 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlowNet-PET: Unsupervised Learning to Perform Respiratory Motion Correction in PET Imaging
May 27, 2022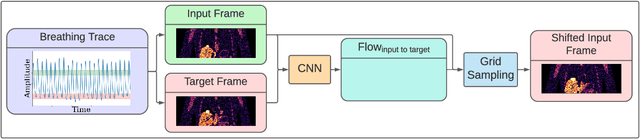
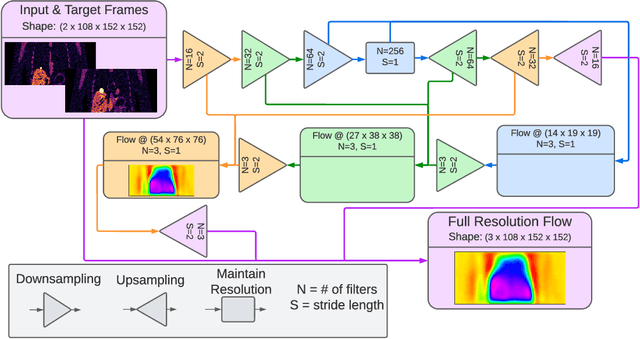
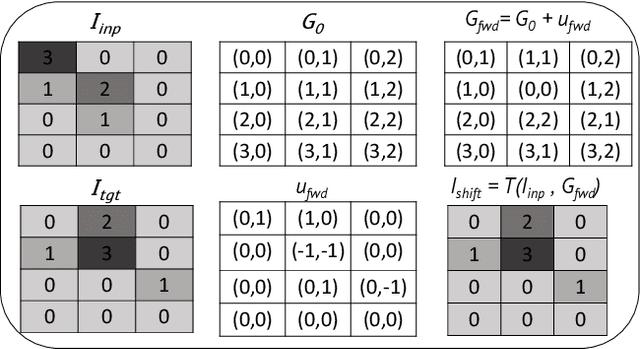
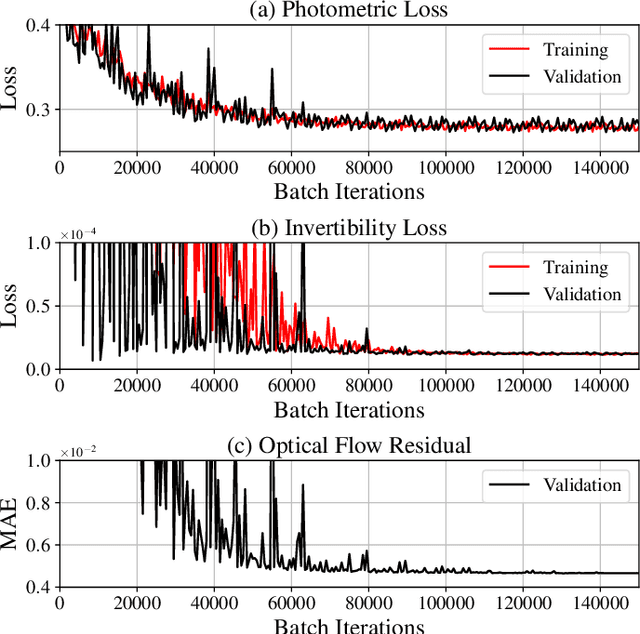
To correct for breathing motion in PET imaging, an interpretable and unsupervised deep learning technique, FlowNet-PET, was constructed. The network was trained to predict the optical flow between two PET frames from different breathing amplitude ranges. As a result, the trained model groups different retrospectively-gated PET images together into a motion-corrected single bin, providing a final image with similar counting statistics as a non-gated image, but without the blurring effects that were initially observed. As a proof-of-concept, FlowNet-PET was applied to anthropomorphic digital phantom data, which provided the possibility to design robust metrics to quantify the corrections. When comparing the predicted optical flows to the ground truths, the median absolute error was found to be smaller than the pixel and slice widths, even for the phantom with a diaphragm movement of 21 mm. The improvements were illustrated by comparing against images without motion and computing the intersection over union (IoU) of the tumors as well as the enclosed activity and coefficient of variation (CoV) within the no-motion tumor volume before and after the corrections were applied. The average relative improvements provided by the network were 54%, 90%, and 76% for the IoU, total activity, and CoV, respectively. The results were then compared against the conventional retrospective phase binning approach. FlowNet-PET achieved similar results as retrospective binning, but only required one sixth of the scan duration. The code and data used for training and analysis has been made publicly available (https://github.com/teaghan/FlowNet_PET).
Reducing the Human Effort in Developing PET-CT Registration
Nov 25, 2019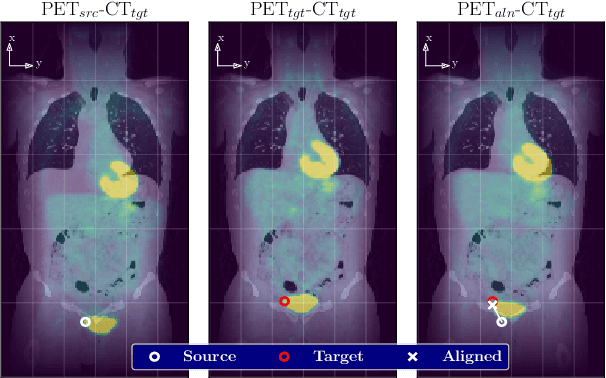

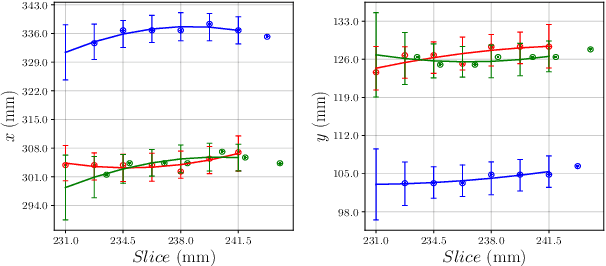
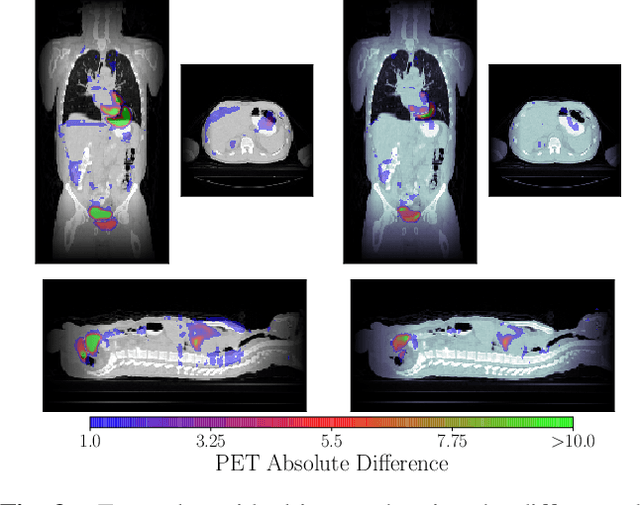
We aim to reduce the tedious nature of developing and evaluating methods for aligning PET-CT scans from multiple patient visits. Current methods for registration rely on correspondences that are created manually by medical experts with 3D manipulation, or assisted alignments done by utilizing mutual information across CT scans that may not be consistent when transferred to the PET images. Instead, we propose to label multiple key points across several 2D slices, which we then fit a key curve to. This removes the need for creating manual alignments in 3D and makes the labelling process easier. We use these key curves to define an error metric for the alignments that can be computed efficiently. While our metric is non-differentiable, we further show that we can utilize it during the training of our deep model via a novel method. Specifically, instead of relying on detailed geometric labels -- e.g., manual 3D alignments -- we use synthetically generated deformations of real data. To incorporate robustness to changes that occur between visits other than geometric changes, we enforce consistency across visits in the deep network's internal representations. We demonstrate the potential of our method via qualitative and quantitative experiments.