 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProgram Synthesis Dialog Agents for Interactive Decision-Making
Feb 26, 2025Many real-world eligibility problems, ranging from medical diagnosis to tax planning, can be mapped to decision problems expressed in natural language, wherein a model must make a binary choice based on user features. Large-scale domains such as legal codes or frequently updated funding opportunities render human annotation (e.g., web forms or decision trees) impractical, highlighting the need for agents that can automatically assist in decision-making. Since relevant information is often only known to the user, it is crucial that these agents ask the right questions. As agents determine when to terminate a conversation, they face a trade-off between accuracy and the number of questions asked, a key metric for both user experience and cost. To evaluate this task, we propose BeNYfits, a new benchmark for determining user eligibility for multiple overlapping social benefits opportunities through interactive decision-making. Our experiments show that current language models struggle with frequent hallucinations, with GPT-4o scoring only 35.7 F1 using a ReAct-style chain-of-thought. To address this, we introduce ProADA, a novel approach that leverages program synthesis to assist in decision-making by mapping dialog planning to a code generation problem and using gaps in structured data to determine the best next action. Our agent, ProADA, improves the F1 score to 55.6 while maintaining nearly the same number of dialog turns.
What is a good question? Task-oriented asking with fact-level masking
Oct 17, 2023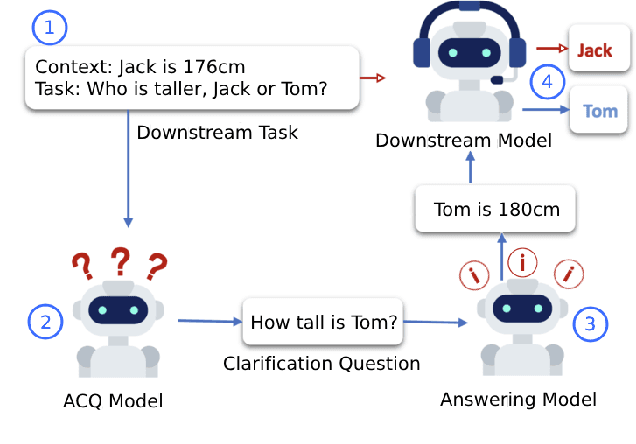
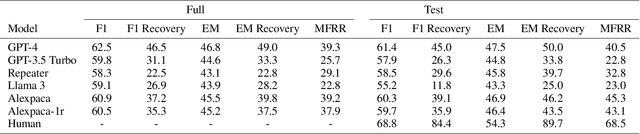

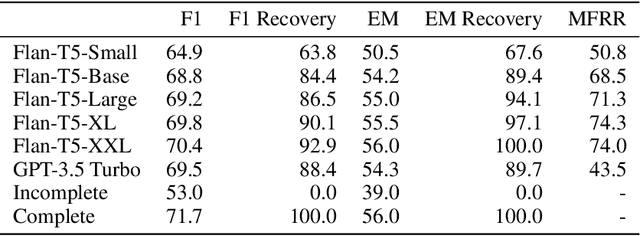
Asking questions is an important element of real-life collaboration on reasoning tasks like question answering. For example, a legal assistant chatbot may be unable to make accurate recommendations without specific information on the user's circumstances. However, large language models are usually deployed to solve reasoning tasks directly without asking follow-up questions to the user or third parties. We term this problem task-oriented asking (TOA). Zero-shot chat models can perform TOA, but their training is primarily based on next-token prediction rather than whether questions contribute to successful collaboration. To enable the training and evaluation of TOA models, we present a definition and framework for natural language task-oriented asking, the problem of generating questions that result in answers useful for a reasoning task. We also present fact-level masking (FLM), a procedure for converting natural language datasets into self-supervised TOA datasets by omitting particular critical facts. Finally, we generate a TOA dataset from the HotpotQA dataset using FLM and evaluate several zero-shot language models on it. Our experiments show that current zero-shot models struggle to ask questions that retrieve useful information, as compared to human annotators. These results demonstrate an opportunity to use FLM datasets and the TOA framework to train and evaluate better TOA models.