 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Vulnerability of Concept Erasure in Diffusion Models
Feb 24, 2025



The proliferation of text-to-image diffusion models has raised significant privacy and security concerns, particularly regarding the generation of copyrighted or harmful images. To address these issues, research on machine unlearning has developed various concept erasure methods, which aim to remove the effect of unwanted data through post-hoc training. However, we show these erasure techniques are vulnerable, where images of supposedly erased concepts can still be generated using adversarially crafted prompts. We introduce RECORD, a coordinate-descent-based algorithm that discovers prompts capable of eliciting the generation of erased content. We demonstrate that RECORD significantly beats the attack success rate of current state-of-the-art attack methods. Furthermore, our findings reveal that models subjected to concept erasure are more susceptible to adversarial attacks than previously anticipated, highlighting the urgency for more robust unlearning approaches. We open source all our code at https://github.com/LucasBeerens/RECORD
Deceptive Diffusion: Generating Synthetic Adversarial Examples
Jun 28, 2024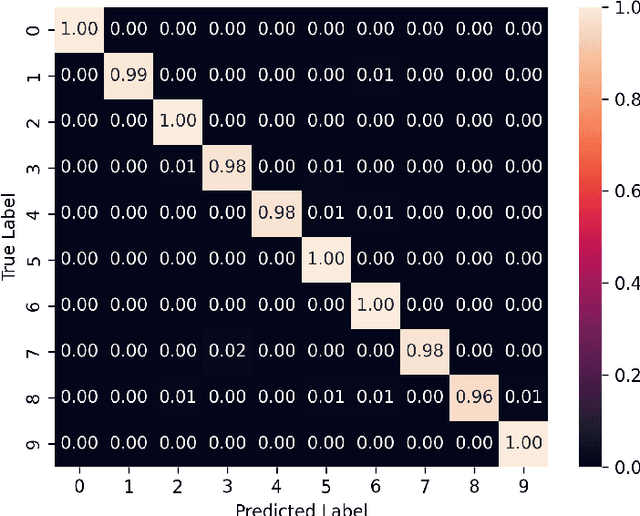
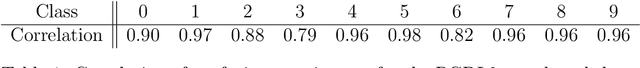
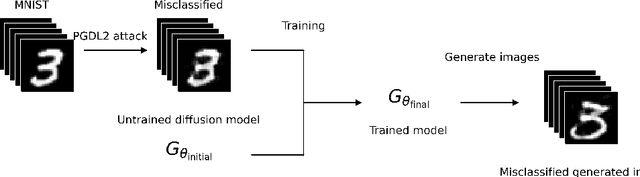
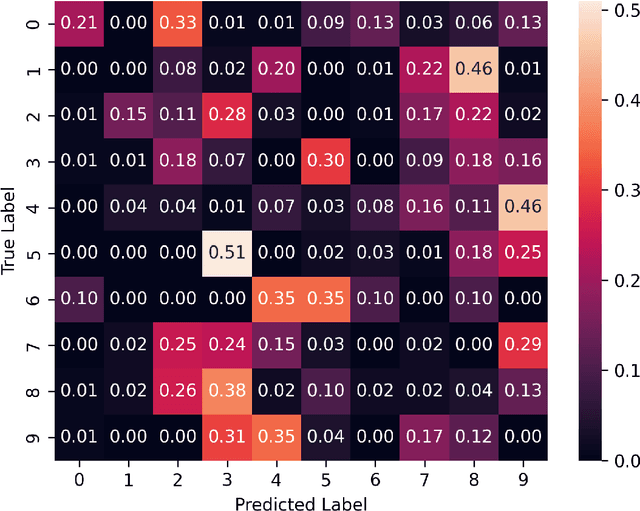
We introduce the concept of deceptive diffusion -- training a generative AI model to produce adversarial images. Whereas a traditional adversarial attack algorithm aims to perturb an existing image to induce a misclassificaton, the deceptive diffusion model can create an arbitrary number of new, misclassified images that are not directly associated with training or test images. Deceptive diffusion offers the possibility of strengthening defence algorithms by providing adversarial training data at scale, including types of misclassification that are otherwise difficult to find. In our experiments, we also investigate the effect of training on a partially attacked data set. This highlights a new type of vulnerability for generative diffusion models: if an attacker is able to stealthily poison a portion of the training data, then the resulting diffusion model will generate a similar proportion of misleading outputs.
Vulnerability Analysis of Transformer-based Optical Character Recognition to Adversarial Attacks
Nov 28, 2023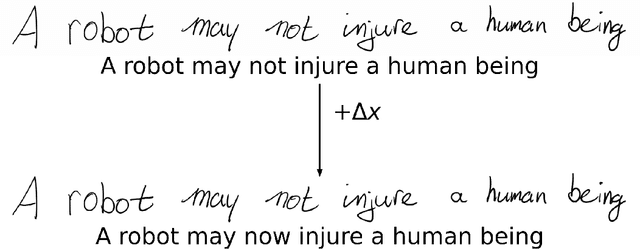
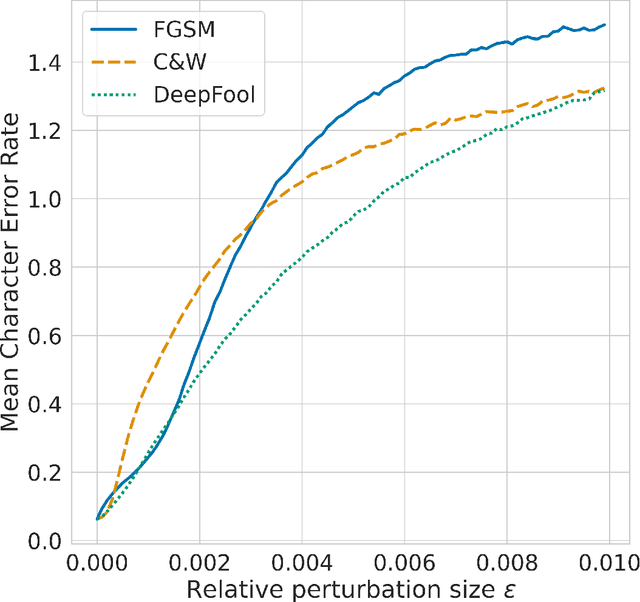
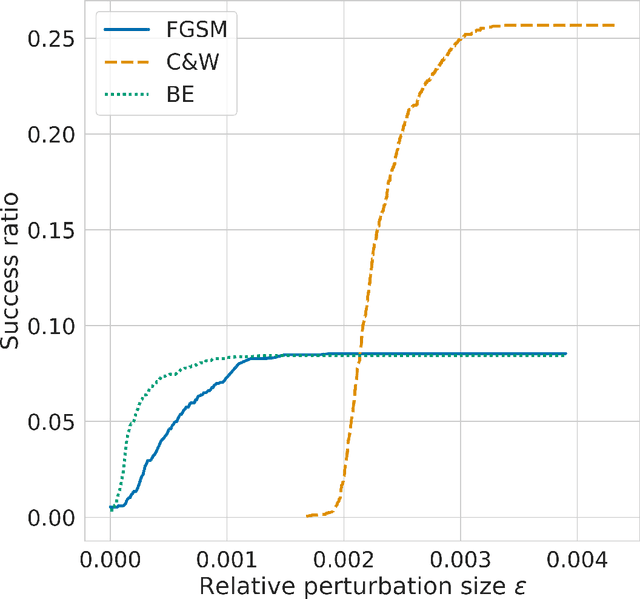
Recent advancements in Optical Character Recognition (OCR) have been driven by transformer-based models. OCR systems are critical in numerous high-stakes domains, yet their vulnerability to adversarial attack remains largely uncharted territory, raising concerns about security and compliance with emerging AI regulations. In this work we present a novel framework to assess the resilience of Transformer-based OCR (TrOCR) models. We develop and assess algorithms for both targeted and untargeted attacks. For the untargeted case, we measure the Character Error Rate (CER), while for the targeted case we use the success ratio. We find that TrOCR is highly vulnerable to untargeted attacks and somewhat less vulnerable to targeted attacks. On a benchmark handwriting data set, untargeted attacks can cause a CER of more than 1 without being noticeable to the eye. With a similar perturbation size, targeted attacks can lead to success rates of around $25\%$ -- here we attacked single tokens, requiring TrOCR to output the tenth most likely token from a large vocabulary.
Adversarial Ink: Componentwise Backward Error Attacks on Deep Learning
Jun 05, 2023
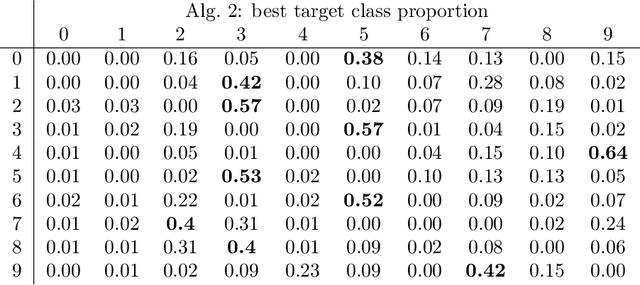
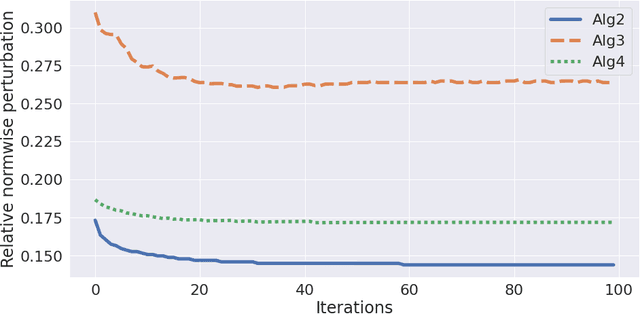
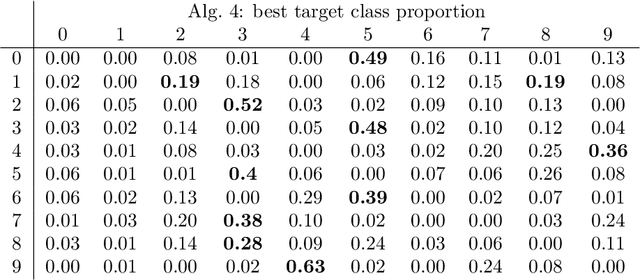
Deep neural networks are capable of state-of-the-art performance in many classification tasks. However, they are known to be vulnerable to adversarial attacks -- small perturbations to the input that lead to a change in classification. We address this issue from the perspective of backward error and condition number, concepts that have proved useful in numerical analysis. To do this, we build on the work of Beuzeville et al. (2021). In particular, we develop a new class of attack algorithms that use componentwise relative perturbations. Such attacks are highly relevant in the case of handwritten documents or printed texts where, for example, the classification of signatures, postcodes, dates or numerical quantities may be altered by changing only the ink consistency and not the background. This makes the perturbed images look natural to the naked eye. Such ``adversarial ink'' attacks therefore reveal a weakness that can have a serious impact on safety and security. We illustrate the new attacks on real data and contrast them with existing algorithms. We also study the use of a componentwise condition number to quantify vulnerability.