 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Lingual Text Classification with Minimal Resources by Transferring a Sparse Teacher
Paper and Code
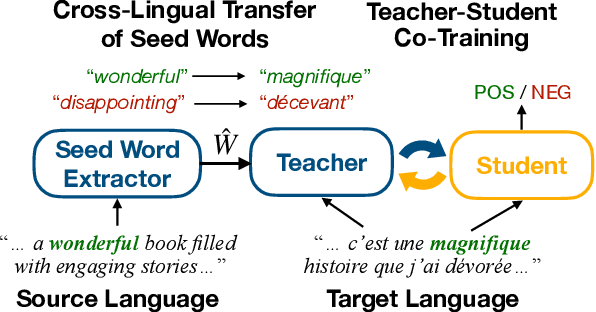
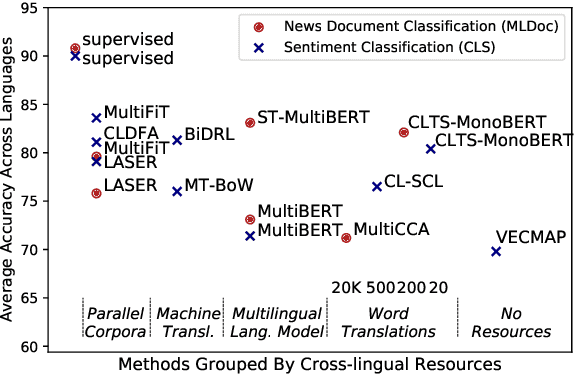
Cross-lingual text classification alleviates the need for manually labeled documents in a target language by leveraging labeled documents from other languages. Existing approaches for transferring supervision across languages require expensive cross-lingual resources, such as parallel corpora, while less expensive cross-lingual representation learning approaches train classifiers without target labeled documents. In this work, we propose a cross-lingual teacher-student method, CLTS, that generates "weak" supervision in the target language using minimal cross-lingual resources, in the form of a small number of word translations. Given a limited translation budget, CLTS extracts and transfers only the most important task-specific seed words across languages and initializes a teacher classifier based on the translated seed words. Then, CLTS iteratively trains a more powerful student that also exploits the context of the seed words in unlabeled target documents and outperforms the teacher. CLTS is simple and surprisingly effective in 18 diverse languages: by transferring just 20 seed words, even a bag-of-words logistic regression student outperforms state-of-the-art cross-lingual methods (e.g., based on multilingual BERT). Moreover, CLTS can accommodate any type of student classifier: leveraging a monolingual BERT student leads to further improvements and outperforms even more expensive approaches by up to 12% in accuracy. Finally, CLTS addresses emerging tasks in low-resource languages using just a small number of word translations.