 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInteractive Machine Teaching by Labeling Rules and Instances
Sep 08, 2024Weakly supervised learning aims to reduce the cost of labeling data by using expert-designed labeling rules. However, existing methods require experts to design effective rules in a single shot, which is difficult in the absence of proper guidance and tooling. Therefore, it is still an open question whether experts should spend their limited time writing rules or instead providing instance labels via active learning. In this paper, we investigate how to exploit an expert's limited time to create effective supervision. First, to develop practical guidelines for rule creation, we conduct an exploratory analysis of diverse collections of existing expert-designed rules and find that rule precision is more important than coverage across datasets. Second, we compare rule creation to individual instance labeling via active learning and demonstrate the importance of both across 6 datasets. Third, we propose an interactive learning framework, INTERVAL, that achieves efficiency by automatically extracting candidate rules based on rich patterns (e.g., by prompting a language model), and effectiveness by soliciting expert feedback on both candidate rules and individual instances. Across 6 datasets, INTERVAL outperforms state-of-the-art weakly supervised approaches by 7% in F1. Furthermore, it requires as few as 10 queries for expert feedback to reach F1 values that existing active learning methods cannot match even with 100 queries.
Seasonality Patterns in 311-Reported Foodborne Illness Cases and Machine Learning-Identified Indications of Foodborne Illnesses from Yelp Reviews, New York City, 2022-2023
May 09, 2024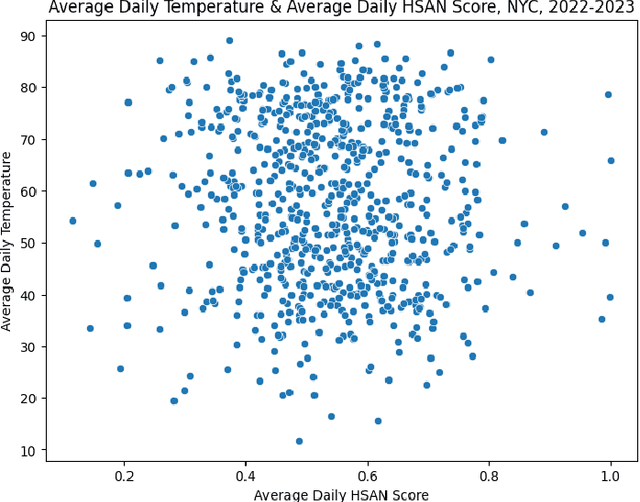
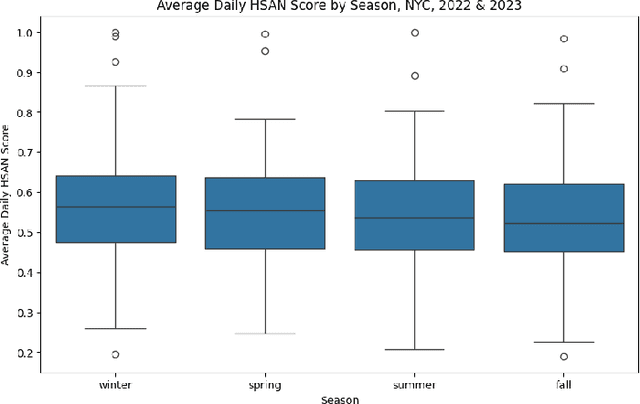
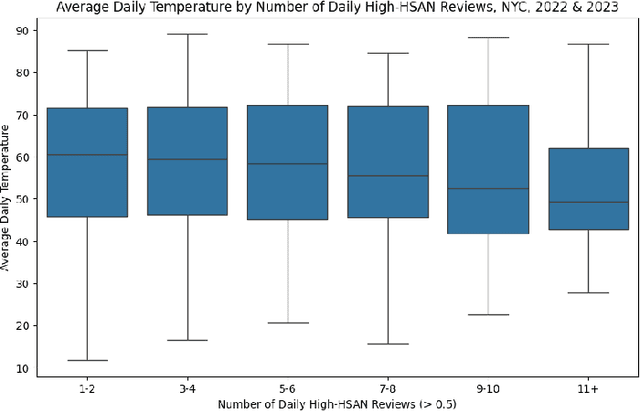
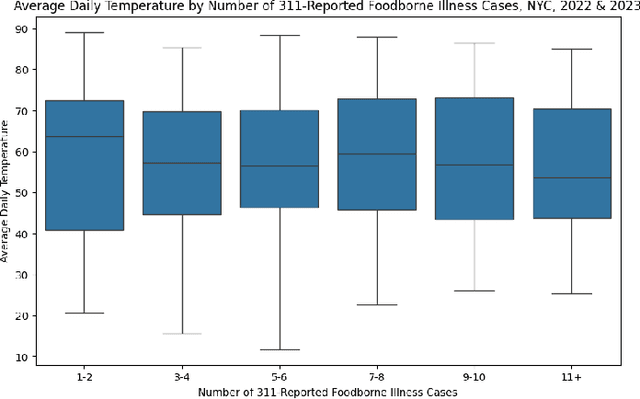
Restaurants are critical venues at which to investigate foodborne illness outbreaks due to shared sourcing, preparation, and distribution of foods. Formal channels to report illness after food consumption, such as 311, New York City's non-emergency municipal service platform, are underutilized. Given this, online social media platforms serve as abundant sources of user-generated content that provide critical insights into the needs of individuals and populations. We extracted restaurant reviews and metadata from Yelp to identify potential outbreaks of foodborne illness in connection with consuming food from restaurants. Because the prevalence of foodborne illnesses may increase in warmer months as higher temperatures breed more favorable conditions for bacterial growth, we aimed to identify seasonal patterns in foodborne illness reports from 311 and identify seasonal patterns of foodborne illness from Yelp reviews for New York City restaurants using a Hierarchical Sigmoid Attention Network (HSAN). We found no evidence of significant bivariate associations between any variables of interest. Given the inherent limitations of relying solely on user-generated data for public health insights, it is imperative to complement these sources with other data streams and insights from subject matter experts. Future investigations should involve conducting these analyses at more granular spatial and temporal scales to explore the presence of such differences or associations.
What is a good question? Task-oriented asking with fact-level masking
Oct 17, 2023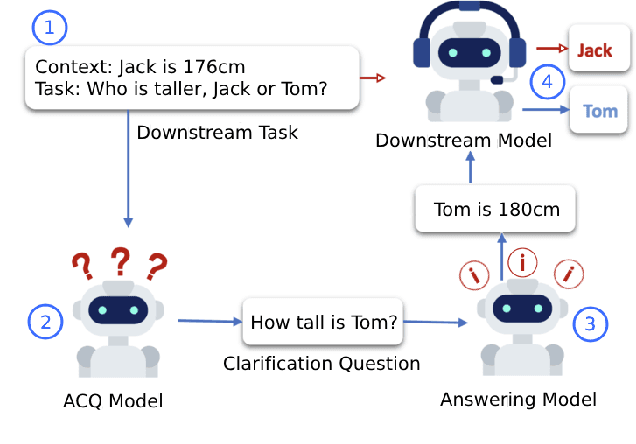
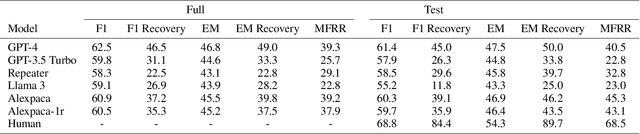

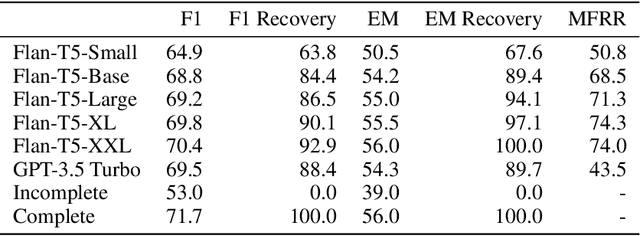
Asking questions is an important element of real-life collaboration on reasoning tasks like question answering. For example, a legal assistant chatbot may be unable to make accurate recommendations without specific information on the user's circumstances. However, large language models are usually deployed to solve reasoning tasks directly without asking follow-up questions to the user or third parties. We term this problem task-oriented asking (TOA). Zero-shot chat models can perform TOA, but their training is primarily based on next-token prediction rather than whether questions contribute to successful collaboration. To enable the training and evaluation of TOA models, we present a definition and framework for natural language task-oriented asking, the problem of generating questions that result in answers useful for a reasoning task. We also present fact-level masking (FLM), a procedure for converting natural language datasets into self-supervised TOA datasets by omitting particular critical facts. Finally, we generate a TOA dataset from the HotpotQA dataset using FLM and evaluate several zero-shot language models on it. Our experiments show that current zero-shot models struggle to ask questions that retrieve useful information, as compared to human annotators. These results demonstrate an opportunity to use FLM datasets and the TOA framework to train and evaluate better TOA models.
Detecting Foodborne Illness Complaints in Multiple Languages Using English Annotations Only
Oct 11, 2020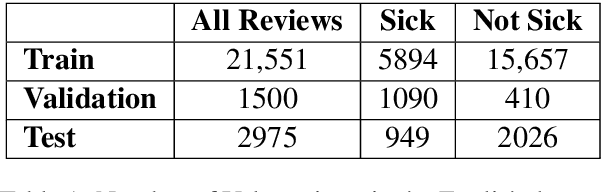
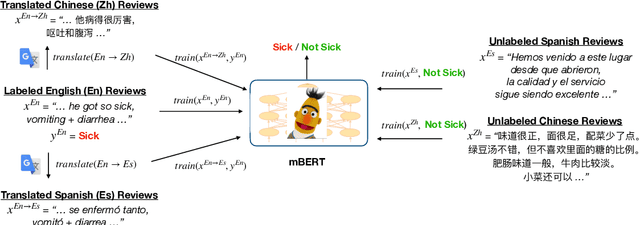
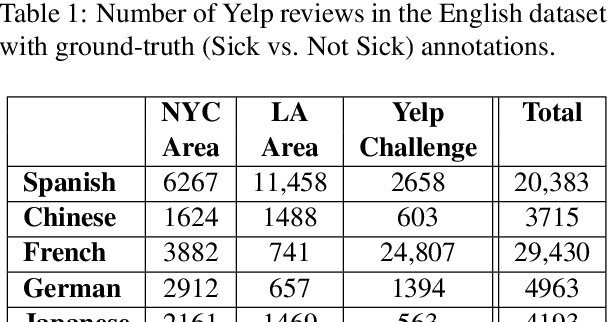
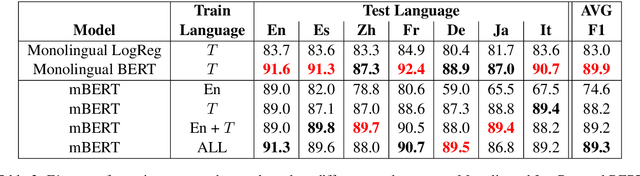
Health departments have been deploying text classification systems for the early detection of foodborne illness complaints in social media documents such as Yelp restaurant reviews. Current systems have been successfully applied for documents in English and, as a result, a promising direction is to increase coverage and recall by considering documents in additional languages, such as Spanish or Chinese. Training previous systems for more languages, however, would be expensive, as it would require the manual annotation of many documents for each new target language. To address this challenge, we consider cross-lingual learning and train multilingual classifiers using only the annotations for English-language reviews. Recent zero-shot approaches based on pre-trained multi-lingual BERT (mBERT) have been shown to effectively align languages for aspects such as sentiment. Interestingly, we show that those approaches are less effective for capturing the nuances of foodborne illness, our public health application of interest. To improve performance without extra annotations, we create artificial training documents in the target language through machine translation and train mBERT jointly for the source (English) and target language. Furthermore, we show that translating labeled documents to multiple languages leads to additional performance improvements for some target languages. We demonstrate the benefits of our approach through extensive experiments with Yelp restaurant reviews in seven languages. Our classifiers identify foodborne illness complaints in multilingual reviews from the Yelp Challenge dataset, which highlights the potential of our general approach for deployment in health departments.
Cross-Lingual Text Classification with Minimal Resources by Transferring a Sparse Teacher
Oct 06, 2020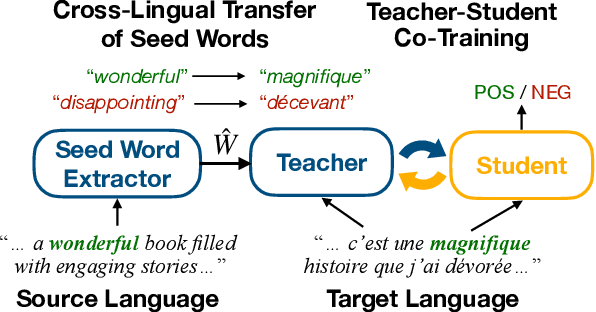
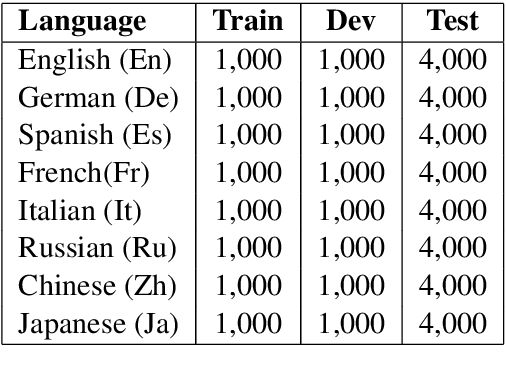
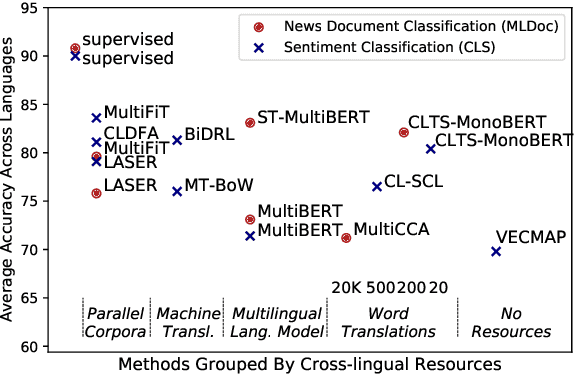
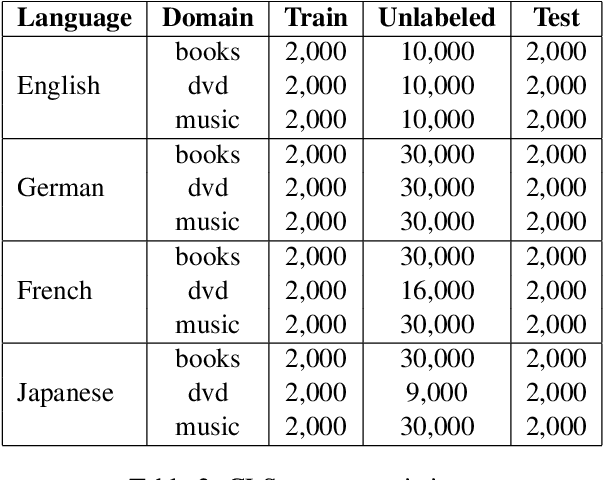
Cross-lingual text classification alleviates the need for manually labeled documents in a target language by leveraging labeled documents from other languages. Existing approaches for transferring supervision across languages require expensive cross-lingual resources, such as parallel corpora, while less expensive cross-lingual representation learning approaches train classifiers without target labeled documents. In this work, we propose a cross-lingual teacher-student method, CLTS, that generates "weak" supervision in the target language using minimal cross-lingual resources, in the form of a small number of word translations. Given a limited translation budget, CLTS extracts and transfers only the most important task-specific seed words across languages and initializes a teacher classifier based on the translated seed words. Then, CLTS iteratively trains a more powerful student that also exploits the context of the seed words in unlabeled target documents and outperforms the teacher. CLTS is simple and surprisingly effective in 18 diverse languages: by transferring just 20 seed words, even a bag-of-words logistic regression student outperforms state-of-the-art cross-lingual methods (e.g., based on multilingual BERT). Moreover, CLTS can accommodate any type of student classifier: leveraging a monolingual BERT student leads to further improvements and outperforms even more expensive approaches by up to 12% in accuracy. Finally, CLTS addresses emerging tasks in low-resource languages using just a small number of word translations.
Weakly Supervised Attention Networks for Fine-Grained Opinion Mining and Public Health
Sep 30, 2019
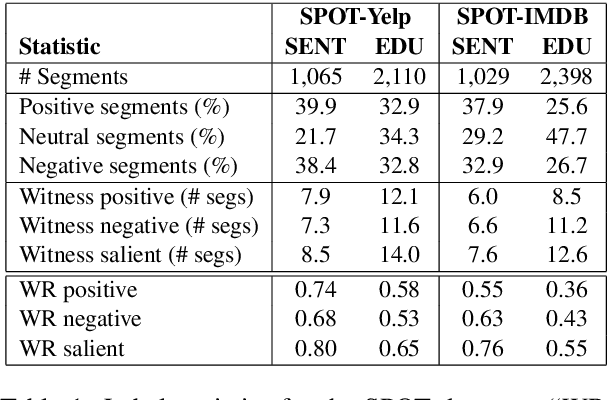
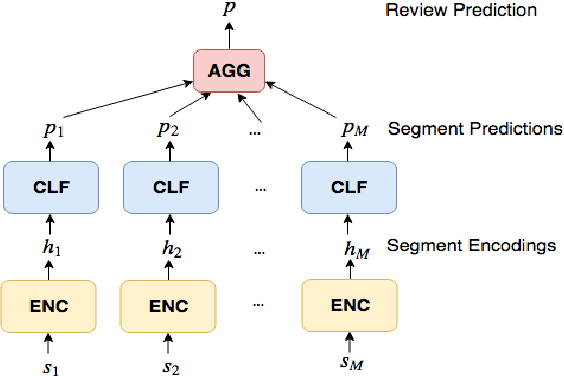
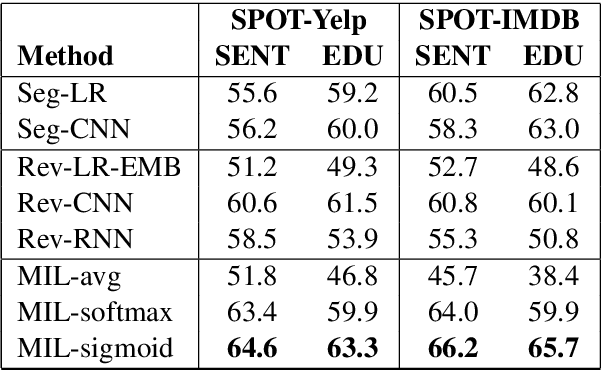
In many review classification applications, a fine-grained analysis of the reviews is desirable, because different segments (e.g., sentences) of a review may focus on different aspects of the entity in question. However, training supervised models for segment-level classification requires segment labels, which may be more difficult or expensive to obtain than review labels. In this paper, we employ Multiple Instance Learning (MIL) and use only weak supervision in the form of a single label per review. First, we show that when inappropriate MIL aggregation functions are used, then MIL-based networks are outperformed by simpler baselines. Second, we propose a new aggregation function based on the sigmoid attention mechanism and show that our proposed model outperforms the state-of-the-art models for segment-level sentiment classification (by up to 9.8% in F1). Finally, we highlight the importance of fine-grained predictions in an important public-health application: finding actionable reports of foodborne illness. We show that our model achieves 48.6% higher recall compared to previous models, thus increasing the chance of identifying previously unknown foodborne outbreaks.
Leveraging Just a Few Keywords for Fine-Grained Aspect Detection Through Weakly Supervised Co-Training
Sep 01, 2019

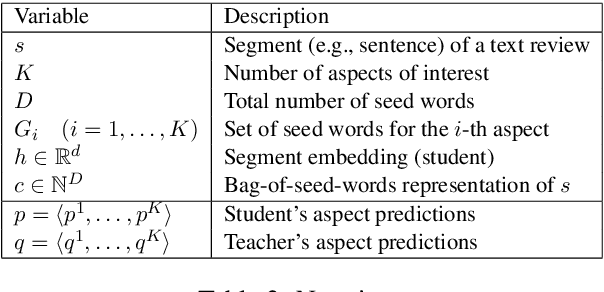
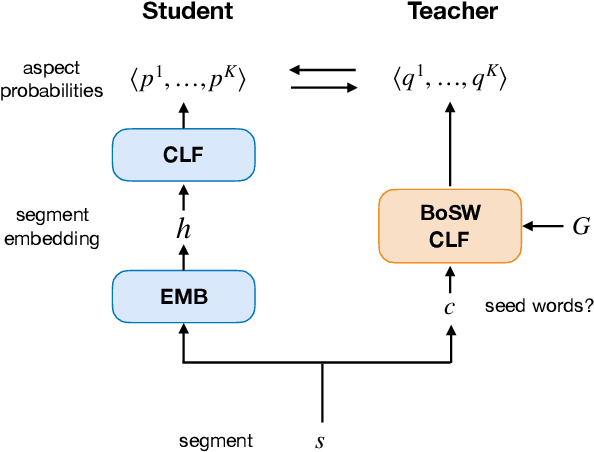
User-generated reviews can be decomposed into fine-grained segments (e.g., sentences, clauses), each evaluating a different aspect of the principal entity (e.g., price, quality, appearance). Automatically detecting these aspects can be useful for both users and downstream opinion mining applications. Current supervised approaches for learning aspect classifiers require many fine-grained aspect labels, which are labor-intensive to obtain. And, unfortunately, unsupervised topic models often fail to capture the aspects of interest. In this work, we consider weakly supervised approaches for training aspect classifiers that only require the user to provide a small set of seed words (i.e., weakly positive indicators) for the aspects of interest. First, we show that current weakly supervised approaches do not effectively leverage the predictive power of seed words for aspect detection. Next, we propose a student-teacher approach that effectively leverages seed words in a bag-of-words classifier (teacher); in turn, we use the teacher to train a second model (student) that is potentially more powerful (e.g., a neural network that uses pre-trained word embeddings). Finally, we show that iterative co-training can be used to cope with noisy seed words, leading to both improved teacher and student models. Our proposed approach consistently outperforms previous weakly supervised approaches (by 14.1 absolute F1 points on average) in six different domains of product reviews and six multilingual datasets of restaurant reviews.