingual Corpus of Sentence-aligned Spoken Utterances Extracted from the Bible
Aug 01, 2019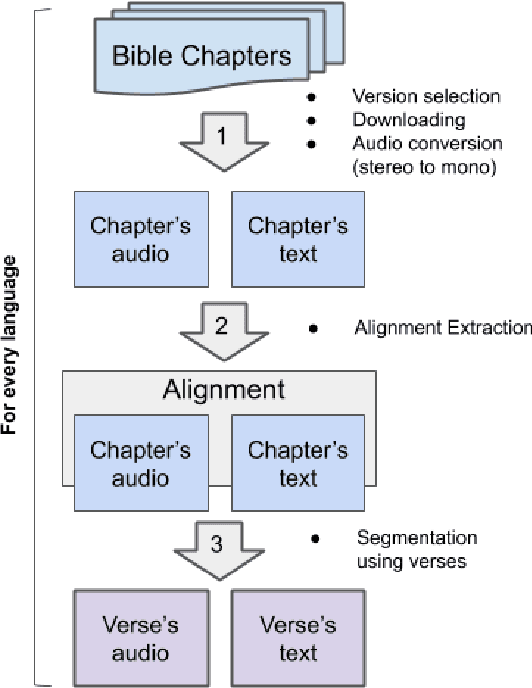

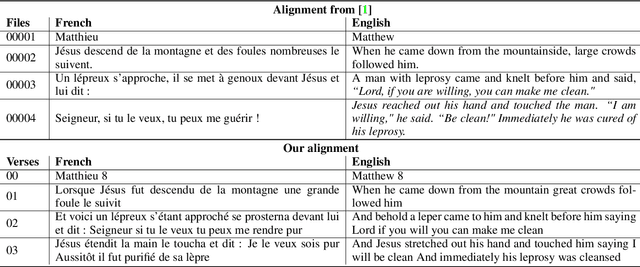
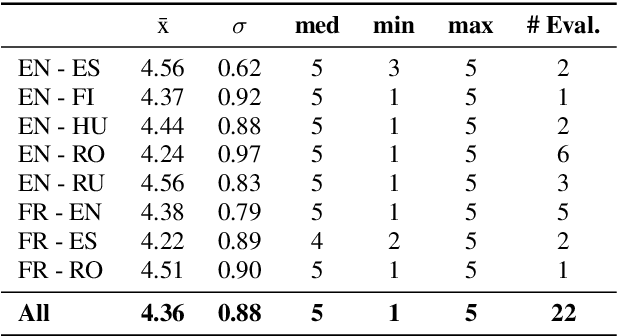
The CMU Wilderness Multilingual Speech Dataset is a newly published multilingual speech dataset based on recorded readings of the New Testament. It provides data to build Automatic Speech Recognition (ASR) and Text-to-Speech (TTS) models for potentially 700 languages. However, the fact that the source content (the Bible), is the same for all the languages is not exploited to date. Therefore, this article proposes to add multilingual links between speech segments in different languages, and shares a large and clean dataset of 8,130 para-lel spoken utterances across 8 languages (56 language pairs).We name this corpus MaSS (Multilingual corpus of Sentence-aligned Spoken utterances). The covered languages (Basque, English, Finnish, French, Hungarian, Romanian, Russian and Spanish) allow researches on speech-to-speech alignment as well as on translation for syntactically divergent language pairs. The quality of the final corpus is attested by human evaluation performed on a corpus subset (100 utterances, 8 language pairs). Lastly, we showcase the usefulness of the final product on a bilingual speech retrieval task.