 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaSS: A Large and Clean Multilingual Corpus of Sentence-aligned Spoken Utterances Extracted from the Bible
Paper and Code
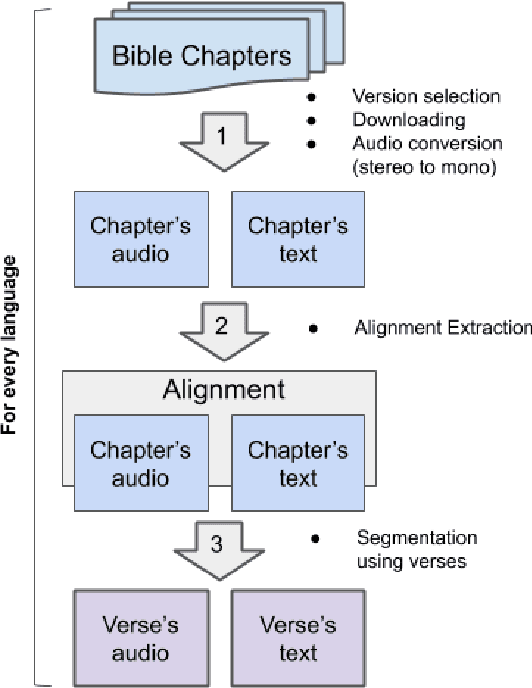

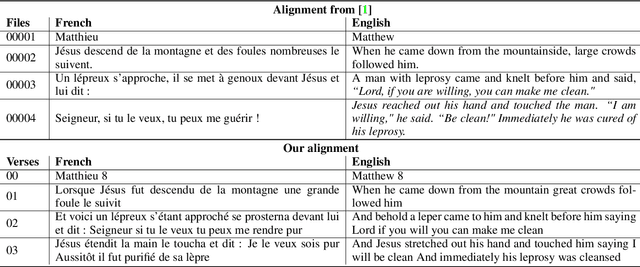
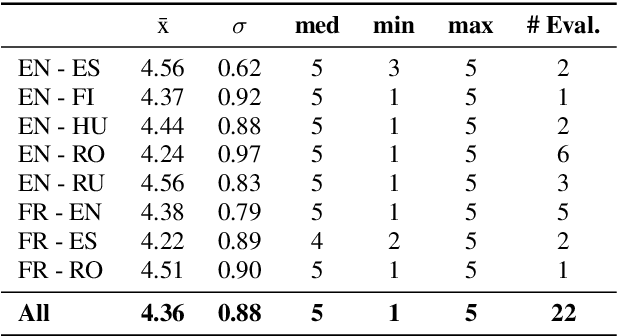
The CMU Wilderness Multilingual Speech Dataset is a newly published multilingual speech dataset based on recorded readings of the New Testament. It provides data to build Automatic Speech Recognition (ASR) and Text-to-Speech (TTS) models for potentially 700 languages. However, the fact that the source content (the Bible), is the same for all the languages is not exploited to date. Therefore, this article proposes to add multilingual links between speech segments in different languages, and shares a large and clean dataset of 8,130 para-lel spoken utterances across 8 languages (56 language pairs).We name this corpus MaSS (Multilingual corpus of Sentence-aligned Spoken utterances). The covered languages (Basque, English, Finnish, French, Hungarian, Romanian, Russian and Spanish) allow researches on speech-to-speech alignment as well as on translation for syntactically divergent language pairs. The quality of the final corpus is attested by human evaluation performed on a corpus subset (100 utterances, 8 language pairs). Lastly, we showcase the usefulness of the final product on a bilingual speech retrieval task.